【ElasticSearch篇】--ElasticSearch从初识到安装和应用
一、前述
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,在企业中全文搜索时,特别常用。
二、常用概念
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。只需要在同一个网段之内启动多个es节点,就可以自动组成一个集群。默认情况下es会自动发现同一网段内的节点,自动组成集群。
shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
如果需要将数据落地到hadoop的hdfs需要先安装插件elasticsearch/elasticsearch-hadoop,然后再elasticsearch.yml配置
gateway: type: hdfsgateway: hdfs: uri: hdfs://localhost:9000
discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,如果你想,可以定义任意多的索引。
类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
文档(document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。 在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
三、安装教程
1、前提
只允许普通用户操作,不允许root用户
注意:因为elasticsearch有远程执行脚本的功能所以容易中木马病毒,所以不允许用root用户启动,root用户是起不来的,赋权限,用一般的用户启动
要配置network.host才能别的机器或者网卡访问,否则只能是127.0.0.1或者localhost访问,这里配置成自己的局域网ip
注意配置yml结尾的配置文件都需要冒号后面加空格才行
2、先要安装一个解压工具:
yum install unzip

3、不同节点间创建相同目录和用户
下载elasticsearch-2.0.1.tar.zip,不要用root解压,需要切换用户

root共同创建 es 目录(共享模式):
mkdir /opt/soft/es
3个节点同时添加(共享命令模式)用户并提供密码:
useradd sxt
echo sxt | passwd --stdin sxt
改变目录权限(共享命令模式):
chown sxt:sxt es
4、解压并配置
切换用户为sxt
注意配置yml结尾的配置文件都需要冒号后面加空格才行
使用sxt这个用户解压并进入es 目录的config配置目录修改配置文件config/elasticsearch.yml:注意:这个文件的所有行的:的后面,一定要有一个空格!

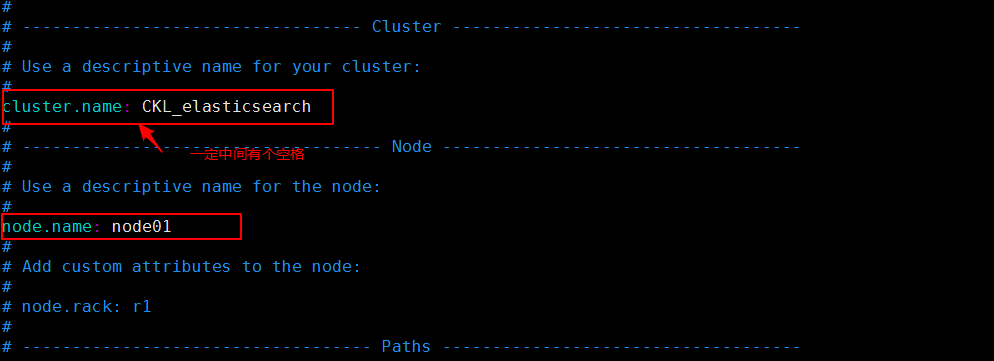
如果要配置集群需要两个节点上的elasticsearch配置的cluster.name相同,都启动可以自动组成集群,这里如果不改cluster.name则默认是cluster.name=elasticsearch,
nodename随意取但是集群内的各节点不能相同。
主机和端口
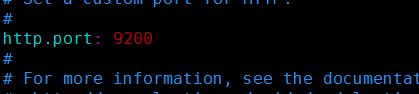
添加防脑裂配置: 如果不配不知道具体数量,不好控制脑裂
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["192.168.133.101","192.168.133.102", "192.168.133.103"]
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
完整配置如下:
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please see the documentation for further information on configuration options:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration.html>
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: CKL_elasticsearch
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node01
#
# Add custom attributes to the node:
#
# node.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
# path.data: /path/to/data
#
# Path to log files:
#
# path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
# bootstrap.mlockall: true
#
# Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory
# available on the system and that the owner of the process is allowed to use this limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
# network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html>
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1):
#
# discovery.zen.minimum_master_nodes: 3
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html>
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
# gateway.recover_after_nodes: 3
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-gateway.html>
#
# ---------------------------------- Various -----------------------------------
#
# Disable starting multiple nodes on a single system:
#
# node.max_local_storage_nodes: 1
#
# Require explicit names when deleting indices:
#
# action.destructive_requires_name: true
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["192.168.31.101","192.168.133.102", "192.168.133.103"]
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
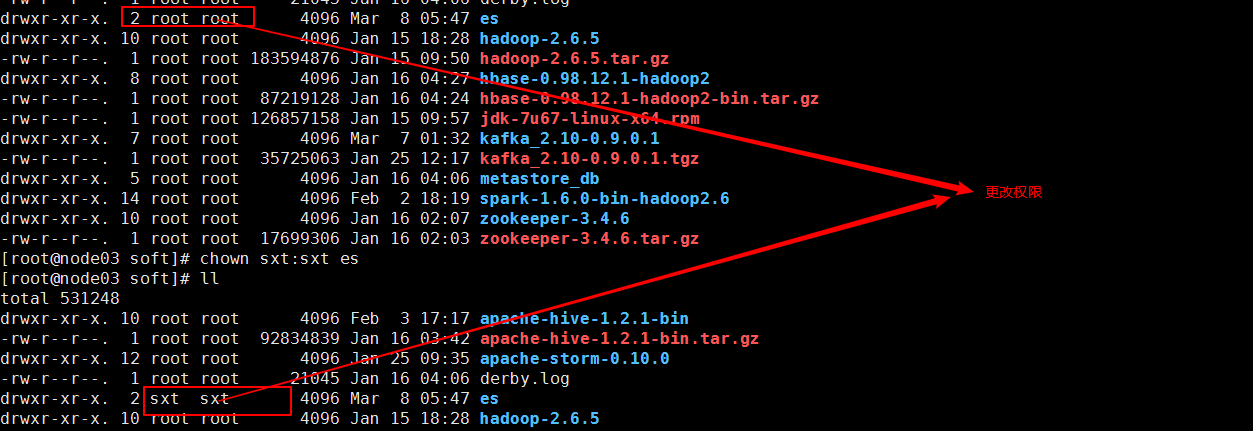
5、分发节点并更改不同节点的es配置中namenode名称
把配置和文件都分发给别的节点,注意也必须以普通用户身份:
如果你是用root分发,那边会以root身份写入磁盘系统。
以sxt用户身份登录

如果出现如下问题,是因为对方节点目录不是sxt用户 用chown sxt:sxt es更改即可

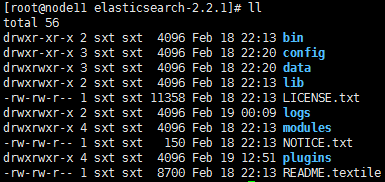
6、安装插件
1、es 是rest方式,采用Jason格式,可读性不强,添加head插件,以图表方式显示:
es目录原来没有plugins,从互联网下载:
bin/plugin install mobz/elasticsearch-head

注意:从解压es到操作这个包都必须是普通用户,因为这个过程会创建plugins目录,如果是你root创建,这个就成了root用户权限控制了,会有问题
下载后:
2、以上没有成功则使用第二种方式安装
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
mv elasticsearch-head-master /opt/soft/es/elasticsearch-2.2.1/plugins下面
然后将整个目录移动到Es的plugins文件下
测试插件效果
http://ip:9200/_plugin/head
http://192.168.31.101:9200/_plugin/head?pretty
【ElasticSearch篇】--ElasticSearch从初识到安装和应用的更多相关文章
- 【ElasticSearch+NetCore 第一篇】在Windows上安装部署ElasticSearch和ElasticSearch-head
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Apach ...
- ElasticSearch从不懂到会用1—安装篇
连续加班近一个多月,项目终于告一段落了,也腾出时间写一写项目中用到的东西.在这个项目中,我负责的主要是多种业务场景下的数据查询和搜索,其中搜索用到了ElasticSearch搜索引擎.下面主要围绕El ...
- 【elasticsearch】(3)centos7 安装中文分词插件elasticsearch-analyzer-ik
前言 elasticsearch(下面简称ES,安装ES点击这里)的自带standard分词只能把汉语分割成一个个字,而不能分词.分段,这就是我们需要分析器ik的地方了. 一.下载ik的相应版本 查看 ...
- Elasticsearch 学习(二):安装和使用
一.安装 安装 Elasticsearch 之前,需要先安装 Java,并配置好 Java 环境变量. 安装好 Java 环境后,进入 Elasticsearch 官网下载安装包. 解压安装包,进入解 ...
- ELK学习记录二 :elasticsearch、logstash及kibana的安装与配置
注意事项: 1.ELK版本要求5.X以上,本人使用版本:elasticsearch-6.0.0.kibana-6.0.0-linux-x86_64.logstash-6.0.0.tar 2.Elast ...
- ElasticSearch 5.0及head插件安装
一.elasticsearch安装配置 1.官网下载源码包 https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.0 ...
- 面试小结之Elasticsearch篇(转)
最近面试一些公司,被问到的关于Elasticsearch和搜索引擎相关的问题,以及自己总结的回答. Elasticsearch是如何实现Master选举的? Elasticsearch的选主是ZenD ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - ElasticSearch
文章目录 1. 版本须知 2. 环境依赖 3. 数据源 3.1. 方案一 使用 Spring Boot 默认配置 3.2. 方案二 手动创建 4. 业务操作5. 总结 4.1. 实体对象 4.2. D ...
- elasticsearch 5.x 系列之一 开始安装啦
以下是镇楼用的,各路退让,我要吹liubi 了 // // _oo0oo_ // o8888888o // 88" . "88 // (| -_- |) // 0\ = /0 // ...
- elasticsearch 中文分词(elasticsearch-analysis-ik)安装
elasticsearch 中文分词(elasticsearch-analysis-ik)安装 下载最新的发布版本 https://github.com/medcl/elasticsearch-ana ...
随机推荐
- python日期格式化操作
1.将字符串的时间转换为时间戳 方法: a = "2013-10-10 23:40:00" #将其转换为时间数组 import time timeArray = time.strp ...
- attr和prop的区别以及在企业开发中应该如何抉择
attr和prop有很多相同的地方,比如都可以操作标签的属性节点,而且获取的时候都只可以获取到相同节点的第一个,例如这样: $('span').attr('class');和$('span').pro ...
- BZOJ_3514_Codechef MARCH14 GERALD07加强版_主席树+LCT
BZOJ_3514_Codechef MARCH14 GERALD07加强版_主席树+LCT Description N个点M条边的无向图,询问保留图中编号在[l,r]的边的时候图中的联通块个数. I ...
- BZOJ_4813_[Cqoi2017]小Q的棋盘_dfs
BZOJ_4813_[Cqoi2017]小Q的棋盘_dfs Description 小Q正在设计一种棋类游戏.在小Q设计的游戏中,棋子可以放在棋盘上的格点中.某些格点之间有连线,棋子只能 在有连线的格 ...
- 操作系统--进程管理(Processing management)
一.进程的组成 进程通常由程序.数据和进程控制块(Process Control Block,PCB)组成. 二. 进程的状态以及状态切换 进程执行时的间断性决定了进程可能具有多种状态,最基本的三种状 ...
- typeof和instansof的区别
typeof typeof 是一个一元运算,放在一个运算数之前,运算数可以是任意类型. 它返回值是一个字符串,该字符串说明运算数的类型.(typeof 运算符返回一个用来表示表达式的数据类型的字符串. ...
- 原生js实现 五子棋
先初始化棋盘 HTML: <!--棋盘--> <div class="grid"></div> CSS: /*棋盘*/ .grid{ posit ...
- 【Python实践-6】将不规范的英文名字,变为首字母大写,其他小写的规范名字
#利用map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字. def f1(s): s=s.capitalize() return s list1= ['adam', 'L ...
- 一个Mini的ASP.NET Core框架的实现
一.ASP.NET Core Mini 在2019年1月的微软技术(苏州)俱乐部成立大会上,蒋金楠老师(大内老A)分享了一个名为“ASP.NET Core框架揭秘”的课程,他用不到200行的代码实现了 ...
- CSharpGL(50)使用Assimp加载骨骼动画
CSharpGL(50)使用Assimp加载骨骼动画 在(http://ogldev.atspace.co.uk/www/tutorial38/tutorial38.html)介绍了C++用Asism ...