Naive Bayes (NB Model) 初识
1,Bayes定理
P(A,B)=P(A|B)P(B);
P(A,B)=P(B|A)P(A);
P(A|B)=P(B|A)P(A)/P(B); 贝叶斯定理变形
2,概率图模型
2.1 定义
概率图模型是一类用图的形式表示随机变量之间条件依赖关系的概率模型,是概率论与图论的结合。图中的节点表示随机变量,边表示随机变量之间的概率依赖关系.缺少边的节点表示满足条件独立假设。
2.2 随机变量的条件独立性
如果有P(A,B|C)=P(A|C)P(B|C), 则称在给定事件C的条件下,两个事件A和B独立,这里假设P(C)>0;
如:设A=2x+z; B=y+z; C=z;
在C确定的条件下 A,B是独立的。如假设z=0(常数),则A和B没有任何关联。
等价形式P(A|B,C)=P(A|C)
推导: P(A,B|C)=P(A|C)P(B|C); ...1
P(A,B|C)=P(A|B,C)P(B|C); ...2
联合1,2式可以=> P(A|C)=P(A|B,C)
2.3 概率图模型的有向图表示
利用有向图来表示变量之间的概率依赖关系,典型应用就是贝叶斯网络.
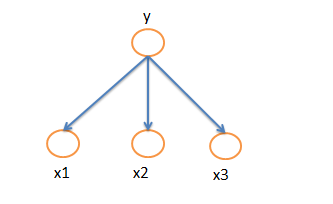
上图NaiveBayes 可以表示为: p(y,x1,x2,x3)=p(y).p(x1|y)p(x2|y)p(x3|y)
3,Naive Bayes Model
3.1 Bayes 决策理论思想
朴素贝叶斯是贝叶斯决策理论的一部分, 所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。
假设我们有一个数据集,如下图所示:
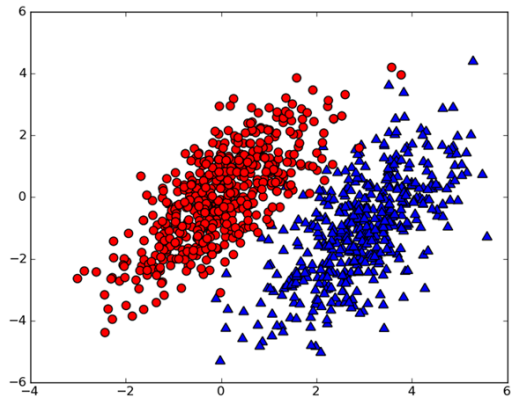
我们用P(c1|x,y) 表示数据点(x,y)属于类别c1的概率(图中红色圆点的概率),用P(c2|x,y)表示数据点(x,y)属于类别c2的概率(图中绿色的三角形概率)。那么对于一个新的数据点(x,y),我们就可以用一下规则来判断它的类别。
- If p(c1|x, y) > p(c2|x, y), then the class is c1.
- If p(c2|x, y) > p(c1|x, y), then the class is c2.
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想, 即选择具有最高概率的决策。
3.2 Naive Bayes 推导
假设某个体有n项特征(Feature),分别为F1、F2、...、Fn。现有m个类别(Category),分别为C1、C2、...、Cm。贝叶斯分类器就是计算出概率最大的那 个 分类,也就是求下面这个算式的最大值:P(C|F1,F2,...,Fn);
可以理解为求 在属性F1,F2,....Fn条件下,属于各个类别Ci的概率,然后求出最大的那个P(Ci|F1,F2,...Fn) ,这样就得到F1,F2,...Fn 属于哪一类(Ci)了。
使用贝叶斯原理可以写成
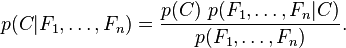
因为对于每一个类别的Ci的概率都存在P(F1,F2,......Fn)所以只需要关注P(C)P(F1,F2.....Fn|C)
写成联合概率的形式P(C,F1,F2...Fn)=P(C)P(F1,F2.....Fn|C)
重复使用贝叶斯原理=>
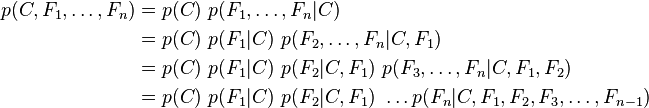
现在“朴素”的“条件独立”(2中有推导)假设开始发挥作用:假设每个特征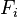 对于其他特征
对于其他特征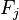 ,
,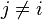 是条件独立的。这就意味着
是条件独立的。这就意味着
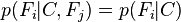
对于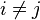 ,所以联合分布模型可以表达为
,所以联合分布模型可以表达为
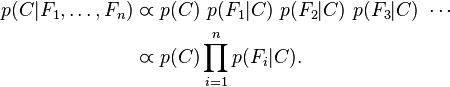
4,例子 ---性别分类
下面是一组人类身体特征的统计资料。
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
即,P(C|F1,F2,F3)的最大概率。
根据上面的Naive Bayes Model P(C|F1,F2,F3)=P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入, 算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的 值,只用来反映各个值的相对可能性)。
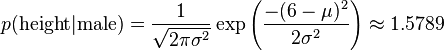
如上,我们就可以推出
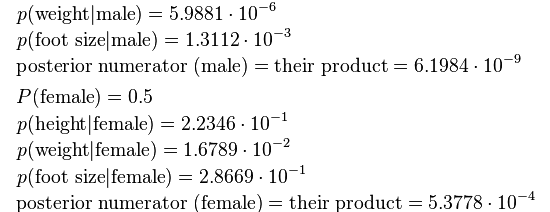
有了P(height|male),P(weight|male),...我们就可以得到
P(height=6|male) x P(weight=130|male) x P(footsize=8|male) x P(male)
= 6.1984 x e-9
P(height=6|female) x P(weight=130|female) x P(footsize=8|female) x P(female)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
5,概率图模型表示
p(y,x1,x2,x3)=p(y).p(x1|y)p(x2|y)p(x3|y), P(y,x1,x2,x3)=φ1(y)φ(y,x1)φ(y,x2)φ(y,x3)
使用有相图表示: 使用因子图表示:
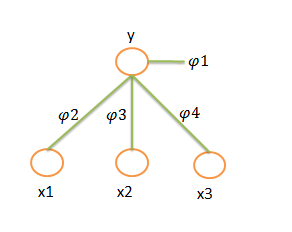
6,引用
http://en.wikipedia.org/wiki/Naive_Bayes_classifier#Probabilistic_model
http://pan.baidu.com/s/1dD1pcAl
Naive Bayes (NB Model) 初识的更多相关文章
- Spark MLlib 之 Naive Bayes
1.前言: Naive Bayes(朴素贝叶斯)是一个简单的多类分类算法,该算法的前提是假设各特征之间是相互独立的.Naive Bayes 训练主要是为每一个特征,在给定的标签的条件下,计算每个特征在 ...
- Naive Bayes Theorem and Application - Theorem
Naive Bayes Theorm And Application - Theorem Naive Bayes model: 1. Naive Bayes model 2. model: discr ...
- sklearn linear_model,svm,tree,naive bayes,ensemble
sklearn linear_model,svm,tree,naive bayes,ensemble by iris dataset .caret, .dropup > .btn > .c ...
- 数据挖掘十大经典算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.眼下研究较多的贝叶斯分类器主要有四种, ...
- 十大经典数据挖掘算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类分类原则是一个对象的通过先验概率.贝叶斯后验概率公式后计算,也就是说,该对象属于一类的概率.选择具有最大后验概率的类作为对象的类属.现在更多的研究贝叶斯分类器,有四个,每间:N ...
- 朴素贝叶斯分类器(Naive Bayes)
1. 贝叶斯定理 如果有两个事件,事件A和事件B.已知事件A发生的概率为p(A),事件B发生的概率为P(B),事件A发生的前提下.事件B发生的概率为p(B|A),事件B发生的前提下.事件A发生的概率为 ...
- MLLib实践Naive Bayes
引言 本文基于Spark (1.5.0) ml库提供的pipeline完整地实践一次文本分类.pipeline将串联单词分割(tokenize).单词频数统计(TF),特征向量计算(TF-IDF),朴 ...
- 基于Naive Bayes算法的文本分类
理论 什么是朴素贝叶斯算法? 朴素贝叶斯分类器是一种基于贝叶斯定理的弱分类器,所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关.举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果 ...
- 6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python)
6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python) Introduction Here’s a situation yo ...
随机推荐
- 如何设置select和option的文字居中?
今天在设置option文字居中时发现,给select设置text-align:center在火狐浏览器下ok,但是在chrome浏览器无效,然后option在两个浏览器下设置text-align:ce ...
- CSS3属性详解(图文教程)
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 以下是正文. 前言 我们在上一篇文章中学习了CSS3的选择器,本文来学一下CSS3的一 ...
- Django的ORM实现数据库事务操作
在Django中实现数据库的事务操作 在学习MySQL数据库时,MySQL数据库是支持原子操作的. 什么是数据库的原子操作呢??打个比方,一个消费者在一个商户里刷信用卡消费. 交易正常时,银行在消费者 ...
- python的logging模块
python提供了一个日志处理的模块,那就是logging 导入logging模块使用以下命令: import logging logging模块的用法: 1.简单的将日志打印到屏幕上 import ...
- 分组密码的工作模式--wiki
密码学中,块密码的工作模式允许使用同一个块密码密钥对多于一块的数据进行加密,并保证其安全性.[1][2] 块密码自身只能加密长度等于密码块长度的单块数据,若要加密变长数据,则数据必须先被划分为一些单独 ...
- 使用exe4j工具制作简单的java应用程序
首先需要下载exe4j工具并进行安装,下面是利用exe4j工具制作应用程序的步骤. 1.首先将工程导出为可运行的jar包,选择extract required libralies into gener ...
- 初识vps,域名与购买,初步配置
终于还是到了这一天,不管我们是不是程序员,当我们想拥有自己的一个的博客,当我们想有自己的一个空间,当我们想在网上有一个自己可以随心所欲编写任何不被限制的仅仅是酷炫的效果,当我们想收录自己的技术,经历, ...
- paping使用来测试联通&网站由于tcp协议导致的无法通信问题超时问题
1. 使用paping来测试连通性 Linux 平台: : wget http://www.updateweb.cn/softwares/paping_1.5.5_x86-64_linux.tar.g ...
- WinServer2012 R2忘记密码的解决方案+远程连接另一种莫名其妙故障
http://www.cnblogs.com/dunitian/p/4822808.html#iis 之前朋友有问道我WinServer2003密码破解的事情,基本上密码忘记了都是进PE用密码清除的工 ...
- 登录功能(MD5加密)
登录这个功能,是不管哪个项目都会用到的,登录做的好坏,安全性的保障将直接影响到整个系统的成败,尤其是一些安全性要求比较严格的项目 1.首先需要对密码进行加密,这里用到的是md5加密,需要在login. ...