Cypher查询语言--Neo4j 入门 (一)
目录
- 操作符
- 参数
- 标识符
- 注解
- Start
- 通过id绑定点
- 通过id绑定关系
- 通过id绑定多个节点
- 所有节点
- 通过索引查询获取节点
- 通过索引查询获取关系
- 多个开始点
Cypher是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。Cypher还在继续发展和成熟,这也就意味着有可能会出现语法的变化。同时也意味着作为组件没有经历严格的性能测试。
Cypher设计的目的是一个人类查询语言,适合于开发者和在数据库上做点对点模式(ad-hoc)查询的专业操作人员(我认为这个很重要)。它的构念是基于英语单词和灵巧的图解。
Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala programming language语言。
Cypher是一个申明式的语言。对比命令式语言如Java和脚本语言如Gremlin和JRuby,它的焦点在于从图中如何找回(what to retrieve),而不是怎么去做。这使得在不对用户公布的实现细节里关心的是怎么优化查询。
这个查询语言包含以下几个明显的部分:
Ø START:在图中的开始点,通过元素的ID或所以查找获得。
Ø MATCH:图形的匹配模式,束缚于开始点。
Ø WHERE:过滤条件。
Ø RETURN:返回所需要的。
在下例中看三个关键字
示例图片如下:
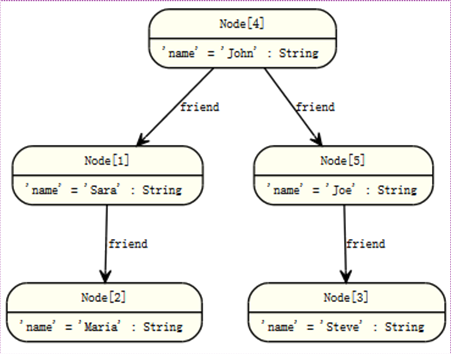
如:这个有个查询,通过遍历图找到索引里一个叫John的朋友的朋友(不是他的直接朋友),返回John和找到的朋友的朋友。
START john=node:node_auto_index(name = 'John')
MATCH john-[:friend]->()-[:friend]->fof
RETURN john, fof
返回结果:


下一步添加过滤:
在下一个例子中,列出一组用户的id并遍历图查找这些用户接出friend关系线,返回有属性name并且其值是以S开始的用户。
START user=node(5,4,1,2,3)
MATCH user-[:friend]->follower
WHERE follower.name =~ /S.*/
RETURN user, follower.name
返回结果:

操作符
Cypher中的操作符有三个不同种类:数学,相等和关系。
数学操作符有+,-,*,/和%。当然只有+对字符有作用。
等于操作符有=,<>,<,>,<=,>=。
因为Neo4j是一个模式少的图形数据库,Cypher有两个特殊的操作符?和!。
有些是用在属性上,有些事用于处理缺少值。对于一个不存在的属性做比较会导致错误。为替代与其他什么做比较时总是检查属性是否存在,在缺失属性时问号将使得比较总是返回true,感叹号使得比较总是返回false。
WHEREn.prop? = "foo"
这个断言在属性缺失情况下将评估为true。
WHEREn.prop! = "foo"
这个断言在属性缺失情况下将评估为false。
警告:在同一个比较中混合使用两个符号将导致不可预料的结果。
参数
Cypher支持带参数的查询。这允许开发者不需要必须构建一个string的查询,并且使得Cypher的查询计划的缓存更容易
参数可以在where子句,start子句的索引key或索引值,索引查询中作为节点/关系id的引用。
以下是几个在java中使用参数的示例:
节点id参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "id", 0 ); ExecutionResult result = engine.execute( "start n=node({id}) return n.name", params ); |
节点对象参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "node", andreasNode ); ExecutionResult result = engine.execute( "start n=node({node}) return n.name", params ); |
多节点id参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "id", Arrays.asList( 0, 1, 2 ) ); ExecutionResult result = engine.execute( "start n=node({id}) return n.name", params ); |
字符串参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "name", "Johan" ); ExecutionResult result = engine.execute( "start n=node(0,1,2) where n.name = {name} return n", params ); |
索引键值参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "key", "name" ); params.put( "value", "Michaela" ); ExecutionResult result = engine.execute( "start n=node:people({key} = {value}) return n", params ); |
索引查询参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "query", "name:Andreas" ); ExecutionResult result = engine.execute( "start n=node:people({query}) return n", params ); |
- SKIP 与LIMIT * 的数字参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "s", 1 ); params.put( "l", 1 ); ExecutionResult result = engine.execute( "start n=node(0,1,2) return n.name skip {s} limit {l}", params ); |
- 正则表达式参数
|
Map<String, Object> params = new HashMap<String, Object>(); params.put( "regex", ".*h.*" ); ExecutionResult result = engine.execute( "start n=node(0,1,2) where n.name =~ {regex} return n.name", params ); |
标识符
当你参考部分的模式时,需要通过命名完成。定义的不同的命名部分就被称为标识符。
如下例中:
START n=node(1) MATCH n-->b RETURN b
标识符为n和b。
标识符可以是大写或小些,可以包含下划线。当需要其他字符时可以使用`符号。对于属性名的规则也是一样。
注解
可以在查询语句中使用双斜杠来添加注解。如:
START n=node(1) RETURN b //这是行结束注释
START n=node(1) RETURN b
START n=node(1) WHERE n.property = "//这部是一个注释" RETURN b
Start
每一个查询都是描述一个图案(模式),在这个图案(模式)中可以有多个限制点。一个限制点是为模式匹配的从开始点出发的一条关系或一个节点。可以通过id或索引查询绑定点。
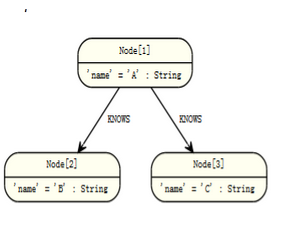
通过id绑定点
通过node(*)函数绑定一个节点作为开始点
查询:
START n=node(1)
RETURN n
返回引用的节点。
结果:
通过id绑定关系
可以通过relationship()函数绑定一个关系作为开始点。也可以通过缩写rel()。
查询:
START r=relationship(0)
RETURN r
Id为0的关系将被返回
结果:
通过id绑定多个节点
选择多个节点可以通过逗号分开。
查询:
START n=node(1, 2, 3)
RETURN n
结果:

所有节点
得到所有节点可以通过星号(*),同样对于关系也适用。
查询:
START n=node(*)
RETURN n
这个查询将返回图中所有节点。
结果:

通过索引查询获取节点
如果开始节点可以通过索引查询得到,可以如此来写:
node:index-name(key=”value”)。在此列子中存在一个节点索引叫nodes。
查询:
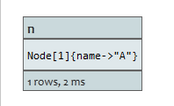
START n=node:nodes(name = "A")
RETURN n
索引中命名为A的节点将被返回。
结果:
通过索引查询获取关系
如果开始点可以通过索引查询得到,可以如此做:
Relationship:index-name(key=”value”)。
查询:
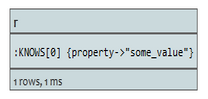
START r=relationship:rels(property ="some_value")
RETURN r
索引中属性名为”some_value”的关系将被返回
结果:
多个开始点
有时需要绑定多个开始点。只需要列出并以逗号分隔开。
查询:
START a=node(1), b=node(2)
RETURN a,b
A和B两个节点都将被返回。
结果:

Cypher查询语言--Neo4j 入门 (一)的更多相关文章
- Cypher查询语言--Neo4j 之高级篇 (六)
目录 排序Order by 通过节点属性排序节点 通过多节点属性排序节点 倒序排列节点 空值排序 Skip 跳过前三个 返回中间两个 Limit 返回第一部分 函数Functions 判断 All A ...
- Cypher查询语言--Neo4j之聚合函数(五)
目录 聚合Aggregation 计数 计算节点数 分组计算关系类型 计算实体数 计算非空可以值数 求和sum 平均值avg 最大值max 最小值min 聚类COLLECT 相异DISTINCT 聚合 ...
- Cypher查询语言--Neo4j 综合(四)
目录 返回节点 返回关系 返回属性 带特殊字符的标识符 列的别名 可选属性 特别的结果 查询中的返回部分,返回途中定义的感兴趣的部分.可以为节点.关系或其上的属性. 图 返回节点 返回一个节点,在 ...
- Neo4j入门详细教程
Neo4j安装配置 (1)下载安装包 (2)安装jdk (3)环境变量配置 分三步,具体参考 https://www.bilibili.com/video/BV1Nz411q7bG?from=sea ...
- Neo4j入门博客分享
Neo4j学习参考博客:https://www.cnblogs.com/ljhdo/p/5516793.html Neo4j Cypher查询语言详解 http://www.ttlsa.com/nos ...
- CYPHER 语句(Neo4j)
CYPHER 语句(Neo4j) 创建电影关系图 新增 查找 修改 删除 导入 格式转换 创建电影关系图 CREATE (TheMatrix:Movie {title:'The Matrix', re ...
- Neo4j Cypher查询语言详解
Cypher介绍 "Cypher"是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询.Cypher还在继续发展和成熟,这也就意味着有可能会出现 ...
- Neo4j入门之中国电影票房排行浅析
什么是Neo4j? Neo4j是一个高性能的NoSQL图形数据库(Graph Database),它将结构化数据存储在网络上而不是表中.它是一个嵌入式的.基于磁盘的.具备完全的事务特性的Java持 ...
- Neo4j入门-开始使用
前言 关系,指事物之间相互作用.相互影响的状态. 数据之间的关系也是如此,数据之间关系的存储在RDS就已经开始.从数据库支持的外键,到手动建立的关系表,人们采取了许多方法,只为了解决查询复杂.缓慢等问 ...
随机推荐
- VS工程中添加c/c++工程中外部头文件及库的基本步骤
转载自 在VS工程中,添加c/c++工程中外部头文件及库的基本步骤: 1.添加工程的头文件目录:工程---属性---配置属性---c/c++---常规---附加包含目录:加上头文件存放目录. 2.添加 ...
- isdigit函数
isdigit是计算机应用C语言中的一个函数,主要用于检查参数c是否为阿拉伯数字0到9. 相关函数 isdigit 表头文件 #include <ctype.h>(C语言),#includ ...
- GDOI 2016 & APIO 2016 游记
缓慢施工中...... UPD:APIO游记已烂尾......因为Cu滚粗+生病一直没心情写..过了几天就发现APIO的事都快忘光了...去看KPM的就可以啦 今年apio竟然没和gdoi撞...智障 ...
- HDU--2114
Calculate S(n) Time Limit: 10000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- 根据PV统计出前三的热门板块,并统计出热门板块下的用户数--方式一
根据PV统计出前三的热门板块,并统计出热门板块下的用户数--方式一 测试数据 java代码 package com.hzf.spark.study; import java.util.ArrayLis ...
- async函数解析
转载请注明出处:async函数解析 async函数是基于Generator函数实现的,也就是说是Generator函数的语法糖.在之前的文章有介绍过Generator函数语法和异步应用,如果对其不了解 ...
- ffmpeg批量实现视频转码命令行
ffmpeg实现视频转码命令行,result需要提前建好作为保存转码后的视频路径: ffmpeg -i .mp4 -vcodec h264 "result\1.mp4" 当有大量视 ...
- UITableViewCell滑动删除及移动
实现Cell的滑动删除, 需要实现UITableView的代理UITableViewDelegate中如下方法: //先要设Cell可编辑 - (BOOL)tableView:(UITableView ...
- Android-第二天
1.Activity是Android组件中最基本也是最为常见用的四大组件(Activity,Service服务,Content Provider内容提供者,BroadcastReceiver广播接收器 ...
- ublime Text 3安装与使用
ublime Text 3安装与使用 工具 2015-07-30 10:46 0 34 工欲善其事,必先利其器.好的工具帮助我们节省大量的工作时间,好用的插件使工具更强大. 1. 下载 可以从官网 h ...