菜鸟学IT之python网页爬取多页爬取
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3002
0.从新闻url获取点击次数,并整理成函数
- newsUrl
- newsId(re.search())
- clickUrl(str.format())
- requests.get(clickUrl)
- re.search()/.split()
- str.lstrip(),str.rstrip()
- int
- 整理成函数
- 获取新闻发布时间及类型转换也整理成函数
import re
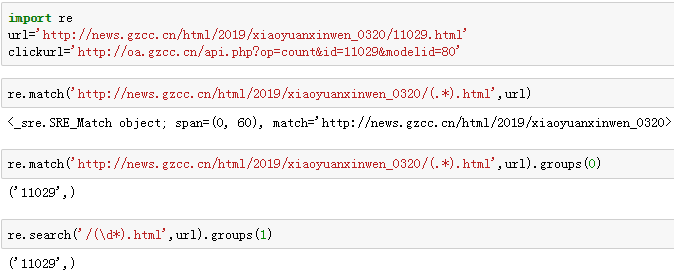
url='http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
clickurl='http://oa.gzcc.cn/api.php?op=count&id=11029&modelid=80'
re.match('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/(.*).html',url)
re.match('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/(.*).html',url).groups(0)
re.search('/(\d*).html',url).groups(1)
re.findall('(\d+)',url)
结果如下:
1.从新闻url获取新闻详情: 字典,anews
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re def click(url):
id=re.findall('(\d{1,5})',url)[-1]
clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id=11029&modelid=80'.format(id)
resClick = requests.get(clickUrl)
newsClick = int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');"))
return newsClick def newsdt(showinfo):
newsDate = showinfo.split()[0].split(':')[1]
newsTime = showinfo.split()[1]
newsDT = newsDate+' '+newsTime
dt = datetime.strptime(newsDT, '%Y-%m-%d %H:%M:%S') return dt def anews(url):
newsDetail = {}
res = requests.get(url)
res.encoding ='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
newsDetail['nenewsTitle'] =soup.select('.show-title')[0].text
showinfo = soup.select('.show-info')[0].text
newsDetail['newsDT']=newsdt(showinfo)
newsDetail['newsClick'] =click(newsUrl)
return newsDetail newsUrl='http://news.gzcc.cn/html/2005/xiaoyuanxinwen_0710/4.html'
anews(newsUrl)
结果:

2.从列表页的url获取新闻url:列表append(字典) alist
- 获取列表数据
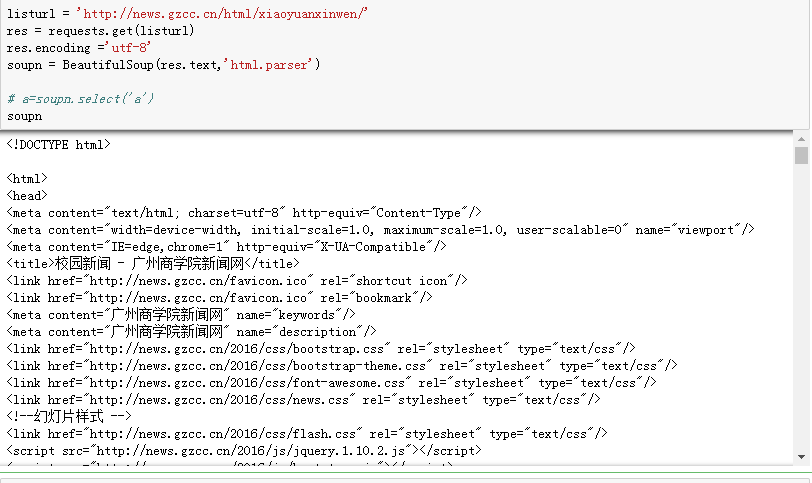
listurl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(listurl)
res.encoding ='utf-8'
soupn = BeautifulSoup(res.text,'html.parser') # a=soupn.select('a')
soupn
2.过滤过滤数据,只获取列表的新闻信息
for news in soupn.select('li'):
if news.select('.news-list-title'):
print(news)
newsUrl = news.a['href']
print(news.a['href'])

3.获取整页信息
def alist(listUrl):
res = requests.get(listurl)
res.encoding ='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
newsList =[]
for news in soupn.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl = news.select('a')[0]['href']
newsDesc = news.select('.news-list-description')[0].text
newsDict = anews(newsUrl)
newsDict['newsUrl'] = newsUrl
newsDict['description'] = newsDesc
newsList.append(newsDict)
return newsList listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
alist(listUrl)

3.生成所页列表页的url并获取全部新闻 :列表extend(列表) allnews
*每个同学爬学号尾数开始的10个列表页
- 获取多页信息
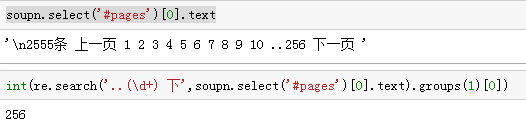
- 截取以学号尾数开始的10个列表页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
allnews = alist(listUrl) for i in range(7,17): #学号为7,截取10页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
allnews.extend(alist(listUrl)) len(allnews)

4.设置合理的爬取间隔
import time
import random
time.sleep(random.random()*3)
import time
import random
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
allnews = alist(listUrl) for i in range(1,170): #学号为7,截取10页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
allnews.extend(alist(listUrl))
time.sleep(random.random()*3) #设置每3秒爬取一次
print(alist(listUrl)) len(allnews)
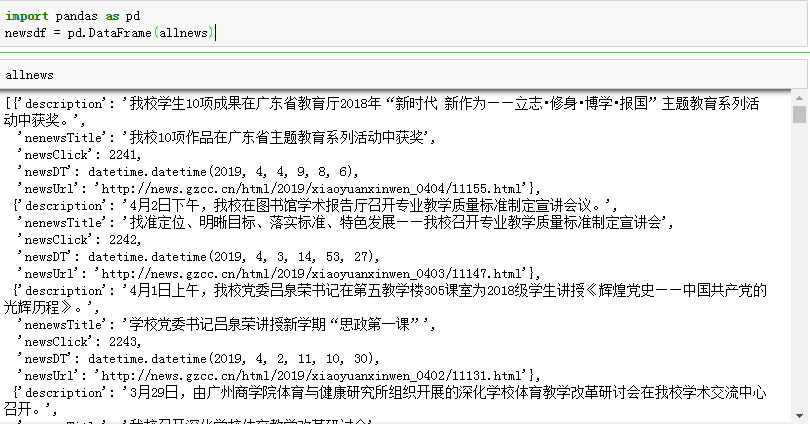
5.用pandas做简单的数据处理并保存
保存到csv或excel文件
newsdf.to_csv(r'F:\duym\爬虫\gzccnews.csv')
- 使用pandas函数整理爬取的数据
- 列表的形式打印数据
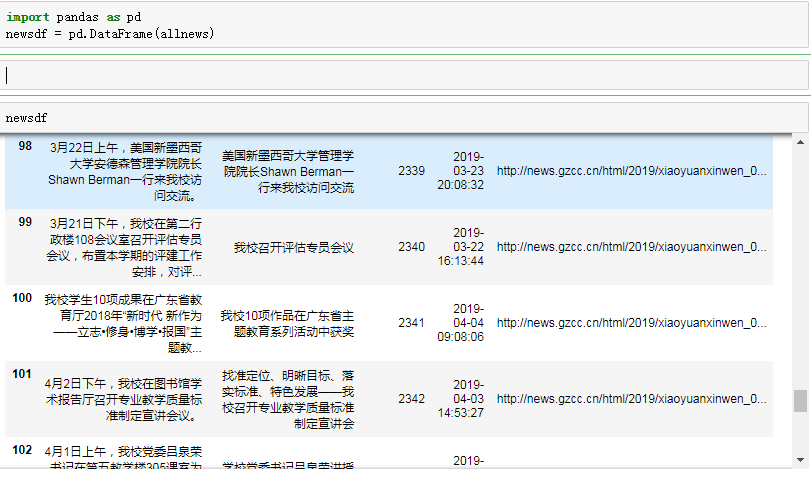
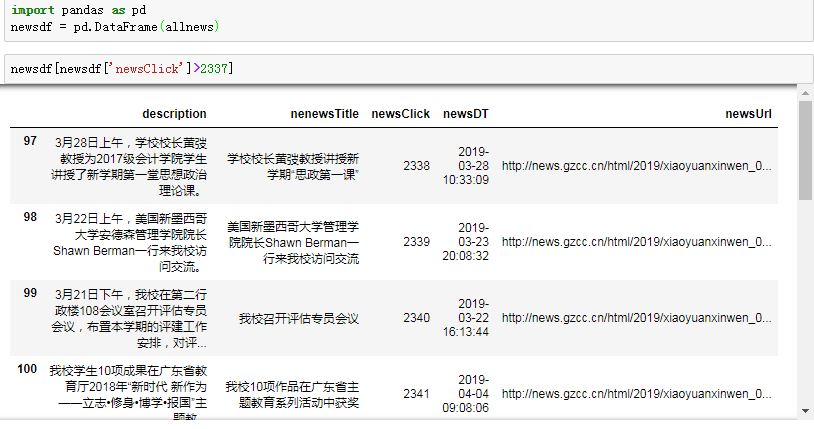
- 显示 “newsClick” 游览次数大于2337的新闻
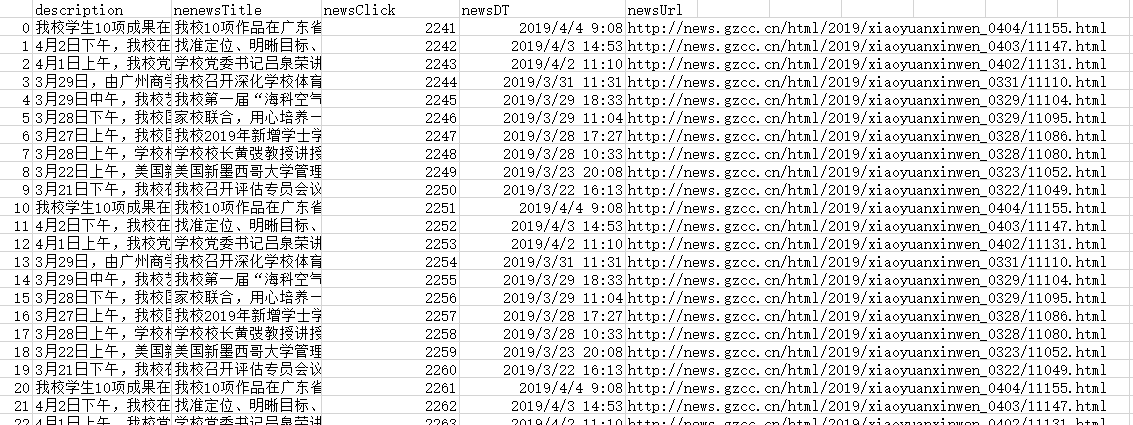
- 生成csv文件
newsdf.to_csv(r'E:\gzcc.csv')
菜鸟学IT之python网页爬取多页爬取的更多相关文章
- 菜鸟学IT之python网页爬取初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881 1. 简单说明爬虫原理 爬虫简单来说就是通过程序模拟浏览器放松请求站 ...
- python实现一个栏目的分页抓取列表页抓取
python实现一个栏目的分页抓取列表页抓取 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import Beautifu ...
- 菜鸟学IT之python词云初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822 1. 下载一长篇中文小说. 2. 从文件读取待分析文本. txt = ...
- python网页爬虫开发之五-反爬
1.头信息检查是否频繁相同 随机产生一个headers, #user_agent 集合 user_agent_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据
通过requests.re(正则表达式) 爬取"古诗文"网页数据. 详细代码如下: #!/user/bin env python # author:Simple-Sir # tim ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
随机推荐
- 爬虫框架之Scrapy(三 CrawlSpider)
如何爬取一个网站的全站数据? 可以使用Scrapy中基于Spider的递归方式进行爬取(Request模块回调parse方法) 还有一种更高效的方法,就是基于CrawlSpider的自动爬取实现 简介 ...
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- Java读取excel表,getPhysicalNumberOfCells()和getLastCellNum区别
excel表存入数据库,发现有时报数组下标越界异常.调试发现用了 getPhysicalNumberOfCells(),这个是用来获取不为空的的列个数. getLastCellNum是获取最后一个不为 ...
- cordova build android Command failed with exit code EACCES
问题: 执行cordova build android 出现输出如下,编译不成功. ANDROID_HOME=/Users/huangenai/Library/Android/sdkJAVA_HOME ...
- ZZCMS v8.2 前台Insert注入+任意文件删除
前几天看了水泡泡老哥的zzcms的审计,在论坛上一搜发现这个cms有不少洞.听说很适合小白练手,所以来瞅一瞅.不知道我发现的这个洞是不是已经被爆过了,如果雷同,纯属巧合. 一.Insert注入,直接返 ...
- mybatis自动填充时间字段
对于实体中的created_on和updated_on来说,它没有必要被开发人员去干预,因为它已经足够说明使用场景了,即在插入数据和更新数据时,记录当前时间,这对于mybatis来说,通过拦截器是可以 ...
- 【Python3爬虫】自动查询天气并实现语音播报
一.写在前面 之前写过一篇用Python发送天气预报邮件的博客,但是因为要手动输入城市名称,还要打开邮箱才能知道天气情况,这也太麻烦了.于是乎,有了这一篇博客,这次我要做的就是用Python获取本机I ...
- 系统检测工具ROSWTF
ROSWTF 详细见http://wiki.ros.org/roswtf roswtf will examine your ROS setup, such as your environment va ...
- 零基础学Python--------第10章 文件及目录操作
第10章 文件及目录操作 10.1 基本文件操作 在Python中,内置了文件(File)对象.在使用文件对象时,首先需要通过内置的open() 方法创建一个文件对象,然后通过对象提供的方法进行一些基 ...
- Spring RestTemplate详解
Spring RestTemplate详解 1.什么是REST? REST(RepresentationalState Transfer)是Roy Fielding 提出的一个描述互联系统架构风格 ...