【JDK源码分析】String的存储区与不可变性
// ... literals are interned by the compiler
// and thus refer to the same object
String s1 = "abcd";
String s2 = "abcd";
s1 == s2; // --> true
// ... These two have the same value
// but they are not the same object
String s1 = new String("abcd");
String s2 = new String("abcd");
s1 == s2; // --> false
看上面一段代码,我们会发生疑惑:为什么通过字符串常量实例化的String类型对象是一样的,而通过new所创建String对象却不一样呢?且看下面分解。
1. 数据存储区
String是一个比较特殊的类,除了new之外,还可以用字面常量来定义。为了弄清楚这二者间的区别,首先我们得明白JVM运行时数据存储区,这里有一张图对此有清晰的描述:
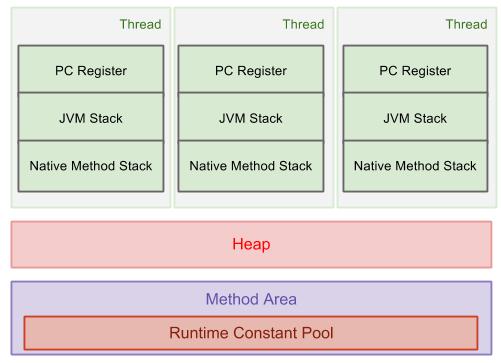
非共享数据存储区
非共享数据存储区是在线程启动时被创建的,包括:
- 程序计数器(program counter register)控制线程的执行;
- 栈(JVM Stack, Native Method Stack)存储方法调用与对象的引用等。
共享数据存储区
该存储区被所有线程所共享,可分为:
- 堆(Heap)存储所有的Java对象,当执行new对象时,会在堆里自动进行内存分配。
- 方法区(Method Area)存储常量池(run-time constant pool)、字段与方法的数据、方法与构造器的代码。
2. 两种实例化
实例化String对象:
public class StringLiterals {
public static void main(String[] args) {
String one = "Test";
String two = "Test";
String three = "T" + "e" + "s" + "t";
String four = new String("Test");
}
}
javap -c StringLiterals反编译生成字节码,我们选取感兴趣的部分如下:
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String Test
2: astore_1
3: ldc #2 // String Test
5: astore_2
6: ldc #2 // String Test
8: astore_3
9: new #3 // class java/lang/String
12: dup
13: ldc #2 // String Test
15: invokespecial #4 // Method java/lang/String."<init>": (Ljava/lang/String;)V
18: astore 4
20: return
}
ldc #2表示从常量池中取#2的常量入栈,astore_1表示将引用存在本地变量1中。因此,我们可以看出:对象one、two、three均指向常量池中的字面常量"Test";对象four是在堆中new的新对象;如下图所示:
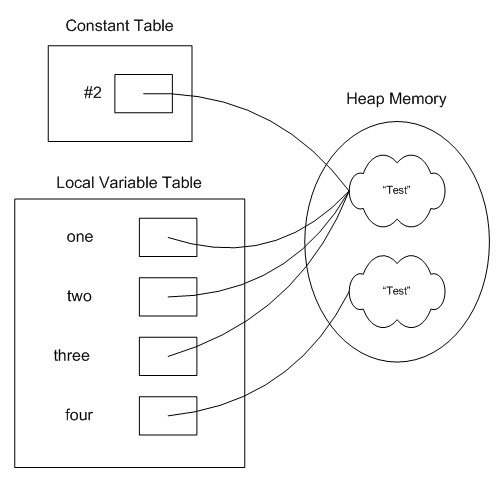
总结如下:
- 当用字面常量实例化时,String对象存储在常量池;
- 当用new实例化时,String对象存储在堆中;
操作符==比较的是对象的引用,当其指向的对象不同时,则为false。因此,开篇中的代码会出现通过new所创建String对象不一样。
3. 不可变String
String源码
JDK7的String类:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
}
String类被声明为final,不可以被继承,所有的方法隐式地指定为final,因为无法被覆盖。字段char value[]表示String类所对应的字符串,被声明为private final;即初始化后不能被修改。常用的new实例化对象String s1 = new String("abcd");的构造器:
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
只需将value与hash的字段值进行传递即可。
不可变性
所谓不可变性(immutability)指类不可以通过常用的API被修改。为了更好地理解不可变性,我们先来看《Thinking in Java》中的一段代码:
//: operators/Assignment.java
// Assignment with objects is a bit tricky.
import static net.mindview.util.Print.*;
class Tank {
int level;
}
public class Assignment {
public static void main(String[] args) {
Tank t1 = new Tank();
Tank t2 = new Tank();
t1.level = 9;
t2.level = 47;
print("1: t1.level: " + t1.level +
", t2.level: " + t2.level);
t1 = t2;
print("2: t1.level: " + t1.level +
", t2.level: " + t2.level);
t1.level = 27;
print("3: t1.level: " + t1.level +
", t2.level: " + t2.level);
}
} /* Output:
1: t1.level: 9, t2.level: 47
2: t1.level: 47, t2.level: 47
3: t1.level: 27, t2.level: 27
*///:~
上述代码中,在赋值操作t1 = t2;之后,t1、t2包含的是相同的引用,指向同一个对象。因此对t1对象的修改,直接影响了t2对象的字段改变。显然,Tank类是可变的。
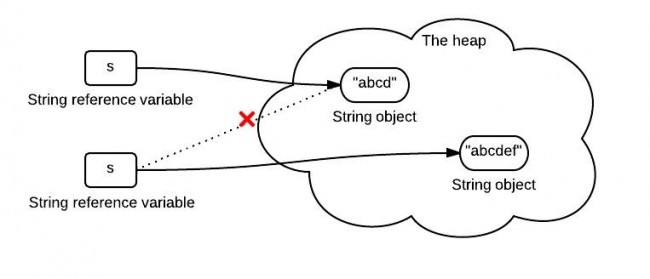
也许,有人会说s = s.concat("ef");不是修改了对象s么?而事实上,我们去看concat的实现,会发现其返回的是新String对象(return new String(buf, true););改变的只是s1引用所指向的对象,如下图所示:
4. 反射
String的value字段是final的,可不可以通过过某种方式修改呢?答案是反射。在stackoverflow上有这样一段修改value字段的代码:
String s1 = "Hello World";
String s2 = "Hello World";
String s3 = s1.substring(6);
System.out.println(s1); // Hello World
System.out.println(s2); // Hello World
System.out.println(s3); // World
Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
char[] value = (char[])field.get(s1);
value[6] = 'J';
value[7] = 'a';
value[8] = 'v';
value[9] = 'a';
value[10] = '!';
System.out.println(s1); // Hello Java!
System.out.println(s2); // Hello Java!
System.out.println(s3); // World
在上述代码中,为什么对象s2的值也会被修改,而对象s3的值却不会呢?根据前面的介绍,s1与s2指向同一个对象;所以当s1被修改后,s2也会对应地被修改。至于s3对象为什么不会?我们来看看substring()的实现:
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
当beginIndex不为0时,返回的是new的String对象;当beginIndex为0时,返回的是原对象本身。如果将String s3 = s1.substring(6);改为String s3 = s1.substring(0);,那么对象s3也会被修改了。
如果仔细看java.lang.String.java,我们会发现:当需要改变字符串内容时,String类的方法返回的是新String对象;如果没有改变,String类的方法则返回原对象引用。这节省了存储空间与额外的开销。
5. 参考资料
[1] Programcreek, JVM Run-Time Data Areas.
[2] Corey McGlone, Looking "Under the Hood" with javap.
[3] Programcreek, Diagram to show Java String’s Immutability.
[4] Stackoverflow, Is a Java string really immutable?
[5] Programcreek, Why String is immutable in Java ?
【JDK源码分析】String的存储区与不可变性的更多相关文章
- JDK源码分析-String、StringBuilder、StringBuffer
String类的申明 public final class String implements java.io.Serializable, Comparable<String>, Char ...
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue
JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue 目的:本文通过分析JDK源码来对比ArrayBlockingQueue 和LinkedBlocki ...
- java-通过 HashMap、HashSet 的源码分析其 Hash 存储机制
通过 HashMap.HashSet 的源码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并非真正的把 Java 对象放入数组中.仅仅是把对象的 ...
- 【JDK】JDK源码分析-LinkedHashMap
概述 前文「JDK源码分析-HashMap(1)」分析了 HashMap 主要方法的实现原理(其他问题以后分析),本文分析下 LinkedHashMap. 先看一下 LinkedHashMap 的类继 ...
- 【JDK】JDK源码分析-Vector
概述 上文「JDK源码分析-ArrayList」主要分析了 ArrayList 的实现原理.本文分析 List 接口的另一个实现类:Vector. Vector 的内部实现与 ArrayList 类似 ...
- 【JDK】JDK源码分析-ArrayList
概述 ArrayList 是 List 接口的一个实现类,也是 Java 中最常用的容器实现类之一,可以把它理解为「可变数组」. 我们知道,Java 中的数组初始化时需要指定长度,而且指定后不能改变. ...
- 【JDK】JDK源码分析-Semaphore
概述 Semaphore 是并发包中的一个工具类,可理解为信号量.通常可以作为限流器使用,即限制访问某个资源的线程个数,比如用于限制连接池的连接数. 打个通俗的比方,可以把 Semaphore 理解为 ...
- 【JDK】JDK源码分析-HashMap(2)
前文「JDK源码分析-HashMap(1)」分析了 HashMap 的内部结构和主要方法的实现原理.但是,面试中通常还会问到很多其他的问题,本文简要分析下常见的一些问题. 这里再贴一下 HashMap ...
- JDK源码学习--String篇(二) 关于String采用final修饰的思考
JDK源码学习String篇中,有一处错误,String类用final[不能被改变的]修饰,而我却写成静态的,感谢CTO-淼淼的指正. 风一样的码农提出的String为何采用final的设计,阅读JD ...
随机推荐
- TCP字节流和UDP数据报区别
两者的区别在于TCP接收的是一堆数据,而每次取多少由主机决定;而UDP发的是数据报,客户发送多少就接收多少. 拥有这些区别的原因是由于TCP和UDP的特性不同而决定的.TCP是面向连接的,也就是说,在 ...
- Demystifying ASP.NET MVC 5 Error Pages and Error Logging
出处:http://dusted.codes/demystifying-aspnet-mvc-5-error-pages-and-error-logging Error pages and error ...
- 关于RPC与MQ异同的理解
最近看了一些资料,回顾过去项目的经验,梳理自己对两者异同的理解: 相同: 1.都利于大型系统的解耦: 2.都提供子系统之间的交互,特别是异构子系统(如java\node等不同开发语言): 不同: 1. ...
- JavaScript思维导图—正则表达式
JavaScript思维导图-来自@王子墨http://julying.com/blog/the-features-of-javascript-language-summary-maps/
- 每天一个linux命令(58):telnet命令
telnet命令通常用来远程登录.telnet程序是基于TELNET协议的远程登录客户端程序.Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式.它为用户 ...
- 60,000毫秒内对Linux的性能诊断效的方法
转载于:http://www.itxuexiwang.com/a/liunxjishu/2016/0225/168.html?1456484140 60,000 毫秒内对 Linux 的性能诊断 当你 ...
- Java-继承,多态练习09-22-01
1.实现如下类之间的继承关系,并编写Music类来测试这些类. 父类: package com.lianxi; public class Instrument { //属性 private Strin ...
- @SuppressWarnings忽略警告
简介:java.lang.SuppressWarnings是J2SE 5.0中标准的Annotation之一.可以标注在类.字段.方法.参数.构造方法,以及局部变量上.作用:告诉编译器忽略指定的警告, ...
- salesforce 零基础学习(三十)工具篇:Debug Log小工具
开发中查看log日志是必不可少的,salesforce自带的效果显示效果不佳,大概显示效果如下所示: chrome商城提供了apex debug log良好的插件,使debug log信息更好显示.假 ...
- vuejs件同一个挂载点上切换组
vuejs件同一个挂载点上切换组 动态组件 http://cn.vuejs.org/guide/components.html#动态组件 多个组件可以使用同一个挂载点,然后动态地在它们之间切换.使用保 ...