MySQL 第九天(核心优化三)
一.昨天内容回顾
- 索引设计依据
与数据表有关系的sql语句都统计出来
where order by or等等条件的字段适当做索引
原则:
频率高的sql语句
执行时间长的sql语句
业务逻辑重要的sql语句
什么样子字段不适合做索引?
内容比较单调的字段不适合做索引
- 前缀索引
一个字段只取前边的几位内容做索引
好处:索引空间比较少、运行速度快
前n位做索引,前n位要具备唯一标识当前记录的特点
- 全文索引
Mysql5.5 只MYisam存储引擎可以实现
Mysql5.6 Myisam和Innodb存储引擎都可以实现
fulltext index 索引名称 (字段,字段)
select * from 表名 where 字段 like '%内容%' or 字段 like '%内容%';
select * from 表名 match(字段,字段) against("内容1,内容2");
match(字段,字段) against("内容1,内容2")
- 索引结构
Mysql的索引结构是B+Tree结构
索引就是数据结构(自然有算法),算法可以保证数据非常快速被找到
非聚集(Myisam)
叶子节点的关键字(索引字段内容) 与 记录的物理地址对应
聚集(Innodb)
主(键)索引:叶子节点的关键字 与 整条记录对应
非主(唯一/普通/全文)索引:叶子节点的关键字 与 主键关键字对应
- 查询缓存
开启缓存,开辟缓存空间(64MB)
缓存失效:表 或 数据 内容改变
不使用缓存:sql语句有变化的信息,例如当前时间、随机数
同一个业务逻辑的多个sql语句,有不同结构(空格变化、大小写变哈)的变化,每个样子的sql语句会分别设置缓存
- 分区、分表设计
分区表算法(Mysql):key hash range list
(php代码不会发生变化)
分区增加或减少:
减少:hash/range/list类型算法会丢失对应的数据
- 垂直分表
把一个数据表的多个字段进行拆分,分别分配到不同的数据表中
涉及的算法是php层面的
- 架构设计
主从模式(读写分离、一主多从)
主服务器负责"写"数据,从服务器负责"读"数据
"主" 会 自动 给"从" 同步数据(mysql本身技术)
通过"负载均衡"可以平均地从 从服务器 获得数据
- 慢查询日志设置
show variables like 'slow_query_log%';
开启慢查询日志开关
设置时间阀值
二.Mysql优化
1. 大量写入记录信息
保证数据非常快地写入到数据库中
insert into 表名 values (),(),(),();
以上一个insert语句可以同时写入多条记录信息,但是不要写入太多
避免意外情况发生。
可以一次少写一些,例如每次写入1000条,这样100万的记录信息,执行1000次insert语句就可以了。
分批分时间把数据写入到数据库中。
以上设计写入大量数据的方法损耗的时间:
写入数据(1000条)----->为1000条数据维护索引
写入数据(1000条)----->为第2个1000条数据维护索引
......
写入数据(1000条)----->为第1000个1000条数据维护索引
以上设计写入100万条记录信息,时间主要都被"维护索引"给占据了
如果做优化:就可以减少索引的维护,达到整体运行时间变少。
(索引维护不需要做1000次,就想做一次)
解决:
先把索引给停掉,专门把数据先写入到数据库中,最后在一次性维护索引
1.1 Myisam数据表
- 数据表中已经存在数据(索引已经存在一部分)
alter table 表名 disable keys;
大量写入数据
alter table 表名 enable keys; //最后统一维护索引
- 数据表中没有数据(索引内部没有东西)
alter table 表名 drop primary key ,drop index 索引名称(唯一/普通/全文);
大量写入数据
alter table 表名 add primary key(id),(唯一/全文)index 索引名 (字段);
1.2 Innodb数据表
该存储引擎支持"事务"
该特性使得我们可以一次性写入大量sql语句
具体操作:
start transaction;
大量数据写入(100万条记录信息 insert被执行1000次)
事务内部执行的insert的时候,数据还没有写入到数据库
只有数据真实写入到数据库才会执行"索引"维护
commit;
commit执行完毕后最后会自动维护一次"索引";
2. 单表、多表查询
数据库操作有的时候设计到 连表查询、子查询操作。
复合查询一般要涉及到多个数据表,
多个数据表一起做查询好处:sql语句逻辑清晰、简单
其中不妥当的地方是:消耗资源比较多、时间长
不利于数据表的并发处理,因为需要长时间锁住多个表
例如:
查询每个品牌下商品的总数量(Goods/Brand)
Goods:id name bd_id
Brand: bd_id name
select b.bd_id,b.name,count(g.*) from Brand b join Goods g on b.bd_id=g.bd_id group by b.bd_id;
以上sql语句总运行时间是5s
但是业务要求是数据库的并发性要高,就需要把"多个查询" 变为 "单表查询"
步骤:
① select bd_id,count(*) from Goods group by bd_id; //查询每个品牌的商品数量 //3s
② select bd_id,name from Brand; //3s
③ 在php通过逻辑代码整合① 和 ② //1s
3. limit使用
数据分页使用limit;
limit 偏移量,长度(每页条数);
偏移量:(当前页码-1)*每页条数
分页实现:
每页获得10条信息:
limit 0,10;
limit 10,10;
limit 20,10;
limit 30,10;
limit 990,10; //第100页
limit 9990,10; //第1000页
limit 99990,10; //第10000页
limit 999990,10; //第100000页
limit 1499990,10; //第150000页
limit 1500000,10; //第150001页
select * from emp limit 1500000,10; //慢 1秒多时间
select * from emp where empno>1600001 limit 10; //快 0.00秒级

数据表目前有empno主键索引:
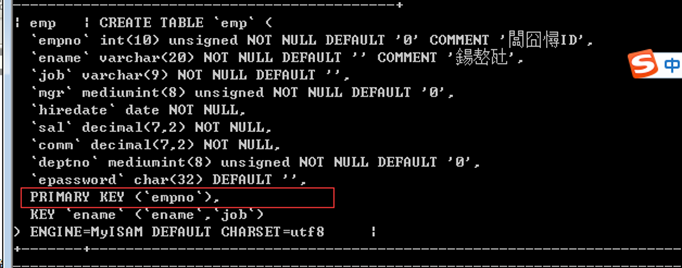
limit 偏移量,长度;运行时间较长:

单纯运行limit 运行时间比较长,内部没有使用索引,翻页效果 之前页码的信息给获得出来,但是"越"过去,因此比较浪费时间
现在对获得相同页码信息的sql语句进行优化
由单纯limit变为 where 和 limit的组合:
执行速度明显加快,因为其有使用where条件字段的索引


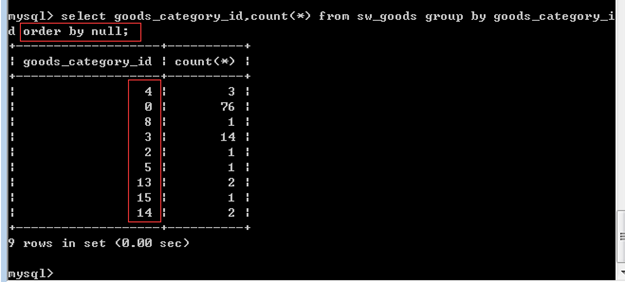
4. order by null
强制不排序
有的sql语句在执行的时候,本身默认会有排序效果
但是有的时候我们的业务不需要排序效果,就可以进行强制限制,进而"节省默认排序"带来的资源消耗。
group by 字段;
获得的结果在默认情况下会根据"分组字段"进行排序:

order by null强制不排序,节省对应资源:
MySQL 第九天(核心优化三)的更多相关文章
- MySQL 第七天(核心优化一)
一.Mysql核心优化 1. 优化的方面 ① 存储层:数据表"存储引擎"选取.字段选取.逆范式(3范式) ② 设计层:索引.分区/分表 ③ 架构层:分布式部署(主从模式/共享) ④ ...
- Mysql优化(出自官方文档) - 第九篇(优化数据库结构篇)
目录 Mysql优化(出自官方文档) - 第九篇(优化数据库结构篇) 1 Optimizing Data Size 2 Optimizing MySQL Data Types 3 Optimizing ...
- MySQL优化三(InnoDB优化)
body { font-family: Helvetica, arial, sans-serif; font-size: 14px; line-height: 1.6; padding-top: 10 ...
- MySQL性能优化(三):索引
原文:MySQL性能优化(三):索引 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/vbi ...
- 十三、linux-mysql的mysql的核心优化思想
一.数据库运维管理思想核心 1.未雨绸缪,不要停留在制度上,而是要实际做出来 2.亡羊补牢,举一反三,不要好了伤疤忘了疼 3.完善的框架设计及备份.恢复策略 4.定期思考,并实战模拟以上策略演练 二. ...
- MySql学习(六) —— 数据库优化理论(二) —— 查询优化技术
逻辑查询优化包括的技术 1)子查询优化 2)视图重写 3)等价谓词重写 4)条件简化 5)外连接消除 6)嵌套连接消除 7)连接消除 8)语义优化 9)非SPJ优化 一.子查询优化 1. ...
- 第 8 章 MySQL 数据库 Query 的优化
前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 Query 语句的优化进行相应的分析. ...
- MySQL 数据库 Query 的优化
理解MySQL的Query Optimizer MySQL Optimizer是一个专门负责优化SELECT 语句的优化器模块,它主要的功能就是通过计算分析系统中收集的各种统计信息,为客户端请求的Qu ...
- MySQL性能调优与架构设计——第8章 MySQL数据库Query的优化
第8章 MySQL数据库Query的优化 前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 ...
随机推荐
- 微信网页授权snsapi_base、snsapi_userinfo的问题
微信网页授权SCOPE分为snsapi_base.snsapi_userinfo,前者是用户无感知的静默授权只能拿到openid:而后者需要用户确认,能拿到更多的用户信息. 我有一个系统需要进行网页授 ...
- DEX 方法超过64K限制和gradle编译OOM问题解决
如果你是一个android开发者,你至少听说过的Dalvik的蛋疼的64K方法限制.概括地说,在一个DEX文件,你可以调用很多的方法,但你只能调用它们最前面的65,536个 ,因为这是在方法调用集合中 ...
- 与VS集成的若干种代码生成解决方案[博文汇总(共8篇)]
http://www.cnblogs.com/artech/archive/2010/11/17/CodeGeneration.html [第1篇] 通过CodeDOM定义生成代码的结构 我 不知道大 ...
- Oracle 11g r2 安装
Help Center:http://docs.oracle.com/cd/E11882_01/install.112/e24326/toc.htm#i1011296 前提:linux需要安装图形化介 ...
- python_selenium智联搜索
python_selenium智联搜索 妹子要去招聘会工作,奈何网上仅仅提供招聘会的公司名字,没有提供招聘的职位,SO我写了个小代码给妹子在智联上面搜索职位,由于时间紧迫,前程的就不写了 #!/usr ...
- Gulp安装及配合组件构建前端开发一体化
原文:http://www.dbpoo.com/getting-started-with-gulp/ 所有功能前提需要安装nodejs(本人安装版本v0.10.26)和ruby(本人安装版本1.9.3 ...
- Kafka集群配置说明
#kafka数据的存放地址,多个地址的话用逗号分 log.dirs=/tmp/kafka-logs #broker server服务端口 port=9092 #这个参数会在日志segment没有达到l ...
- Supervisor 安装
在linux或者unix操作系统中,守护进程(Daemon)是一种运行在后台的特殊进程,它独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件.由于在linux中,每个系统与用户进行交流的界 ...
- java和h5 canvas德州扑克开发中(一)
先附上我的德州扑克测试地址 http://120.26.217.116:8080/LxrTexas/texasIndex.html 我和一个朋友的德州扑克历时一个多月开发,目前已经基本可玩. 前端主要 ...
- NLP情感分析监督学习样本打标
1). 情感打标 a). 全句 单句 标签 好吃是好吃 pos 真材实料 pos 不过感觉一人份的量就有点小贵 neg 点的是肥牛米线 neu b). 全文本 文本 标签 分量足,味道不错,味道也不错 ...