利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
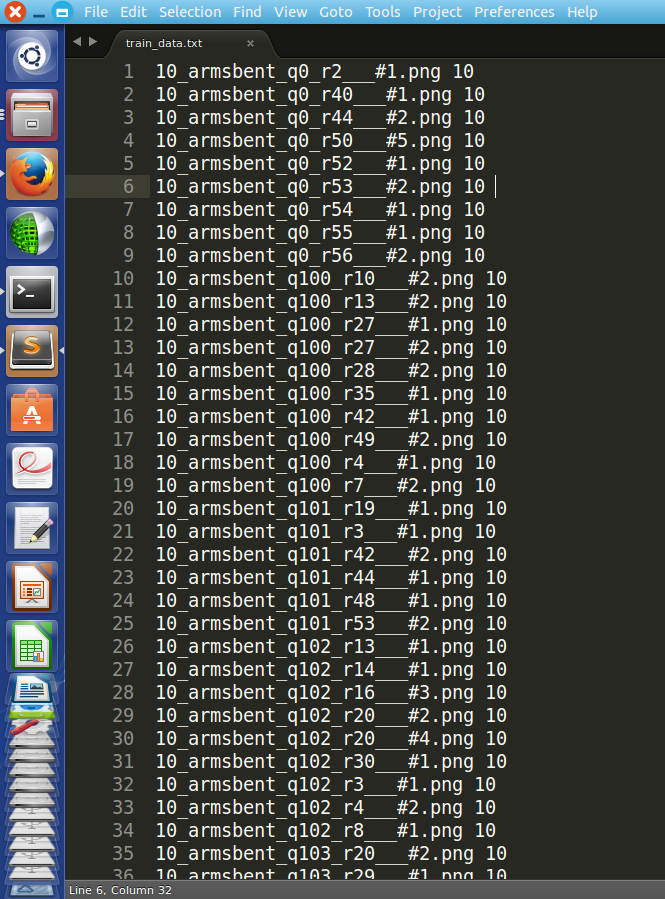
数据的组织格式为:
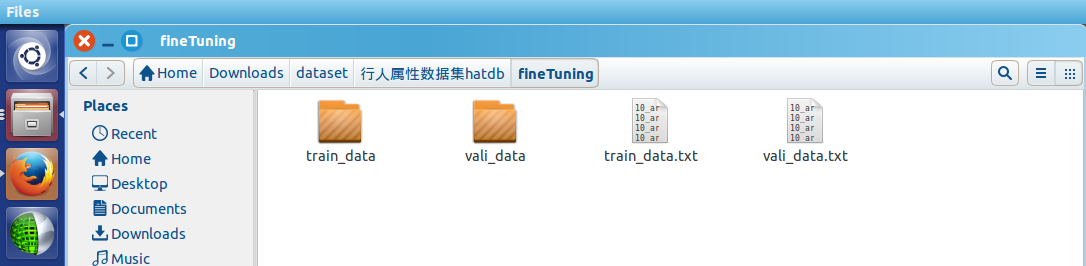
首先,所需要的脚本指令路径为:
/home/wangxiao/Downloads/caffe-master/examples/imagenet/
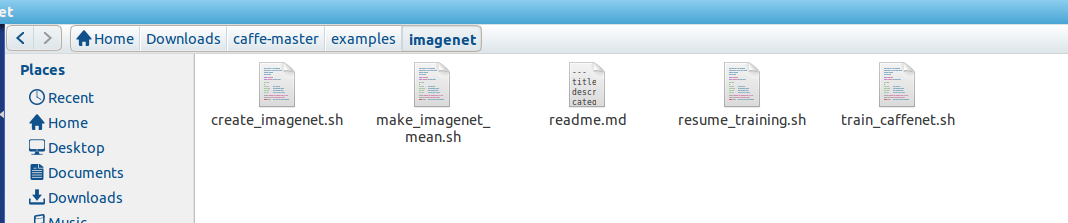
其中,生成lmdb的文件为: create_imagenet.sh
接下来的主要任务就是修改自己的data的存放路径了。
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs EXAMPLE=../wangxiao
DATA=../fine_tuning_data
TOOLS=../build/tools TRAIN_DATA_ROOT=../fine_tuning_data/training/data/
VAL_DATA_ROOT=../fine_tuning_data/validation/data/ #TRAIN_DATA_ROOT=/media/yukai/247317a3-e6b5-45d4-81d1-/---------------/Attribute reconginition/final_PETA_dataset/whole_benchmark/用于微调网络的数据/training/data/
#VAL_DATA_ROOT=/media/yukai/247317a3-e6b5-45d4-81d1-/---------------/Attribute reconginition/final_PETA_dataset/whole_benchmark/用于微调网络的数据/validation/data/ # Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool. # RESIZE=false default parameter and wangxiao modify it in 2015.10. : RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=
RESIZE_WIDTH=
else
RESIZE_HEIGHT=
RESIZE_WIDTH=
fi if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit
fi if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit
fi echo "Creating train lmdb..." GLOG_logtostderr= $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/training/final_train_data.txt \
$EXAMPLE/PETA_train_lmdb #echo "Creating val lmdb..." #GLOG_logtostderr= $TOOLS/convert_imageset \
# --resize_height=$RESIZE_HEIGHT \
# --resize_width=$RESIZE_WIDTH \
# --shuffle \
# $VAL_DATA_ROOT \
# $DATA/validation/final_test_data.txt \
# $EXAMPLE/PETA_val_lmdb echo "Done."
都修改完成后,在终端执行:create_imagenet.sh,然后会有如此的提示,表示正在生成lmdb文件:
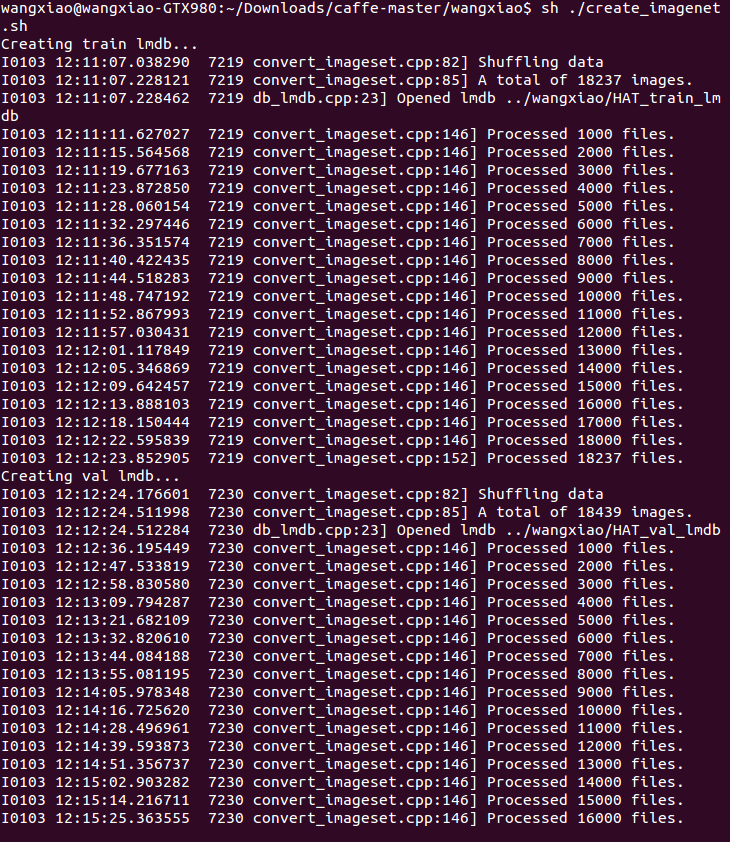
然后完成后,提示: Done. 然后可以看到已经生成了所需要的文件:

然后利用 make_imagenet_mean.sh 生成所需要的 mean file :
caffe-master$: sh ./make_imagenet_mean.sh
#!/usr/bin/env sh
# Compute the mean image from the imagenet training lmdb
# N.B. this is available in data/ilsvrc12 EXAMPLE=../wangxiao
DATA=./data
TOOLS=../build/tools #echo $TOOLS/compute_image_mean $EXAMPLE/HAT_train_lmdb \
# $DATA/HAT_mean.binaryproto
$TOOLS/compute_image_mean $EXAMPLE/HAT_train_lmdb \
$DATA/HAT_mean.binaryproto
echo "Done."
然后就生成了 HAT_mean.binaryproto
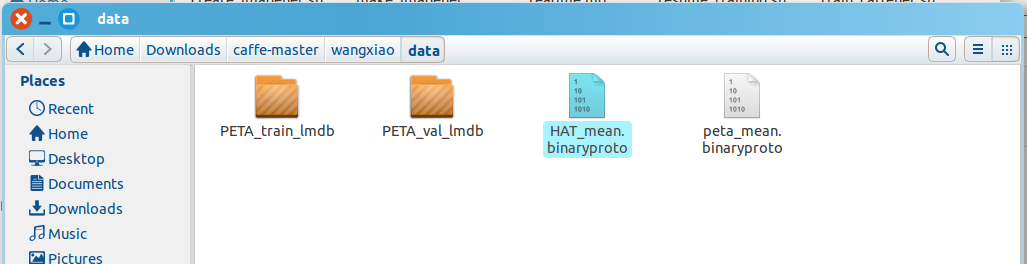
其中,caffe路径下:/home/wangxiao/Downloads/caffe-master/examples/imagenet/readme.md 对这个过程有一个详细的解释。
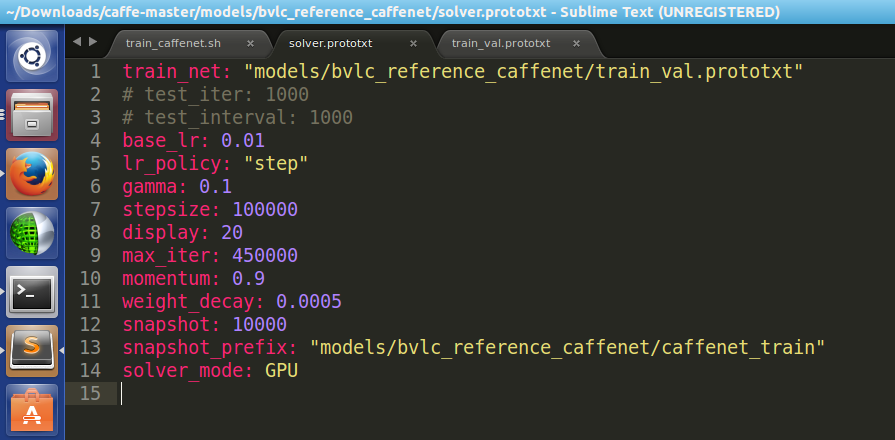
然后就是查看 solver.prototxt:

net: "models/bvlc_reference_caffenet/train_val.prototxt"
test_iter:
test_interval:
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize:
display:
max_iter:
momentum: 0.9
weight_decay: 0.0005
snapshot:
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU
打开 models/bvlc_reference_caffenet/train_val.prototxt
需要修改的也就到第55行:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size:
mean_file: "wangxiao/HAT_data/HAT_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size:
# mean_value:
# mean_value:
# mean_value:
# mirror: true
# }
data_param {
source: "wangxiao/HAT_data/HAT_train_lmdb"
batch_size:
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size:
mean_file: "wangxiao/HAT_data/HAT_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size:
# mean_value:
# mean_value:
# mean_value:
# mirror: true
# }
data_param {
source: "wangxiao/HAT_data/HAT_val_lmdb"
batch_size:
backend: LMDB
}
}
然后执行:
终端会有显示:
I0103 ::21.027832 net.cpp:] Network initialization done.
I0103 ::21.027839 net.cpp:] Memory required for data:
I0103 ::21.027928 solver.cpp:] Solver scaffolding done.
I0103 ::21.028312 caffe.cpp:] Starting Optimization
I0103 ::21.028326 solver.cpp:] Solving CaffeNet
I0103 ::21.028333 solver.cpp:] Learning Rate Policy: step
I0103 ::22.012593 solver.cpp:] Iteration , loss = 7.52783
I0103 ::22.012660 solver.cpp:] Train net output #: loss = 7.52783 (* = 7.52783 loss)
I0103 ::22.012687 solver.cpp:] Iteration , lr = 0.01
I0103 ::41.812361 solver.cpp:] Iteration , loss = 3.9723
I0103 ::41.812413 solver.cpp:] Train net output #: loss = 3.9723 (* = 3.9723 loss)
I0103 ::41.812428 solver.cpp:] Iteration , lr = 0.01
I0103 ::01.553021 solver.cpp:] Iteration , loss = 2.9715
I0103 ::01.553104 solver.cpp:] Train net output #: loss = 2.9715 (* = 2.9715 loss)
I0103 ::01.553119 solver.cpp:] Iteration , lr = 0.01
I0103 ::21.574745 solver.cpp:] Iteration , loss = 2.91547
I0103 ::21.574798 solver.cpp:] Train net output #: loss = 2.91547 (* = 2.91547 loss)
I0103 ::21.574811 solver.cpp:] Iteration , lr = 0.01
I0103 ::41.247493 solver.cpp:] Iteration , loss = 2.96451
I0103 ::41.247627 solver.cpp:] Train net output #: loss = 2.96451 (* = 2.96451 loss)
I0103 ::41.247642 solver.cpp:] Iteration , lr = 0.01
I0103 ::00.941267 solver.cpp:] Iteration , loss = 2.85887
I0103 ::00.941318 solver.cpp:] Train net output #: loss = 2.85887 (* = 2.85887 loss)
I0103 ::00.941332 solver.cpp:] Iteration , lr = 0.01
I0103 ::20.628329 solver.cpp:] Iteration , loss = 2.91318
I0103 ::20.628463 solver.cpp:] Train net output #: loss = 2.91318 (* = 2.91318 loss)
I0103 ::20.628476 solver.cpp:] Iteration , lr = 0.01
I0103 ::40.621937 solver.cpp:] Iteration , loss = 3.06499
I0103 ::40.621989 solver.cpp:] Train net output #: loss = 3.06499 (* = 3.06499 loss)
I0103 ::40.622004 solver.cpp:] Iteration , lr = 0.01
I0103 ::00.557921 solver.cpp:] Iteration , loss = 2.9818
I0103 ::00.558048 solver.cpp:] Train net output #: loss = 2.9818 (* = 2.9818 loss)
I0103 ::00.558063 solver.cpp:] Iteration , lr = 0.01
因为设置的迭代次数为: 450000次,所以,接下来就是睡觉了。。。O(∩_∩)O~ 感谢木得兄刚刚的帮助。
------ 未完待续------

另外就是,当loss 后期变化不大的时候,可以试着调整学习率, 在Solver.prototext中:
train_net: "models/bvlc_reference_caffenet/train_val.prototxt"
# test_iter:
# test_interval:
base_lr: 0.0001
lr_policy: "step"
gamma: 0.1
stepsize:
display:
max_iter:
momentum: 0.9
weight_decay: 0.0005
snapshot:
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU
base_lr: 0.0001 每次可以改为0.1×base_lr, 这里的 0.0001 是我两次调整之后的数值。
然后运行 resume_training.sh
#!/usr/bin/env sh ./build/tools/caffe train \
--solver=models/bvlc_reference_caffenet/solver.prototxt \
--snapshot=models/bvlc_reference_caffenet/caffenet_train_iter_88251.solverstate
将snapshot改为之前中断时的结果即可,即: caffenet_train_iter_88251.solverstate
继续看loss是否降低。。。
--------------------------------- 未完待续 ---------------------------------
利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning的更多相关文章
- (原)caffe中通过图像生成lmdb格式的数据
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5909121.html 参考网址: http://www.cnblogs.com/wangxiaocvp ...
- caffe生成voc格式lmdb
要训练ssd基本都是在liu wei框架下改,生成lmdb这一关照葫芦画瓢总遇坑,记录之: 1. labelmap_voc.prototxt要根据自己的分类修改,比如人脸检测改成这样: item { ...
- keil MDK中如何生成*.bin格式的文件
在Realview MDK的集成开发环境中,默认情况下可以生成*.axf格式的调试文件和*.hex格式的可执行文件.虽然这两个格式的文件非常有利于ULINK2仿真器的下载和调试,但是ADS的用户更习惯 ...
- 在MDK中怎样生成*.bin格式的文件?
在Realview MDK的集成开发环境中.默认情况下能够生成*.axf格式的调试文件和*.hex格式的可运行文件. 尽管这两个格式的文件很有利于ULINK2仿真器的下载和调试,可是ADS的用户更习惯 ...
- 【Linux_Fedora_应用系列】_3_如何利用Smplayer播放WMV格式的文件
在上一篇我们成功安装了视频播放器,并且成功安装里解码器[Linux_Fedora_应用系列]_2_如何安装视频播放器和视频文件解码 安装完的Smplayer的GUI的界面程序,可以播放FLV.AVI. ...
- 通过OpenSSL来生成二进制格式证书文件(pfx和cer)
1.生成RSA字符串私钥 genrsa -out private-rsa.key 2.由1中私钥导出*.cer二进制公钥文件 req -new -x509 -key private-rsa.key - ...
- python脚本从excel表到处数据,生成指定格式的文件
#coding:gbk #导入处理excel的模块 import xlrd #定义哪些字段须要推断,仅仅支持时间字段 toSureColArray = ['CREATE_TIME','MODIFY_T ...
- yii2 生成PDF格式的文件
1 .先把mpdf-development.zip解压的类文件夹放到vendor目录里面,重命名为mpdf 2 .在vendor/composer/autoload_namespaces.php里面添 ...
- Caffe︱构建lmdb数据集、binaryproto均值文件及各类难辨的文件路径名设置细解
Lmdb生成的过程简述 1.整理并约束尺寸,文件夹.图片放在不同的文件夹之下,注意图片的size需要规约到统一的格式,不然计算均值文件的时候会报错. 2.将内容生成列表放入txt文件中.两个txt文件 ...
随机推荐
- CSS Overflow:hidden
终于知道为什么要设置OverFlow:Hidden了, 看代码: <div id="wrapper"> <figure class="img-wrapp ...
- kali linux karmetasploit配置【续】
Karmetasploit In Action https://www.offensive-security.com/metasploit-unleashed/karmetasploit-action ...
- mp3文件 ID3v2 帧标识的含义
mp3文件 ID3v2 帧标识的含义 Declared ID3v2 frames The following frames are declared in this draft. 4.20 AENC ...
- 扩展jQuery easyui datagrid增加动态改变列编辑的类型
$.extend($.fn.datagrid.methods, { addEditor : function(jq, param) { if (param instanceof Array) { $. ...
- servlet容器处理请求过程
下图是关于tomcat服务器接收客户请求并作出响应的图例. tomcat不仅仅只是一个servlet容器,也是一个web服务器,servlet容器在web服务器之内或者说servlet容器托管于web ...
- javascript树形菜单简单实例
参考博客地址:http://chengyoyo2006.blog.163.com/blog/static/8451734820087843950604/ <!DOCTYPE HTML PUBLI ...
- 进行以上Java编译的时候,出现unmappable character for encoding GBK。
public class Exerc02{ public static void main(String args []){ char c = '中国人'; System.out.pingtln(c) ...
- HDU 5253 最小生成树(kruskal)+ 并查集
题目链接 #include<cstdio> #include<cmath> #include<cstring> #include<algorithm> ...
- Java 集合深入理解(13):Stack 栈
点击查看 Java 集合框架深入理解 系列, - ( ゜- ゜)つロ 乾杯~ 今天心情不错,再来一篇 Stack ! 数据结构中的 栈 数据结构中,栈是一种线性数据结构,遵从 LIFO(后进先出)的操 ...
- 为什么有的代码要用 base64 进行编码
一.1.传输信道只支持ASCII字符,不方便传输二进制流的场合. 2.含有非ASCII字符,容易出现编码问题的场合. 3.简易的掩人耳目.至少非开发人一眼看不出来是啥. 二.Base64主要用于将不可 ...