Hadoop数据传输工具:Sqoop
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。除了这些主要的功能外,Sqoop 也提供了一些诸如查看数据库表等实用的小工具。理论上,Sqoop 支持任何一款支持 JDBC 规范的数据库,如 DB2、MySQL 等。Sqoop 还能够将 DB2 数据库的数据导入到 HDFS 上,并保存为多种文件类型。常见的有定界文本类型,Avro 二进制类型以及 SequenceFiles 类型。在本文里,统一用定界文本类型。

Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。
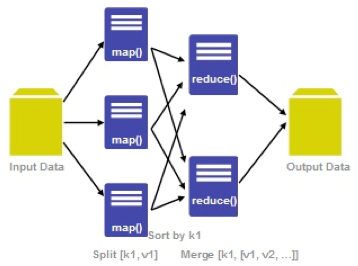
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
Sqoop大概流程
- 读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
- 设置好job,主要也就是设置好以上第六章中的各个参数
- 这里就由Hadoop来执行MapReduce来执行Import命令
1) 首先要对数据进行切分,也就是DataSplit,DataDrivenDBInputFormat.getSplits(JobContext job)
2) 切分好范围后,写入范围,以便读取DataDrivenDBInputFormat.write(DataOutput output),这里是lowerBoundQuery and upperBoundQuery
3) 读取以上2)写入的范围DataDrivenDBInputFormat.readFields(DataInput input)
4) 然后创建RecordReader从数据库中读取数据DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)
5) 创建MAP,MapTextImportMapper.setup(Context context)
6) RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给MapDBRecordReader.nextKeyValue()
7) 运行MAP,mapTextImportMapper.map(LongWritable key, SqoopRecord val, Context context),最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()
Sqoop1和Sqoop 2架构的变迁
首先这两个版本是完全不兼容的,其具体的版本号区别为1.4.x为sqoop 1,1.99x为sqoop 2。sqoop1和sqoop2在架构和用法上已经完全不同。在架构上,sqoop1仅仅使用一个sqoop客户端,sqoop2引入了sqoop server,对connector实现了集中的管理。其访问方式也变得多样化了,其可以通过REST API、JAVA API、WEB UI以及CLI控制台方式进行访问。另外,其在安全性能方面也有一定的改善,在sqoop1中我们经常用脚本的方式将HDFS中的数据导入到mysql中,或者反过来将mysql数据导入到HDFS中,其中在脚本里边都要显示指定mysql数据库的用户名和密码的,安全性做的不是太完善。在sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到,同时Sqoop2引入基于角色的安全机制。下图是sqoop1和sqoop2简单架构对比:
Sqoop1架构图:

Sqoop2架构图:
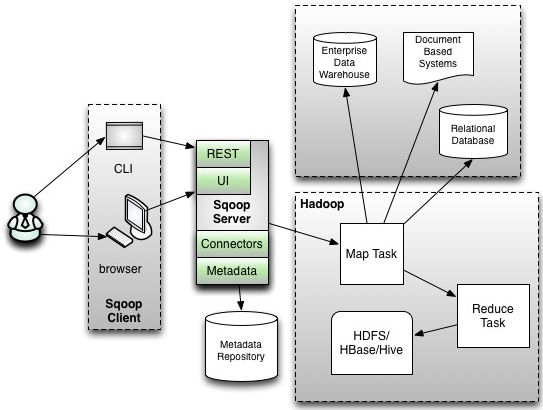
- sqoop1优点:架构部署简单
- sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏, 安装需要root权限,connector必须符合JDBC模型
- sqoop2优点:多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
- sqoop2缺点:架构稍复杂,配置部署更繁琐
参考链接:
- https://blogs.apache.org/sqoop/entry/apache_sqoop_highlights_of_sqoop
- http://www.slideshare.net/cloudera/apache-sqoop-a-data-transfer-tool-for-hadoop
- http://www.slideshare.net/Hadoop_Summit/new-data-transfer-tools-for-hadoop
Hadoop数据传输工具:Sqoop的更多相关文章
- 数据集成工具—Sqoop
数据集成/采集/同步工具 @ 目录 数据集成/采集/同步工具 Sqoop简介 Sqoop安装 1.上传并解压 2.修改文件夹名字 3.修改配置文件 4.修改环境变量 5.添加MySQL连接驱动 6.测 ...
- 转载:Hadoop排序工具用法小结
本文转载自Silhouette的文章,原文地址:http://www.dreamingfish123.info/?p=1102 Hadoop排序工具用法小结 发表于 2014 年 8 月 25 日 由 ...
- linux rsync-文件同步和数据传输工具
一.rsync的概述 rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync.rsync是Linux系统下的文件同步和数据传输工具,它采用“rsync” ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- 关系数据库数据与hadoop数据进行转换的工具 - Sqoop
Sqoop 本文所使用的Sqoop版本为1.4.6 1.官网 http://sqoop.apache.org 2.作用 A:可以把hadoop数据导入到关系数据库里面(e.g. Hive -> ...
- 《OD学Sqoop》数据转换工具Sqoop
一. 第二阶段课程回顾 hadoop 2.x HDFS YARN MapReduce Zookeeper Hive 二.大数据协作框架 对日志类型的海量数据进行分析 hdfs mapreduce/hi ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- (第7篇)灵活易用易维护的hadoop数据仓库工具——Hive
摘要: Hive灵活易用且易于维护,十分适合数据仓库的统计分析,什么样的结构让它具备这些特性?我们如何才能灵活操作hive呢? 博主福利 给大家推荐一套hadoop视频课程 [百度hadoop核心架构 ...
随机推荐
- Mac OS X中配置Apache
我使用的Mac OS X版本是10.8.2,Mac自带了Apache环境. 启动Apache 设置虚拟主机 启动Apache 打开“终端(terminal)”,输入 sudo apachectl -v ...
- iOS平台XML解析类库对比和安装说明
在iPhone开发中,XML的解析有很多选择,iOS SDK提供了NSXMLParser和libxml2两个类库,另外还有很多第三方类库可选,例如TBXML.TouchXML.KissXML.Tiny ...
- Redis 3.0 集群搭建
Redis 3.0 集群搭建 开启两个虚拟机 分别在两个虚拟机上开启3个Redis实例 3主3从两个虚拟机里的实例互为主备 下面分别在两个虚拟机上安装,网络设置参照codis集群的前两个主机 分别关闭 ...
- OpenFlow Switch学习笔记(四)——Matching
这次我们着重详述来自于网络中的数据包在OpenFlow Switch中与Flow Entries的具体匹配过程,以及当出现Table Miss时的处理方式,下面就将从这两方面说起. 1.Matchin ...
- 关于java“配置环境变量”的那些事
我们刚开始学习java,都会面临编程路上的第一个小怪兽:配环境变量. 网上很多教程给了我们很多的参考,但我们是否有想过为什么要这么配呢?下面我就是想重点探讨一下为什么?并且希望以后你们不但能配,还知道 ...
- Codeforces Round #369 (Div. 2) A B 暴力 模拟
A. Bus to Udayland time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- bootstrap-3
段落: 1.全局文本字号为14px(font-size); 2.行高为1.42857143(line-height),大约是20px(一串数字是由less编译器计算出来的,当然sass也有这样的功能) ...
- iframe与frameset(转载)
frameset 在一个页面中设置一个或多个框架 不能嵌套在body标签里 frameset 它称为框架标记,是用来告知HTML文件是框架模式,并且设定可视窗口怎么分割 fram ...
- mysql in和or查询效率
http://blog.chinaunix.net/uid-20639775-id-3416737.html 上面链接博主的文章分析结论: or在没有索引的情况下呈指数增长,in则是正常递增. or的 ...
- Codeforces Round #118 (Div. 2)
A. Comparing Strings 判断不同的位置个数以及交换后是否相等. B. Growing Mushrooms 模拟. C. Plant 矩阵+快速幂 D. Mushroom Scient ...