开源版本 hadoop-2.7.5 + apache-hive-2.1.1 + spark-2.3.0-bin-hadoop2.7整合使用
一,开源软件版本:
hadoop版本 : hadoop-2.7.5
hive版本 :apache-hive-2.1.1
spark版本: spark-2.3.0-bin-hadoop2.7
各个版本到官网下载就ok,注意的是版本之间的匹配
机器介绍,三台机器,第一台canal1为主节点+工作节点,另两台为工作节点:
10.40.20.42 canal1
10.40.20.43 canal2
10.40.20.44 canal3
二.搭建hadoop集群
1.配置环境变量 vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
export HIVE_HOME=/opt/apache-hive-1.2.2
export PATH=$PATH:$HIVE_HOME/bin
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export SPARK_HOME=/opt/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
2.修改hadoop配置文件
core-site.xml
---------------------------------------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://canal1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
yarn-site.xml
---------------------------------------------------------------
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>canal1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hdfs-site.xml
-------------------------------------------------------------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
----------------------------------------------------------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置好以上文件后,复制到所有节点的配置文件,然后格式化namenode
hadoop namenode -format;
创建相应目录:
1020 hdfs dfs -mkdir -p /user/hive/tmp
1021 hdfs dfs -mkdir -p /user/hive/log
1022 hdfs dfs -chmod -R 777 /user/hive/tmp
1023 hdfs dfs -chmod -R 777 /user/hive/log
至此,可以启动hadoop集群了(非ha),到hadoop安装目录执行./start-all.sh,根据输出可以看到启动了哪些角色:
[root@canal1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [canal1]
canal1: starting namenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-namenode-canal1.out
canal1: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal1.out
canal2: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal2.out
canal3: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-canal1.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-resourcemanager-canal1.out
canal1: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal1.out
canal3: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal3.out
canal2: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal2.out
三.搭建spark集群
1,将安装包解压到各个节点,更改配置文件,主要有slaves文件和spark-env.sh文件
[root@canal3 conf]# cat slaves
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
canal1
canal2
canal3
-----------------------------------------------------------------------------------------------------------------------
已经将export SPARK_CLASSPATH=$HIVE_HOME/lib/mysql-connector-java-5.1.46-bin.jar加在spark-env.sh中
2.启动集群,spark中分为两种角色,master和worker,进程名字也是这个:
到spark安装目录下的sbin目录,启动 ./start-all.sh ,然后jps(spark默认为是在执行这个命令的节点上启动一个master,
其余都是workder,要想在其他节点也启动master,比如做 spark master的ha,可以执行 ./start-master.sh),然后jps
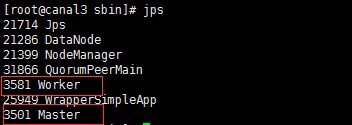
至此,spark集群也起来了;
四.安装hive,并整合到hadoop:
1.hive只要选一个节点,我这里是canal1节点,解压,安装,配置换机变量;
hive-site.xml
---------------------------------------------------------------------------------------------------
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://canal1:8020/user/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://canal1:8020/user/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>hdfs://canal1:8020/user/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://canal2:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
------------------------------------------------------------------------------------------------------------------------------------------------------
编辑hive-env.sh,添加
export JAVA_HOME=/usr/java/jdk1.8.0_121 ##Java路径
export HADOOP_HOME=/opt/hadoop-2.7.5 ##Hadoop安装路径
export HIVE_HOME=/opt/apache-hive-2.1.1 ##Hive安装路径
2.添加hive连接mysql驱动:
下载 mysql-connector-java-5.1.46,解压,将mysql-connector-java-5.1.46-bin.jar复制到hive安装目录下的lib;
3.执行hive metastore database初始化:
schematool -initSchema -dbType mysql
4.启动hive
五.整合到spark
将hive-site.xml文件复制到所有spark安装目录下的conf文件夹
cp hive-site.xml /opt/spark-2.3.0-bin-hadoop2.7/conf/
scp hive-site.xml canal2:/opt/spark-2.3.0-bin-hadoop2.7/conf/
scp hive-site.xml canal3:/opt/spark-2.3.0-bin-hadoop2.7/conf/
至此,hadoop+hive+spark整合完毕
六,测试
在hive客户端创建表;
create table gong_from_hive(id int,name string,location string) row format delimited fields terminated by ",";
insert into gong_from_hive values(1,"gongxxxxxeng","shanghai");
转到sparlk下bin目录下,执行 ./spark-sql,show tables:
spark-sql> show tables;
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_database: default
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: default
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_database: default
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: default
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_tables: db=default pat=*
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_tables: db=default pat=*
default gong_from_hive false
default gong_from_spark false
Time taken: 0.071 seconds, Fetched 2 row(s)
2018-05-14 13:52:59 INFO SparkSQLCLIDriver:951 - Time taken: 0.071 seconds, Fetched 2 row(s)
可以看到在hive客户端创建的表,查询表:
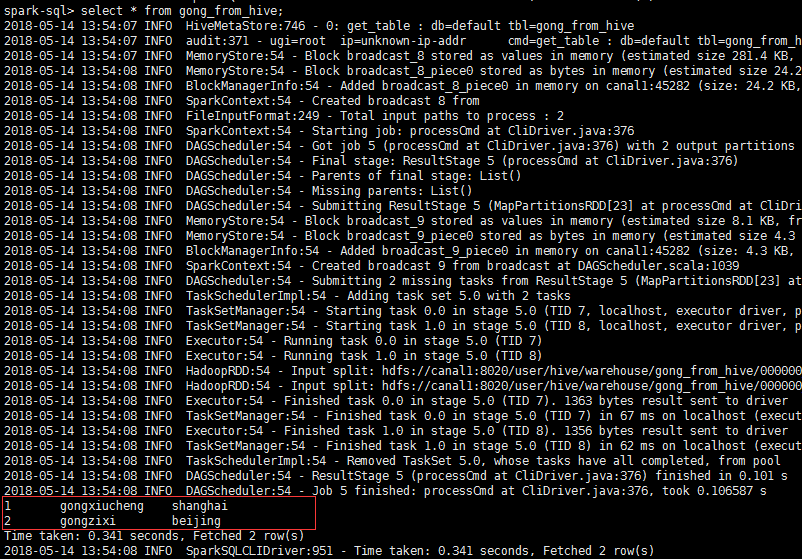
可以看到hive记录;
在spark sql客户端建表:
spark-sql> create table gong_from_spark(id int,name string,location string) row format delimited fields terminated by ",";
可以成功,测试插入也ok;
还可以去测试 spark-submit模式,spark-shell模式提交job运行情况;
七,报错问题总结:
1.java.net.ConnectException: Call From localhost/127.0.0.1 to localhost:8020 failed on connection
2.The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH 或
The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
找不到jdbc驱动;
3.hive默认数据库是derby,替换为mysql,解决只能一个客户端去连接的问题;
./spark-submit --master yarn --deploy-mode cluster --conf spark.driver.memory=4g --class org.apache.spark.examples.SparkPi --executor-cores 4 --queue myqueue ../examples/jars/spark-examples_2.11-2.3.0.jar 10
4.MetaException(message:Hive Schema version 2.1.0 does not match metastore's schema version 1.2.0 Metastore is not upgraded or corrupt
解决方案:
1.登陆mysql,修改hive metastore版本:
进行mysql:mysql -uroot -p (123456)
use hive;
select * from version;
update VERSION set SCHEMA_VERSION='2.1.0' where VER_ID=1;2.简单粗暴:在hvie-site.xml中关闭版本验证
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>开源版本 hadoop-2.7.5 + apache-hive-2.1.1 + spark-2.3.0-bin-hadoop2.7整合使用的更多相关文章
- 在Hadoop集群上的Hive配置
1. 系统环境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111 hadoop集群master:192.168.19.128slave ...
- Hive JDBC:java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous
今天使用JDBC来操作Hive时,首先启动了hive远程服务模式:hiveserver2 &(表示后台运行),然后到eclipse中运行程序时出现错误: java.sql.SQLExcepti ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Hive执行count函数失败,Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException)
Hive执行count函数失败 1.现象: 0: jdbc:hive2://192.168.137.12:10000> select count(*) from emp; INFO : Numb ...
- Hadoop第9周练习—Hive部署测试(含MySql部署)
1.1 2 :搭建Hive环境 内容 2.2 3 运行环境说明 1.1 硬软件环境 线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 build-8 ...
- Apache Hive 基本理论与安装指南
一.Hive的基本理论 Hive是在HDFS之上的架构,Hive中含有其自身的组件,解释器.编译器.执行器.优化器.解释器用于对脚本进行解释,编译器是对高级语言代码进行编译,执行器是对java代码的执 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- 大数据Hadoop生态圈:Pig和Hive
前言 Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache的一个项目,由Apache来负责维护,Pig是一个基于 Hadoop的大规模数据分析平台. Pi ...
随机推荐
- Netbackup客户端安装网络放通端口需求,及测试网络放通方法
192.168.1.101网络放通需求如下: 客户端主机 192.168.1.101 到 服务端主机 192.168.1.100 的1556.13720.13724.1378.13782这5个 ...
- Vue.js系列之vue-resource(6)
网址:http://blog.csdn.net/u013778905/article/details/54235906
- deep learning学习记录二
接着我的微博继续八卦吧 微博里问了几个人,关于deep learning和cnn的区别,有不少热心网友给了回答,非常感谢.结合我听课和看文章的理解,我大胆大概总结一下: 在上世纪90年代,neural ...
- LeetCode12.整数转罗马数字 JavaScript
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并 ...
- Question20180106 Java环境变量的配置及为什么要配置环境变量
Question 1 Java环境变量的配置及为什么要配置环境变量 Q1.1为什么要配置环境变量 在学习JAVA的过程中,涉及到多个环境变量(environment variable)的概念,如PA ...
- Unity 游戏框架搭建 (十一) 简易AssetBundle打包工具(一)
最近在看Unity官方的AssetBundle(以下简称AB)的教程,也照着做了一遍,不过做出来的AssetBundleManager的API设计得有些不太习惯.目前想到了一个可行的解决方案.AB相关 ...
- flex布局——回顾
flex 即为弹性布局. 任何一个容器都可以指定为flex布局. .box{display:flex} 行内元素可以使用flex布局 .box{display: inline-flex} webkit ...
- 2018 Wannafly summer camp Day2--New Game!
New Game! 描述 题目描述: Eagle Jump公司正在开发一款新的游戏.泷本一二三作为其员工,获得了提前试玩的机会.现在她正在试图通过一个迷宫. 这个迷宫有一些特点.为了方便描述,我们对这 ...
- 【解题报告】小白逛公园 vijos
题目传送门 这道题是一道线段树的一个求一个连续最大字段和是一个区间线段树一个很妙妙的操作,这里后面我们后面就会提到,因为今天博主没有时间了所以先粘一篇代码供大家参考,其实代码理解还是非常的简单的. 代 ...
- EF core 中用lambda表达式和Linq的一些区别
转眼一看,又过了10几天没有写博客了,主要还是没有什么可以写的,因为遇到的问题都不是很有价值.不过最近发现用lambda表达式,比用Linq的代码量会少一些,而且也方便一些.不过两者都差不多,相差不是 ...