《Deep learning》第四章——数值计算
数值计算
机器学习算法通常需要大量的数值计算。这通常是指通过迭代过程更新解的估计值来解决数学问题的算法,而不是通过解析过程推导出公式来提供正确解的方法。常见的操作包括优化(找到最小化或最大化函数值的参数)和线性方程组的求解。
上溢和下溢
连续数学在数字计算机上的根本困难是,我们需要通过有限数量的位模式来表示无限多的实数。这意味着我们在计算机中表示实数时,几乎总会引入一些近似误差。在许多情况下,这仅仅是舍入误差。舍入误差会导致一些问题,特别是当许多操作复合时,即使是理论上可行的算法,如果在设计时没有考虑最小化舍入误差的累积,在实践时也可能会导致算法失效。
一种舍入误差是下溢。当接近零的数被四舍五入为零时发生下溢。许多函数在其参数为零而不是一个很小的正数时才会表现出质的不同。
另一种舍入误差是上溢。当大量级的数被近似为∞或-∞时发生上溢。进一步的运算通常会导致这些无限值变为非数字。
必须对上溢和下溢进行数值稳定的一个例子是softmax函数
病态条件
条件数:函数相对于输入的微小变化而变化的快慢程度。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。
考虑函数f(x)=A-1 x.当A∈Rn×n具有特征值分解时,其条件数为max|λi/λj|.这是最大和最小特征值的模之比。当该数很大时,矩阵求逆对输入的误差特别敏感。
这种敏感性是矩阵本身的固有特性,而不是矩阵求逆期间舍入误差的结果。即使我们乘以完全正确的矩阵逆,病态条件的矩阵也会放大预先存在的误差。
基于梯度的优化方法
大多数深度学习算法都涉及某种形式的优化。优化指的是改变x以最小化或者最大化某个函数f(x)的任务。
我们把要最小化或最大化的函数称为目标函数或准则,当我们对其进行最小化时,也把它称为代价函数、损失函数或误差函数。
我们常用一个上标*表示最小化或最大化函数的x值,如记x*=argminf(x)
当f’(x)=0时,导数无法提供往哪个方向移动的信息。f’(x)=0的点称为临界点或驻点。一个局部极小点意味着这个点的f(x)小于所有临近点,因此不可能通过移动无穷小的步长来减少f(x)。一个局部极大点意味着这个点的f(x)大于所有邻近点,因此不可能通过移动无穷小的步长来增大f(x)。有些临近点既不是最小点也不是最大点,这些点称为鞍点。
使f(x)取得绝对的最小值(相对其他所有值)的点是全局最小点。函数可能只有一个全局最小点或存在多个全局最小点,还可能存在不是全局最优的全局极小点。在深度学习的背景下,我们要优化的函数可能含有许多不是最优的全局极小点,或者还有很多处于非常平坦的区域内的鞍点。尤其是当输入是多维的时候,所有这些都将使优化变得困难。
针对具有多维输入的函数,我们需要用到偏导数的概念。偏导数衡量点x处只有xi增加时f(x)如何变化。梯度是相对于一个向量求导的导数:f的导数是包含所有偏导数的向量:记为▽xf(x).
在u(单位向量)方向的方向导数是函数f在u方向的斜率。换句话说,方向导数是函数f(x+αu)关于α的导数(在α=0时取得)。
为了最小化f,我们希望找到使f下降得最快的方向。计算方向导数
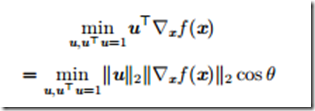
显然在u与梯度方向相反时取得最小。
最速下降/梯度下降:
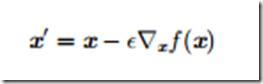
最速下降在梯度的每一个元素为0时收敛,在某些情况下,我们也许能够避免运行该迭代算法,并通过解方程▽xf(x)=0直接跳到临近点。
Jacobian和Hessian矩阵
有时我们需要计算输入和输出都为向量的函数的所有偏导数。包含所有这样的偏导数的矩阵被称为Jacobian矩阵。具体来说,如果我们有一个函数f:Rm——>Rn,f的Jacobian矩阵J∈Rn×m定义为Ji,j
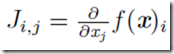 这里是用到一阶导
这里是用到一阶导
有时我们也对二阶导数感兴趣,这就用到了Hessian矩阵
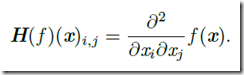
Hessian矩阵等于梯度的Jacobian矩阵。
微分算子在任何二阶偏导连续的点处可交换,也就是他们的顺序可以互换:
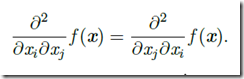
因此Hessian矩阵在这些点上是对称的。在深度学习背景下,我们遇到的大多数函数的Hessian几乎处处都是对称的。因为Hessian矩阵是实对称的,我们可以将其分解成一组实特征值和一组特征向量的正交基。在特定方向d上的二阶导数可以写成dTHd.当d是H的一个特征向量时,这个方向的二阶导数就是对应的特征值。对于其他的方向d,方向二阶导数是所有特征值的加权平均,权重在0和1之间,且与d夹角越小的特征向量的权重越大。最大特征值确定最大二阶导数,最小特征值确定最小二阶导数。
我们可以通过(方向)二阶导数预期一个梯度下降步骤能表现得多好。我们在当前点x(0)处做函数f(x)的近似二阶泰勒级数:




仅使用梯度信息的优化算法称为一阶优化算法,如梯度下降。使用Hessian矩阵的优化算法被称为二阶最优化算法,如牛顿法。
因为在深度学习中使用的函数族是相当复杂的,所以深度学习算法往往缺乏保证。在许多其他领域,优化的主要方法是为有限的函数族设计优化算法。
在深度学习背景下,限制函数满足Lipschitz连续或其导数Lipschitz连续可以获得一些保证。Lipschitz连续函数的变化速度以Lipschitz常数L为界:
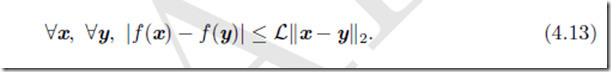
这个属性允许我们量化我们的假设——梯度下降等算法导致的输入的微小变化将使输出只产生微小变化,因此是很有用的。Lipschitz连续性也是相当弱的约束,并且深度学习中很多优化问题经过相对较小的修改后就能变得Lipschitz连续。
最成功的特定优化领域或许是凸优化。凸优化通过更强的限制提供更多的保证。凸优化算法只对凸函数适用,即Hessian处处半正定的函数。因为这些函数没有鞍点而且其所有局部极小点必然是全局最小点,所以表现很好。然而,深度学习中的大多数问题都难以表示成凸优化的形式。凸优化仅用作一些深度学习算法的子程序。凸优化中的分析思路对证明深度学习算法的收敛性非常有用,然而一般来说,深度学习背景下凸优化重要性大大减少。
约束优化
有时候,在x的所有可能值下最大化或最小化一个函数f(x)不是我们所希望的。相反,我们可能希望在x的某些集合S中找f(x)的最大值或最小值。这被称为约束优化。在约束优化术语中,集合S内的点x被称为可行点。
我们常常希望找到在某种意义上小的解。针对这种情况下的常见方法是强加一个范数约束,如||x||≤1



《Deep learning》第四章——数值计算的更多相关文章
- Deep learning:四十六(DropConnect简单理解)
和maxout(maxout简单理解)一样,DropConnect也是在ICML2013上发表的,同样也是为了提高Deep Network的泛化能力的,两者都号称是对Dropout(Dropout简单 ...
- Deep learning:四十二(Denoise Autoencoder简单理解)
前言: 当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Be ...
- Deep learning:四十九(RNN-RBM简单理解)
前言: 本文主要是bengio的deep learning tutorial教程主页中最后一个sample:rnn-rbm in polyphonic music. 即用RNN-RBM来model复调 ...
- Deep learning:四十三(用Hessian Free方法训练Deep Network)
目前,深度网络(Deep Nets)权值训练的主流方法还是梯度下降法(结合BP算法),当然在此之前可以用无监督的方法(比如说RBM,Autoencoder)来预训练参数的权值,而梯度下降法应用在深度网 ...
- Deep learning:四十一(Dropout简单理解)
前言 训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择.Dropout是hintion最近2年提出的,源于其文章Improving neural n ...
- Deep learning:四十(龙星计划2013深度学习课程小总结)
头脑一热,坐几十个小时的硬座北上去天津大学去听了门4天的深度学习课程,课程预先的计划内容见:http://cs.tju.edu.cn/web/courseIntro.html.上课老师为微软研究院的大 ...
- Deep learning:四十八(Contractive AutoEncoder简单理解)
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?).通常情况下,对权值进行惩罚后的a ...
- Deep learning:四十四(Pylearn2中的Quick-start例子)
前言: 听说Pylearn2是个蛮适合搞深度学习的库,它建立在Theano之上,支持GPU(估计得以后工作才玩这个,现在木有这个硬件条件)运算,由DL大牛Bengio小组弄出来的,再加上Pylearn ...
- Deep learning:四十七(Stochastic Pooling简单理解)
CNN中卷积完后有个步骤叫pooling, 在ICLR2013上,作者Zeiler提出了另一种pooling手段(最常见的就是mean-pooling和max-pooling),叫stochastic ...
随机推荐
- useradd命令
◆useradd 1.作用 useradd命令用来建立用户帐号和创建用户的起始目录,使用权限是超级用户. 2.格式 useradd [-d home] [-s shell] [-c comment] ...
- NIO之Channel聚集(gather)写入与分散(scatter)读取
Channel聚集(gather)写入 聚集写入( Gathering Writes)是指将多个 Buffer 中的数据“聚集”到 Channel. 特别注意:按照缓冲区的顺序,写入 position ...
- CAN总线过滤规则
奇怪的设计 If (AFMR & Message_ID) == (AFMR & AFIR) then Capture Message AFIR 1 接收 AFMR 0 接收 设置某接收 ...
- 使用wget工具抓取网页和图片 成功尝试
使用wget工具抓取网页和图片 发表于1年前(2014-12-17 11:29) 阅读(2471) | 评论(14) 85人收藏此文章, 我要收藏 赞7 wget 网页抓取 图片抓取 目录[-] ...
- SpringMVC学习(一)小demo
首先看一下整个demo的项目结构: 第一步是导入Spring MVC单独使用时的最少jar包: 第二步在项目的web.xml中配置Spring MVC提供的拦截请求的Servlet: 全类名是:org ...
- centos6.5下redis集群配置(多机多节点)
可参考官网文档:redis集群配置 需要注意的是,集群中的每个节点都会涉及到两个端口,一个是用于处理客户端操作的(如下介绍到的6379/6380),另一个是10000+{监听端口},用于集群各个节点间 ...
- 华为终端开放实验室Android Beta 4测试能力上线
7月26日,Android P Beta 4发布(即Android P DP5),此版本为开发者最后一个预览版本,也预示着Android P正式版即将与大家见面. 为保证开发者在正式版本来临前做 ...
- Android startActivity()和onActivityResult()使用总结(转载)
有三个Activity: A.java ,B.java ,C.java Activity之间的跳转常用方法: 1. startActivity(Intent intent); 该方法只用于启动新的Ac ...
- java 获取网页指定内容
import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; ...
- Asp.net 基于Cookie简易的权限判断
基于Cookie简易的权限判断代码,需要的朋友可以参考下. 写入Cookie页面,创建cookie后,设置cookie属性,并添加到Response.Cookies中读取cookie,利用cookie ...