hive的体系架构及安装
1,什么是Hive?
Hive是能够用类SQL的方式操作HDFS里面数据一个数据仓库的框架,这个类SQL我们称之为HQL(Hive Query Language)
2,什么是数据仓库?
存放数据的地方
3,Hive的特征
海量数据的存储
海量数据的查询
不支持事务性操作
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
4,Hive中的概念和HDFS里面概念的对应
Hive中的表----HDFS里面的目录
Hive中的表中的数据----HDFS目录下的(数据)文件
Hive中的行列----HDFS数据文件中的行列
部署时不一定放在集群管理节点中,可以放在某个节点上
5,Hive的数据存储
Hive的数据存储基于Hadoop HDFS
Hive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图、索引
Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile
创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
6,Hive的提供架构
用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行,JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问 Hive
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
7,Hive的元数据Metastore
metastore是hive元数据的集中存放地。
metastore默认使用内嵌的derby数据库作为存储引擎
Derby引擎的缺点:一次只能打开一个会话
使用MySQL作为外置存储引擎,多用户同时访问
Ubuntu下MYSQL的安装
1、查看mysql的依赖
rpm -qa | grep mysql
无依赖
如果有,删除mysql的依赖
rpm -e --nodeps `rpm -qa | grep mysql`
或者
rpm -e --nodeps `rpm -qa | grep MySQL`
2、在线安装mysql
apt-get install mysql-server
apt-get install mysql-client
启动:
mysql -u root -p
------------------
中间遇到了dpkt的问题,但是忘记截图了,下次碰到了再补上吧
Ubuntu下hive的安装
1,上传tar包,解压
tar -zxvf apache-hive-0.14.-bin.tar.gz
2,更名
mv apache-hive-0.14.-bin hive-0.14.
3,备份配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
4,修改hive-env.sh配置文件
增加内容如下:
JAVA_HOME=/usr/local/jdk1..0_91
HADOOP_HOME=/usr/local/hadoop-2.6.
HIVE_HOME=/usr/local/hive-0.14.
5,修改hive-site.xml文件
首先需要在mysql下新建一个database
启动mysql:
mysql -u root -p
查看有哪些database:
show databases; //不要掉了;分号
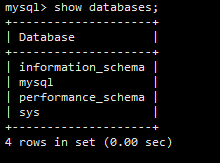
新建database:
create database sql_hive;
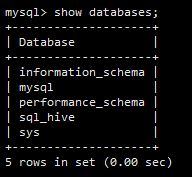
再修改hive的配置文件hive-site.xm:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Ubuntu-1:3306/sql_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive-0.14./tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-0.14./tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive-0.14./tmp</value>
</property>
6,将mysql中的mysql-connector-java-5.1.17.jar上传到hive的lib目录下
我在mysql的文件中没有找到该目录,所以直接上传的
7,启动Hive
./hive <==>等价于
./hive --service cli
报错:
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
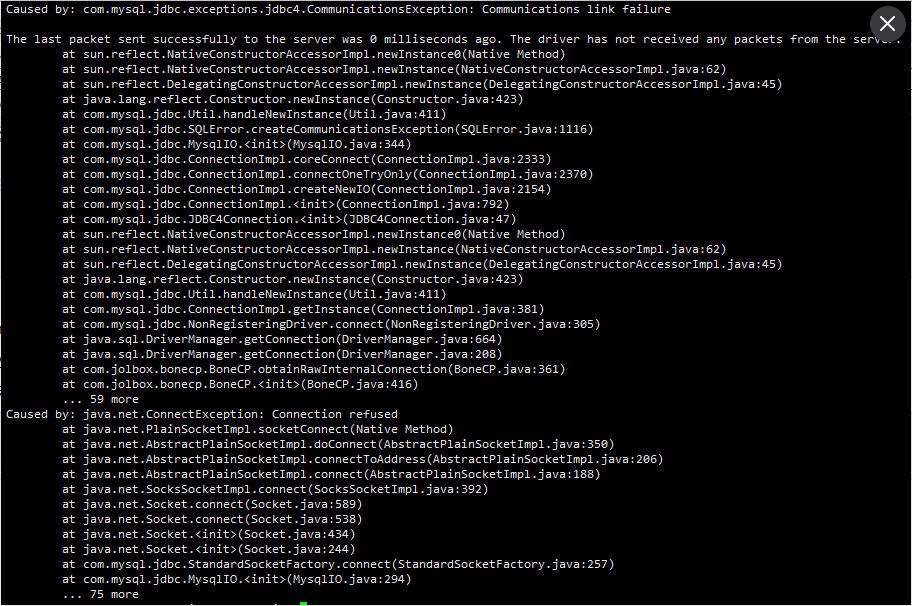
报错原因:
未开启mysql的3306端口进行远程访问
解决办法:
1,查看3306端口是否正常
netstat -an | grep

现在的3306端口绑定的IP地址是本地的127.0.0.1
2,修改Mysql配置文件
vi /etc/mysql/mysql.conf.d/mysqld.cnf
找到
bind-address = 127.0.0.1
前面加#注释掉
3,重启Mysql
/etc/init.d/mysql restart
4,再次查看端口信息
netstat -an | grep

5,
telnet 192.168.22.131

6,开启hive

成功
hive的体系架构及安装的更多相关文章
- (转)关于Tomcat的点点滴滴(体系架构、处理http请求的过程、安装和配置、目录结构、设置压缩和对中文文件名的支持、以及Catalina这个名字的由来……等)
转自:http://itfish.net/article/41668.html 总结Tomcat的体系架构.处理http请求的过程.安装和配置.目录结构.设置压缩和对中文文件名的支持.以及Cata ...
- HBase体系架构和集群安装
大家好,今天分享的是HBase体系架构和HBase集群安装.承接上两篇文章<HBase简介>和<HBase数据模型>,点击回顾这2篇文章,有助于更好地理解本文. 一.HBase ...
- 关于Tomcat的点点滴滴(体系架构、处理http请求的过程、安装和配置、文件夹结构、设置压缩和对中文文件名称的支持、以及Catalina这个名字的由来……等)
总结Tomcat的体系架构.处理http请求的过程.安装和配置.文件夹结构.设置压缩和对中文文件名称的支持.以及Catalina这个名字的由来--等. Tomcat和JVM: 一个Tomcat仅仅会启 ...
- 【转】XenServer体系架构解析
XenServer是一套已在云计算环境中经过验证的企业级开放式服务器虚拟化解决方案,可以将静态.复杂的IT环境转变为更加动态.易于管理的虚拟数据中心,从而大大降低数据中心成本.同时,它可以提供先进的管 ...
- SaaS系列介绍之十三: SaaS系统体系架构
1 系统体系架构设计 软件开发中系统体系架构决定了一个系统稳定性.健壮性.可扩展性.兼容性和可用性,它是系统的灵魂.体系架构是架构师所关注的核心.良好的体系架构是系统成功的开端,否则,再好的代码与设计 ...
- 基于物联网操作系统HelloX的智慧家庭体系架构
基于物联网操作系统HelloX的智慧家庭体系架构 智慧家庭是物联网的一个分支应用,是一个被广泛认同的巨大IT市场空间.目前市场上已经有很多针对智慧家庭的产品或解决方案,但与移动互联网不同,智慧家庭至今 ...
- ocp11g培训内部教材_052课堂笔记(042)_体系架构
OCP 052 课堂笔记 目录 第一部分: Oracle体系架构... 4 第一章:实例与数据库... 4 1.Oracle 网络架构及应用环境... 4 2.Oracle 体系结构... 4 3. ...
- Hadoop体系架构简介
今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce ...
- [转]OpenContrail 体系架构文档
OpenContrail 体系架构文档 英文原文:http://opencontrail.org/opencontrail-architecture-documentation/ 翻译者:@KkBLu ...
随机推荐
- loj2587 「APIO2018」铁人两项
圆方树orz,参见猫的课件(apio和wc的)以及这里那里 #include <iostream> #include <cstdio> using namespace std; ...
- 使用USB Key(加密狗)实现身份认证
首先你需要去买一个加密狗设备,加密狗是外形酷似U盘的一种硬件设备! 这里我使用的坚石诚信公司的ET99产品 公司项目需要实现一个功能,就是客户使用加密狗登录, 客户不想输入任何密码之类的东西,只需要插 ...
- 【廖雪峰老师python教程】day1
主要内容摘要 函数参数[个人感觉难度很大,却很重要,可以先大概记一记]不要用的太复杂.戳这儿温习 递归函数:使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出.重点:找到递归关系和终止条件 ...
- Loadrunner11.0安装与简单使用
公司开发了APP或者微信小程序啊什么的,都会先进行性能测试,而性能测试一般肯定会来测试接口的压测,并发.Loadrunner是一个很强大的测试工具,它是一种预测系统行为和性能的负载测试工具.通过以模拟 ...
- 官方文档 恢复备份指南八 RMAN Backup Concepts
本章内容 Consistent and Inconsistent RMAN Backups Online Backups and Backup Mode Backup Sets Image Copie ...
- 官方文档:11G新特性SQL PLAN BASLINE 执行计划基线
什么是SQL执行计划管理? SQL计划管理(SQL plan management)是一咱预防机制,记录和评估SQL语句的执行计划.SQL plan management的主要功能是sql plan ...
- KMP板子+Trie板子
KMP算法是一个字符串匹配算法,最直白的用法就是在一个长度为n的字符串T中查找另一个长度为m字符串P的匹配(总之就是用于文本中进行单个字符串的匹配). 对于这个问题,暴力算法是很好做的,直接对于T的每 ...
- SQLServer数据库慢查询追踪
不喜欢跟研发扯淡,说点击功能慢,是网络.服务器.运维的锅, 甩手给你打开慢查询,时间超过5s的全部抓取,已经很仁慈了,才抓取大于5s的SQL语句..... SQL SERVER 2014数据库慢查询追 ...
- lintcode-118-不同的子序列
118-不同的子序列 给出字符串S和字符串T,计算S的不同的子序列中T出现的个数. 子序列字符串是原始字符串通过删除一些(或零个)产生的一个新的字符串,并且对剩下的字符的相对位置没有影响.(比如,&q ...
- 推荐一个好的Redis GUI 客户端工具
推荐一个好的Redis GUI 客户端工具 Redis Desktop Manager