Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路。
(一)hadoop2.x版本下载及安装
Hadoop 版本选择目前主要基于三个厂商(国外)如下所示:
- 基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进。
- 基于HortonWorks厂商的开源免费的hdp版本。
- 基于Cloudera厂商的cdh版本,Cloudera有免费版和企业版, 企业版只有试用期。不过cdh大部分功能都是免费的。
(二)hadoop2.x分布式集群配置
1.集群资源规划设计

2.hadoop2.x分布式集群配置
1)Hadoop安装配置
先上传资源,并解压。
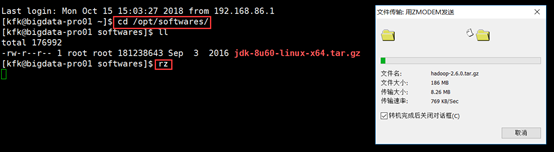
[kfk@bigdata-pro01 softwares]$ tar -zxf hadoop-2.6..tar.gz -C /opt/momdules/ [kfk@bigdata-pro01 softwares]$ cd ../momdules/ [kfk@bigdata-pro01 momdules]$ ll total drwxr-xr-x kfk kfk Nov hadoop-2.6. drwxr-xr-x kfk kfk Aug jdk1..0_60 [kfk@bigdata-pro01 momdules]$ cd hadoop-2.6./ [kfk@bigdata-pro01 hadoop-2.6.]$ ls bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
接下来对hadoop进行一个瘦身(删除不必要的文件,减小其大小)
[kfk@bigdata-pro01 hadoop-2.6.]$ cd share/ [kfk@bigdata-pro01 share]$ ls doc hadoop [kfk@bigdata-pro01 share]$ rm -rf ./doc/ [kfk@bigdata-pro01 share]$ ls hadoop [kfk@bigdata-pro01 share]$ cd .. [kfk@bigdata-pro01 hadoop-2.6.]$ ls bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share [kfk@bigdata-pro01 hadoop-2.6.]$ cd etc/hadoop/ [kfk@bigdata-pro01 hadoop]$ ls capacity-scheduler.xml hadoop-env.sh httpfs-env.sh kms-env.sh mapred-env.sh ssl-server.xml.example configuration.xsl hadoop-metrics2.properties httpfs-log4j.properties kms-log4j.properties mapred-queues.xml.template yarn-env.cmd container-executor.cfg hadoop-metrics.properties httpfs-signature.secret kms-site.xml mapred-site.xml.template yarn-env.sh core-site.xml hadoop-policy.xml httpfs-site.xml log4j.properties slaves yarn-site.xml hadoop-env.cmd hdfs-site.xml kms-acls.xml mapred-env.cmd ssl-client.xml.example [kfk@bigdata-pro01 hadoop]$ rm -rf ./*.cmd //.cmd为Windows下的命令,所以不需要,可以删掉。
2)hadoop2.x分布式集群配置-HDFS

安装hdfs需要修改4个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml和slaves
注意:为了方便和正确性的保证,以后Linux中的配置都使用外部工具Notepad++进行(连接之前请保证Windows下的Hosts文件已经添加了网络映射),连接方式如下:
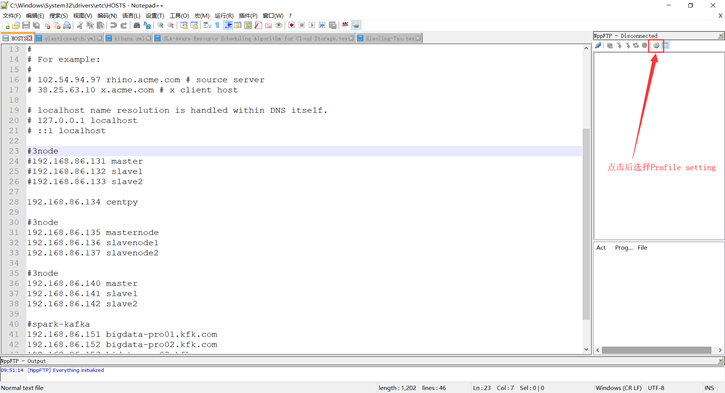

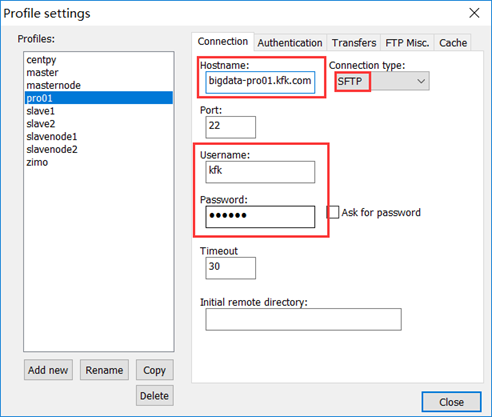
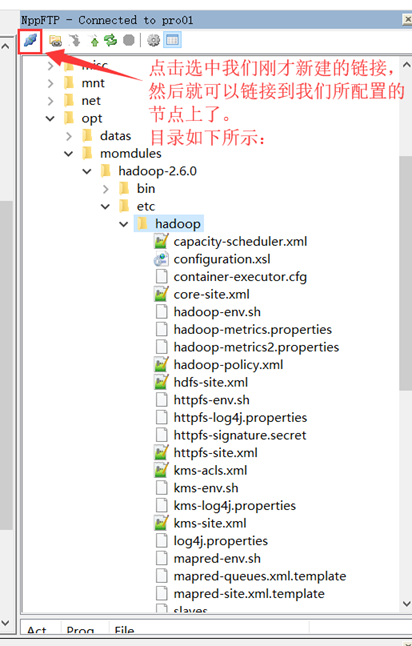
注:如果出现的目录和我的不同,请双击根目录(/)。
在配置的时候再教大家一个小技巧:能够复制粘贴的尽量复制粘贴,这样能尽量避免拼写错误。比如配置hadoop-env.sh文件时可以如下操作:
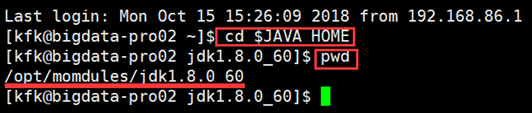
然后Ctrl+Ins组合键可以实现Linux下的复制操作,粘贴操作用Shift+Ins组合键。
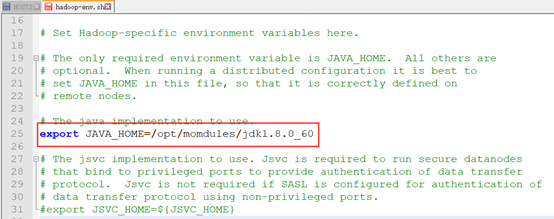
该文件只需配置JAVA_HOME目录即可。

<property>
<name>dfs.replication</name>
<value></value>
</property>
配置Namenode
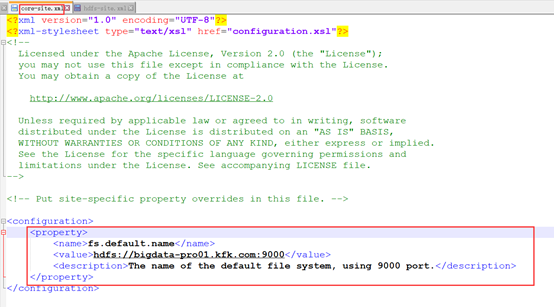
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata-pro01.kfk.com:9000</value>
<description>The name of the default file system, using port.</description>
</property>
配置Datanode

格式化Namenode
[kfk@bigdata-pro01 hadoop]$ cd .. [kfk@bigdata-pro01 etc]$ cd .. [kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs namenode –format
启动Namenode和Datanode
[kfk@bigdata-pro01 hadoop-2.6.]$ sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/momdules/hadoop-2.6./logs/hadoop-kfk-namenode-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/momdules/hadoop-2.6./logs/hadoop-kfk-datanode-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 hadoop-2.6.]$ jps NameNode Jps DataNode
进入网址:http://bigdata-pro01.kfk.com:50070/dfshealth.html#tab-overview
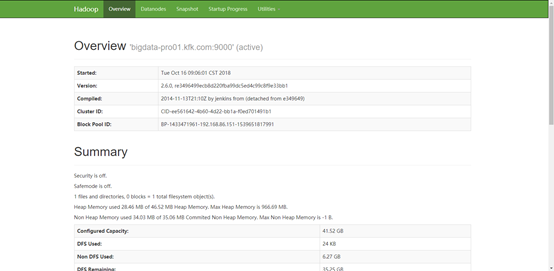
以上结果表明配置是成功的,然后发送到其他节点。
[kfk@bigdata-pro01 momdules]$ scp -r hadoop-2.6./ bigdata-pro02.kfk.com:/opt/momdules/ The authenticity of host 'bigdata-pro02.kfk.com (192.168.86.152)' can't be established. RSA key fingerprint is b5::fe:c4:::0c:aa:5c:f5:6f:::c5:f8:8e. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'bigdata-pro02.kfk.com,192.168.86.152' (RSA) to the list of known hosts. kfk@bigdata-pro02.kfk.com's password: [kfk@bigdata-pro01 momdules]$ scp -r hadoop-2.6./ bigdata-pro03.kfk.com:/opt/momdules/
然后启动两个子节点的DataNode并刷新网页看看有什么变化。
[kfk@bigdata-pro02 hadoop-2.6.]$ sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/momdules/hadoop-2.6./logs/hadoop-kfk-datanode-bigdata-pro02.kfk.com.out [kfk@bigdata-pro02 hadoop-2.6.]$ jps DataNode Jps [kfk@bigdata-pro03 ~]$ cd /opt/momdules/hadoop-2.6./ [kfk@bigdata-pro03 hadoop-2.6.]$ sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/momdules/hadoop-2.6./logs/hadoop-kfk-datanode-bigdata-pro03.kfk.com.out [kfk@bigdata-pro03 hadoop-2.6.]$ jps DataNode Jps
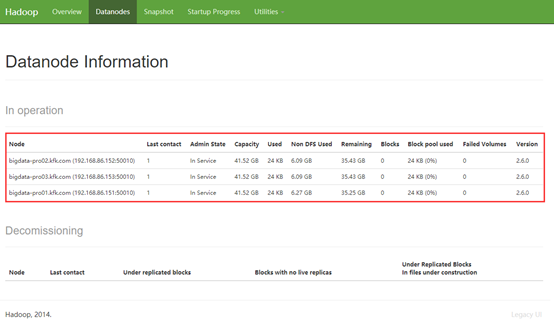
接下来,我们在dfs上创建一个目录并上传一个文件:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -mkdir -p /user/kfk/data/ // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -put /opt/momdules/hadoop-2.6./etc/hadoop/core-site.xml /user/kfk/data

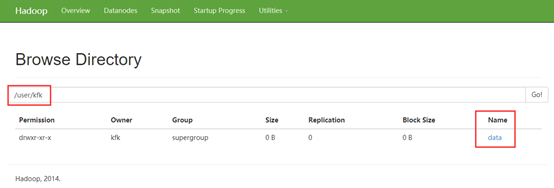
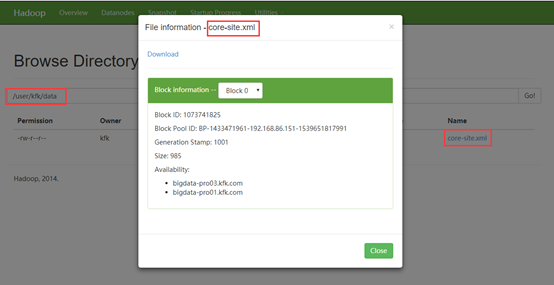
创建和上传都成功!
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -text /user/kfk/data/core-site.xml
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata-pro01.kfk.com:9000</value>
<description>The name of the default file system, using port.</description>
</property>
</configuration>
文件内容也是完全一致的!
3)hadoop2.x分布式集群配置-YARN
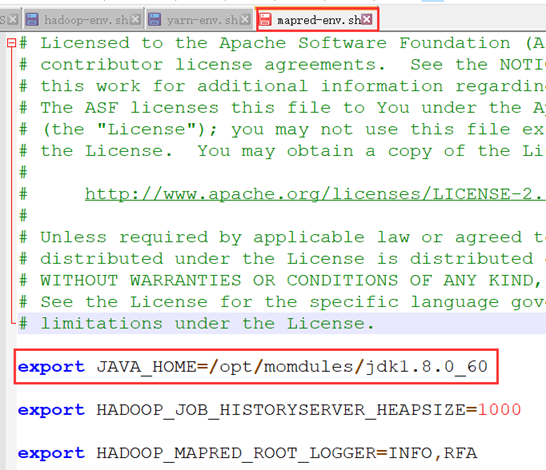
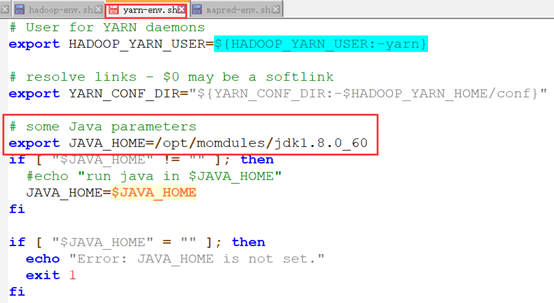
安装yarn需要修改4个配置文件:yarn-env.sh、mapred-env.sh、yarn-site.xml和mapred-site.xml

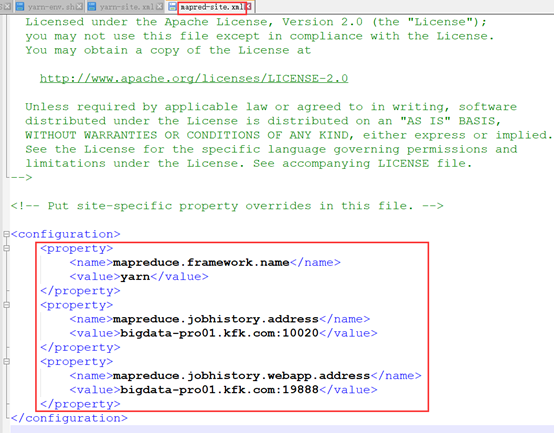
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-pro01.kfk.com:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-pro01.kfk.com:</value>
</property>
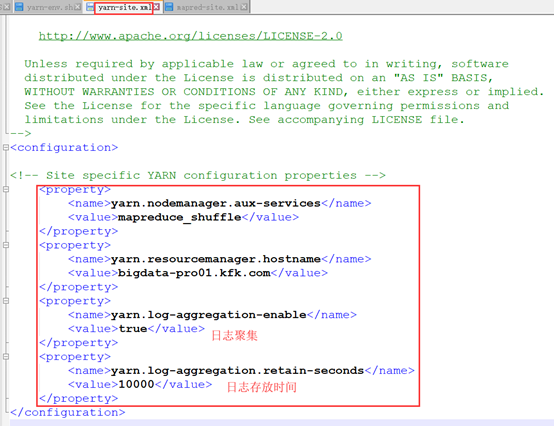
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-pro01.kfk.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value></value>
</property>
(三)分发到其他各个机器节点
hadoop相关配置在第一个节点配置好之后,可以通过脚本命令分发给另外两个节点即可,具体操作如下所示。
#将安装包分发给第二个节点
[kfk@bigdata-pro01 hadoop]$ scp -r ./* kfk@bigdata-pro02.kfk.com:/opt/momdules/hadoop-2.6.0/etc/hadoop/
#将安装包分发给第三个节点
[kfk@bigdata-pro01 hadoop]$ scp -r ./* kfk@bigdata-pro03.kfk.com:/opt/momdules/hadoop-2.6.0/etc/hadoop/
(四)HDFS启动集群运行测试
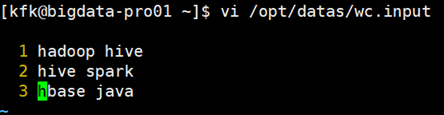
[kfk@bigdata-pro01 hadoop]$ cd .. [kfk@bigdata-pro01 etc]$ cd .. [kfk@bigdata-pro01 hadoop-2.6.]$ cd .. [kfk@bigdata-pro01 momdules]$ cd .. [kfk@bigdata-pro01 opt]$ cd datas/ [kfk@bigdata-pro01 datas]$ touch wc.input [kfk@bigdata-pro01 datas]$ vi wc.input hadoop hive hive spark hbase java [kfk@bigdata-pro01 datas]$ cd ../momdules/hadoop-2.6./ [kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -put /opt/datas/wc.input /user/kfk/data // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hdfs相关配置好之后,可以启动resourcemanager和nodemanager。
[kfk@bigdata-pro01 hadoop-2.6.]$ sbin/yarn-daemon.sh resourcemanager Usage: yarn-daemon.sh [--config <conf-dir>] [--hosts hostlistfile] (start|stop) <yarn-command> [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/momdules/hadoop-2.6./logs/yarn-kfk-resourcemanager-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/momdules/hadoop-2.6./logs/yarn-kfk-nodemanager-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/momdules/hadoop-2.6./logs/mapred-kfk-historyserver-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 hadoop-2.6.]$ jps NameNode NodeManager Jps ResourceManager DataNode JobHistoryServer [kfk@bigdata-pro02 hadoop-2.6.]$ sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/momdules/hadoop-2.6./logs/yarn-kfk-nodemanager-bigdata-pro02.kfk.com.out [kfk@bigdata-pro02 hadoop-2.6.]$ jps NodeManager DataNode Jps [kfk@bigdata-pro03 hadoop-2.6.]$ sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/momdules/hadoop-2.6./logs/yarn-kfk-nodemanager-bigdata-pro03.kfk.com.out [kfk@bigdata-pro03 hadoop-2.6.]$ jps Jps DataNode NodeManager
进入网址:http://bigdata-pro01.kfk.com:8088/cluster/nodes

接下来配置一下DataNode的日志目录。

<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
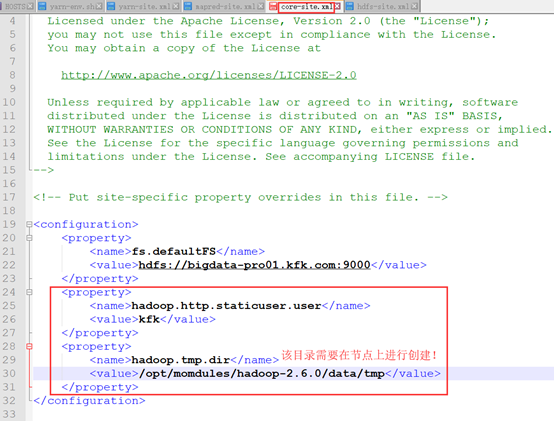
<property>
<name>hadoop.http.staticuser.user</name>
<value>kfk</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/momdules/hadoop-2.6./data/tmp</value>
</property>
创建目录:
[kfk@bigdata-pro01 hadoop-2.6.]$ mkdir -p data/tmp [kfk@bigdata-pro01 hadoop-2.6.]$ cd data/tmp/ [kfk@bigdata-pro01 tmp]$ pwd /opt/momdules/hadoop-2.6./data/tmp
然后分发配置到其他节点:
由于修改东西并且新建了路径,为了安全起见,先删掉两个节点的hadoop文件夹,全部重发一次吧。
[kfk@bigdata-pro02 momdules]$ rm -rf hadoop-2.6./ //注意删除的是02和03节点,别删错了。
然后分发:
scp -r ./hadoop-2.6./ kfk@bigdata-pro02.kfk.com:/opt/momdules/ scp -r ./hadoop-2.6./ kfk@bigdata-pro03.kfk.com:/opt/momdules/
格式化NameNode
格式化之前要先停掉所有服务:
[kfk@bigdata-pro01 hadoop-2.6.]$ sbin/yarn-daemon.sh stop resourcemanager stopping resourcemanager [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/yarn-daemon.sh stop nodemanager stopping nodemanager [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/mr-jobhistory-daemon.sh stop historyserver stopping historyserver [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/hadoop-daemon.sh stop namenode stopping namenode [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/hadoop-daemon.sh stop datanode stopping datanode [kfk@bigdata-pro01 hadoop-2.6.]$ jps Jps
格式化:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs namenode -format
启动各个节点机器服务
1)启动NameNode命令:
sbin/hadoop-daemon.sh start namenode(01节点)
2) 启动DataNode命令:
sbin/hadoop-daemon.sh start datanode(//03节点)
格式化Namenode之后之前建立的路径也就没有了,所有我们要重新创建。
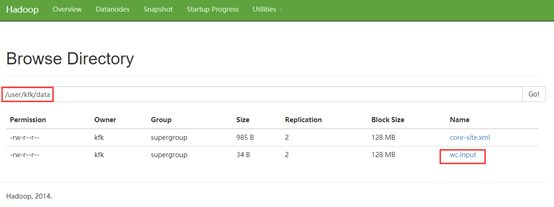
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -mkdir -p /user/kfk/data
3)启动ResourceManager命令:
sbin/yarn-daemon.sh start resourcemanager(01节点)
4)启动NodeManager命令:
sbin/yarn-daemon.sh start nodemanager(//03节点)
5)启动log日志命令:
sbin/mr-jobhistory-daemon.sh start historyserver(01节点)
(五)YARN集群运行MapReduce程序测试
前面hdfs和yarn都启动起来之后,可以通过运行WordCount程序检测一下集群是否能run起来。
重新上传测试文件:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -put /opt/datas/wc.input /user/kfk/data/
然后创建一个输出目录:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -mkdir -p /user/kfk/data/output/
使用集群自带的WordCount程序执行命令:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount /user/kfk/data/wc.input /user/kfk/data/output
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO client.RMProxy: Connecting to ResourceManager at bigdata-pro01.kfk.com/192.168.86.151:
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://bigdata-pro01.kfk.com:9000/user/kfk/data/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:)
运行报错。原因是输出目录已经存在,而MapReduce执行时会检测输出目录是否存在,不存在则自动创建并正常执行;否则报错。所以我们重新运行,在输出目录后再追加一个目录即可。
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount /user/kfk/data/wc.input /user/kfk/data/output/
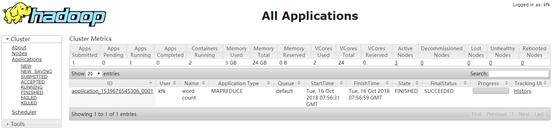
点击History可以查看日志
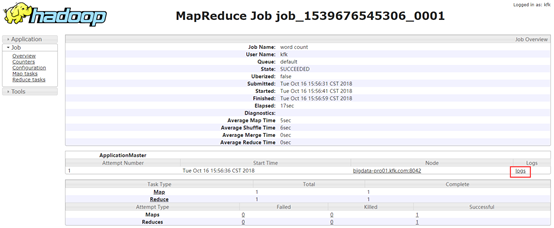

这样就能很方便地查看日志,而不用在命令行进hadoop的logs/目录下去查看了。我们查看一下运行结果:
[kfk@bigdata-pro01 hadoop-2.6.]$ bin/hdfs dfs -text /user/kfk/data/output//par* // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hadoop hbase hive java spark
很明显结果是正确的(上图中黄色为行号,而非文件内容)!
(六)ssh无秘钥登录
在集群搭建的过程中,需要不同节点分发文件,那么节点间分发文件每次都需要输入密码,比较麻烦。另外在hadoop 集群启动过程中,也需要使用批量脚本统一启动各个节点服务,此时也需要节点之间实现无秘钥登录。具体操作步骤如下所示:
1.主节点上创建 .ssh 目录,然后生成公钥文件id_rsa.pub和私钥文件[kfk@bigdata-pro01 datas]$ cd
[kfk@bigdata-pro01 ~]$ cd .ssh [kfk@bigdata-pro01 .ssh]$ ls known_hosts [kfk@bigdata-pro01 .ssh]$ cat known_hosts bigdata-pro02.kfk.com,192.168.86.152 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsHpzF1vSSqZPIbTKrhsxKGqofgngHbm5MdXItaSEJ8JemIuWrMo5++0g3QG/m/DRW8KqjXhnBO819tNIqmVNeT+0cH7it9Nosz1NWfwvXyNy+lbxdjfqSs+DvMh0w5/ZoiXVdqWmPAh2u+CP4BKbHS4VKRNoZk42B++gzXxN6Gt1kxNemLsLw6251IzmsX+dVr8iH493mXRwE9dv069uKoA0HVwn6FL51D8c1H1v1smD/EzUsL72TUknz8DV43iawIBDMSw4GQJFoZtm2ogpCuIhBfLwTfl+5yyzjY8QdwH5sDiKFlPX476M+A1s+mneyQtaaRwORIiOvs7TgtSTw== bigdata-pro03.kfk.com,192.168.86.153 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsHpzF1vSSqZPIbTKrhsxKGqofgngHbm5MdXItaSEJ8JemIuWrMo5++0g3QG/m/DRW8KqjXhnBO819tNIqmVNeT+0cH7it9Nosz1NWfwvXyNy+lbxdjfqSs+DvMh0w5/ZoiXVdqWmPAh2u+CP4BKbHS4VKRNoZk42B++gzXxN6Gt1kxNemLsLw6251IzmsX+dVr8iH493mXRwE9dv069uKoA0HVwn6FL51D8c1H1v1smD/EzUsL72TUknz8DV43iawIBDMSw4GQJFoZtm2ogpCuIhBfLwTfl+5yyzjY8QdwH5sDiKFlPX476M+A1s+mneyQtaaRwORIiOvs7TgtSTw== [kfk@bigdata-pro01 .ssh]$ rm -f known_hosts //保证.ssh目录是干净的 [kfk@bigdata-pro01 .ssh]$ ls [kfk@bigdata-pro01 .ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/kfk/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/kfk/.ssh/id_rsa. Your public key has been saved in /home/kfk/.ssh/id_rsa.pub. The key fingerprint is: 6f:a2::da:9d:::e5:::a1::0c:7a:8d:b8 kfk@bigdata-pro01.kfk.com The key's randomart image is: +--[ RSA ]----+ | | | . . | | o = . . | | o o * + | | So B . | | E.. o o | | . . oo . | | ....o.o. | | ... +o . | +-----------------+
2.拷贝公钥到各个机器
ssh-copy-id bigdata-pro1.kfk.com ssh-copy-id bigdata-pro2.kfk.com ssh-copy-id bigdata-pro3.kfk.com
3.测试ssh连接
ssh bigdata-pro1.kfk.com ssh bigdata-pro2.kfk.com ssh bigdata-pro3.kfk.com [kfk@bigdata-pro01 .ssh]$ ssh bigdata-pro02.kfk.com Last login: Tue Oct :: from 192.168.86.1
4.测试hdfs
ssh无秘钥登录做好之后,可以在主节点通过一键启动/停止命令,启动/停止hdfs各个节点的服务,具体操作如下所示:
[kfk@bigdata-pro01 hadoop-2.6.]$ sbin/stop-dfs.sh // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Stopping namenodes on [bigdata-pro01.kfk.com] bigdata-pro01.kfk.com: stopping namenode bigdata-pro03.kfk.com: stopping datanode bigdata-pro01.kfk.com: stopping datanode bigdata-pro02.kfk.com: stopping datanode Stopping secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. RSA key fingerprint is b5::fe:c4:::0c:aa:5c:f5:6f:::c5:f8:8e. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts. 0.0.0.0: no secondarynamenode to stop // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [kfk@bigdata-pro01 hadoop-2.6.]$ sbin/stop-yarn.sh stopping yarn daemons stopping resourcemanager bigdata-pro03.kfk.com: stopping nodemanager bigdata-pro02.kfk.com: stopping nodemanager bigdata-pro01.kfk.com: stopping nodemanager no proxyserver to stop
如果yarn和hdfs主节点共用,配置一个节点即可。否则,yarn也需要单独配置ssh无秘钥登录。
(七)配置集群内机器时间同步(使用Linux ntp进行)
参考博文:https://www.cnblogs.com/zimo-jing/p/8892697.html
注:在三个节点上都要进行操作,还有最后一个命令使用sudo。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!
Hadoop2.X分布式集群部署的更多相关文章
- 新闻实时分析系统-Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- 新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
随机推荐
- 解决批处理命令执行完毕后自动关闭cmd窗口方法
问题描述: 日常开发工作中,为了节省多余操作导致浪费时间,我们经常会自己建一些批处理脚本文件(xx.bat),文件中包含我们需要执行的命令,有时候我们希望执行完毕后看一下执行的结果,但是窗口执行完毕后 ...
- java Servlet学习笔记(一)
访问机制 (https://pan.baidu.com/share/link?shareid=3055126243&uk=3355579678&fid=1073713310362078 ...
- 记一次成功部署kolla-ansible ocata版本过程
1.安装的docker版本 [root@controller ~]# docker --versionDocker version 17.09.1-ce, build 19e2cf6 2.安装的ans ...
- Git解决pull无法操作成功
https://blog.csdn.net/chenjunfengf/article/details/78301957 场景 在git pull的时候,如果本地代码有改动,而服务器上代码也已经被其他人 ...
- hyperledger fabric 中java chaincode 支持离线打包
联盟链由于其本身的特性,目前应用在一些大型国有企业银行比较多.出于安全考虑,这些企业一般会隔离外网环境.所以在实际生产需求中可能存在需要在一个离线的环境中打包安装chaincode的情况. 本文基于这 ...
- ORACLE 中dbms_stats的使用
dbms_stats能良好地估计统计数据(尤其是针对较大的分区表),并能获得更好的统计结果,最终制定出速度更快的SQL执行计划. exec dbms_stats.gather_schema_stats ...
- node mysql问题:Client does not support authentication protocol requested by server; consider upgrading MySQL client!
node后台 mysql处理模块(版本:2.16.0) 执行connect方法时报错: Client does not support authentication protocol requeste ...
- CF580D Kefa and Dishes 状压dp
When Kefa came to the restaurant and sat at a table, the waiter immediately brought him the menu. Th ...
- GUI JFrame窗体介绍:
GUI JFrame窗体介绍: https://www.cnblogs.com/-ksz/p/3422074.html
- DropDownList年份的添加
http://blog.sina.com.cn/s/blog_4b9e030e01007sc3.html