《R语言实战》读书笔记--第五章 高级数据管理
本章内容:
数学和统计函数
字符处理函数
循环和条件执行
自编函数
数据整合与重塑
5.1一个数据处理难题
5.2数值和字符处理函数
分为数值函数和字符串函数,下面是数学函数截图:
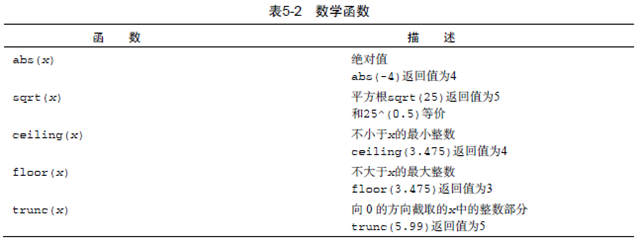

ceiling、floor、trunc、signif函数第一次听说,是一些数位函数的处理函数。注意log是以e为底的。当上面的函数用在向量、矩阵、数据框时,单独用于每一个独立的值。
5.2.2统计函数
举个例子:mean函数
mean(x, trim = , na.rm = FALSE, ...)
#trim参数表示将多少比例的最大和最小数去掉
下面是一些统计函数截图:

下面补充一下统计知识:
sd函数,值得注意sd函数除的是维数 n-1.
mad函数:中位数绝对偏差
mad(x, center = median(x), constant = 1.4826, na.rm = FALSE,
low = FALSE, high = FALSE)
#The actual value calculated is constant * cMedian(abs(x - center)) with the default value of center being median(x), and cMedian being the usual, the ‘low’ or ‘high’ median, see the arguments description for low and high above.
The default constant = 1.4826 (approximately 1/ Φ^(-1)(3/4) = 1/qnorm(3/4)) ensures consistency, i.e.,
E[mad(X_1,…,X_n)] = σ
for X_i distributed as N(μ, σ^2) and large n.
quantile函数,求分位数的函数。
range函数:值域函数,返回一个对象的最大最小值。
diff函数:
diff(x, lag = , differences = , ...)
#这个函数返回后面的值减去前面的值的结果,x是一个数值向量或者矩阵,lag是间隔几个
#求差,differences表明做几层的差,比如,如果为2,则做一次差以后的返回值再进行一次
#作差
scale函数:
scale(x, center = TRUE, scale = TRUE)
#这个函数是将一个数值矩阵的每一列进行中心化(center)或者标准化(scale)
#center和scale参数也可以是一个与列数相同向量,分别为自己规定的center和scale
中心化是将数据减去均值,标准化是将数据中心化以后再除标准差。书上的标准化说的是错的,scale函数不是默认0均值,1标准差,而是具体数值的mean和sd。
5.2.3概率函数
首先是概率函数中的几个含义:
d:density(密度)
p:distribution function(分布函数)
q:quantile function(分位数函数)
r:生成随机数(随机偏差)
常见的概率分布函数:
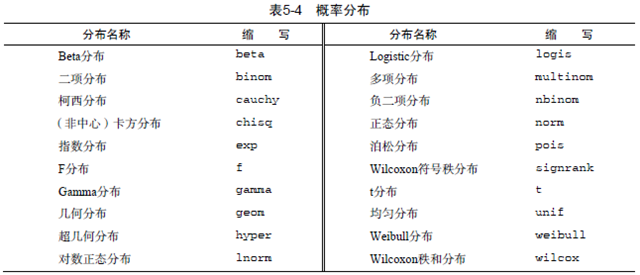
再来一次,d表示密度,p是分布函数,q是分位数函数r是随机生成.
pretty函数:
pretty(x, n = , min.n = n %/% , shrink.sml = 0.75,
high.u.bias = 1.5, u5.bias = . + 1.5*high.u.bias,
eps.correct = , ...)
#稍后解释
1.设置随机数种子
每次生成随机数的时候,函数会使用不同的种子,因此产生不同的结果.使用种子设置是为了产生可重复的随机数.
函数set.seed:
2.生成多元正态数据
利用MASS包中的mvrnorm函数可以生成多元正态数据,
mvrnorm(n = , mu, Sigma, tol = 1e-, empirical = FALSE, EISPACK = FALSE)
#n是维数,mu是均值向量,Sigma是协方差矩阵,empirical 若是TRUE,
#则是指定的mu和Sigma
Sigma <- matrix(c(10,3,3,2),2,2)
var(mvrnorm(n = 1000, rep(0, 2), Sigma))
var(mvrnorm(n = 1000, rep(0, 2), Sigma, empirical = TRUE))
结果:
[,1] [,2]
[1,] 10.783732 3.280442
[2,] 3.280442 2.063448
和
[,1] [,2]
[1,] 10 3
[2,] 3 2
5.2.4字符串处理函数
见截图:


nchar函数返回向量中每一个字符串的长度,参数中有关于处理NA的参数,keepNA = TRUE,则返回的结果中保留NA,否则返回2(NA的长度).
substr:注意在更改的时候,每个个体值字符的长度是不变的,不管你的赋值是多少个;赋的少了,只改赋的那部分,长了,只是修改跟自己原来长度一样的部分。
grep函数:
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
fixed = FALSE, useBytes = FALSE, invert = FALSE) grepl(pattern, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE) sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE) gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE) regexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE) gregexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE) regexec(pattern, text, ignore.case = FALSE,
fixed = FALSE, useBytes = FALSE)
#这是一组函数,看一下参数说明:
#、pattern:字符或者正则表达式
#、x,text:被匹配的字符向量
#、igno.case:默认的FALSE表示大小写敏感,TRUE为不敏感
#、perl:若为TRUE,表示应用Perl的正则表达式规则
#、value:默认为F表示返回下标或者逻辑值,若为T,返回字符串
#、fixed:若为TRUE,则不用正则表达式,直接字符串匹配
#、useBytes:默认F按照字符查找,若为T,按照字节查找,注意中文查找这个参数有用
#、invert:F则为正常查找,若为T则查找pattern的补集
#、replacement:sub和gsub函数中,表示替换的字符 grep返回的是下标,grepl返回的是逻辑值。
sub和gsub必须有replacem参数,其次:
sub("A",x = c('a','AA'),replacement = 'asd')和gsub("A",x = c('a','AA'),replacement = 'asd')的区别在于,sub只是替换第一个匹配的字符,gsub是替换所有的匹配字符。
结果为:
[1] "a" "asdA"和
[1] "a" "asdasd"
下面是剩余三个函数的例子:
转自:http://blog.sina.com.cn/s/blog_69ffa1f90101sie9.html
regexpr、gregexpr、regexec这三个函数返回的结果包含了匹配的具体位置和字符串长度信息,可以用于字符串的提取操作。
text <- c("Hellow, Adam!", "Hi, Adam!", "How are you, Adam.")
regexpr("Adam", text)
## [1] 9 5 14 ## attr(,"match.length") ## [1] 4 4 4 ## attr(,"useBytes") ## [1] TRUE
gregexpr("Adam", text)
## [[1]]
## [1] 9
## attr(,"match.length")
## [1] 4 ## attr(,"useBytes")
## [1] TRUE ## ## [[2]] ## [1] 5
## attr(,"match.length")
## [1] 4
## attr(,"useBytes")
## [1] TRUE
## ## [[3]]
## [1] 14
## attr(,"match.length")
## [1] 4
## attr(,"useBytes")
## [1] TRUE
regexec("Adam", text)
## [[1]]
## [1] 9
## attr(,"match.length")
## [1] 4
## ## [[2]]
## [1] 5
## attr(,"match.length")
## [1] 4
## ## [[3]]
## [1] 14
## attr(,"match.length")
## [1] 4
strsplit函数:
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
#在split处分割x,返回一个列表,split不会包含在任何一个列表元素中
#若为空,则按照单个字符进行分割
unlist函数可以去列表化,形成向量。
sapply函数:
sapply(strsplit(c('abcdef'),split='b'),"[")
上面的语句返回的是一个2行1列的矩阵!sapply函数是将一个函数应用到一个向量或者expression上相关的有apply等。
sapply(x, f, simplify = FALSE, USE.NAMES = FALSE)
#x是一个向量或者一个expression,f是函数
#simplify是说是否将返回的列表转换为比较简单的
#向量、矩阵、高维数组,USE.NAMES是说如果
#x是字符,那么返回的结果的名字就用x中的值
‘[’是一个运算符,《R语言编程艺术》中讲到过回去翻。
paste函数:
paste (..., sep = " ", collapse = NULL)
#sep 用来设置用什么来连接;
#若合并的字符串向量大于1,则collapse用来设置
#用什么将向量中所有字符连接起来,且只接收一个字符 paste('x',:,sep = '')和paste('x',:,sep = '',collapse = c('ABC')) 结果为:[] "x1" "x2"和[] "x1ABCx2"
下面是几个字符串转变函数:
chartr(old, new, x)
tolower(x)
toupper(x)
casefold(x, upper = FALSE)
#chartr 是将x中old转换为new
#tolower 转换为小写
#toupper 转换为大写
#casefold Splus兼容包
5.2.5其他实用函数
书上的函数有length、seq、rep、cut、pretty、cat函数,cut在第四章写过,下面写pretty和cat。
pretty:
pretty(x, n = , min.n = n %/% , shrink.sml = 0.75,
high.u.bias = 1.5, u5.bias = . + 1.5*high.u.bias,
eps.correct = , ...)
#pretty用来创建美观的分割点
#这个函数不是规定n等于几,就会分几个间隔,有他
#自己的设定方式
cat:
cat(... , file = "", sep = " ", fill = FALSE, labels = NULL,
append = FALSE)
#是一个输出函数,远比print表现少很多
#cat将很多参数连接起来输出,每两个连接起来的参数之间自动加上空格
#file是说可以存储到一个文件中,后面的append是设置是覆盖还是添加
#sep是一个字符向量,跟在连接元素的后面
#fill控制是否打印空行,如果为FALSE,则碰到'\n'才会打印,若为TRUE,则
#根据默认宽度换行;labels 当fill为TRUE时才有意义,是打印出的行的名称
5.2.6将函数应用于矩阵和数据框
就在说apply函数,写一下:
apply(X, MARGIN, FUN, ...)
#X是一个数组、矩阵或者数据框
#MARGIN 1或者2 表示行或者列
#FUN是作用于每一行或列的函数
#如果FUN是R中的函数,函数名称后面接着加参数就行
#如果是自己编的就自己编好了,这个函数用的很多
lapply 和 sapply 是应用在list上的函数。
一组函数:
lapply(X, FUN, ...) #返回一个列表 sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE) #与lapply基本相同 vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE) #与sapply相同,但是可以预设返回值类型 replicate(n, expr, simplify = "array") #sapply的封装,多次应用,随机数 simplify2array(x, higher = TRUE) #X是一个向量、单值或者列表或者expression对象
#FUN是作用在X每个元素上的函数
#simplity 逻辑值 表示是否把结果转换为向量矩阵等
#USE.NAMES 是否将结果的名字设置为原X的值
#FUN.VALUE 设置函数FUN返回值类型
#n 重复的次数
#expr 重复执行的命令
#x 一个列表,通常是 lapply 的返回值
#higher 是否返回为高维数组,否的话是矩阵
下面的总结来自: http://blog.sina.com.cn/s/blog_403aa80a010174dj.html
apply
Apply Functions Over Array Margins
对阵列行或者列使用函数
apply(X, MARGIN, FUN, ...)
lapply
Apply a Function over a List or Vector
对列表或者向量使用函数
lapply(X, FUN, ...)
sapply
Apply a Function over a List or Vector
对列表或者向量使用函数
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)
vapply
Apply a Function over a List or Vector
对列表或者向量使用函数
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
tapply
Apply a Function Over a Ragged Array
对不规则阵列使用函数
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
eapply
Apply a Function Over Values in an Environment
对环境中的值使用函数
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
mapply
Apply a Function to Multiple List or Vector Arguments
对多个列表或者向量参数使用函数
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
rapply
Recursively Apply a Function to a List
运用函数递归产生列表
rapply(object, f, classes = "ANY", deflt = NULL,how = c("unlist", "replace", "list"), ...) apply {base}
通过对数组或者矩阵的一个维度使用函数生成值得列表或者数组、向量。
apply(X, MARGIN, FUN, ...)
X 阵列,包括矩阵
MARGIN 1表示矩阵行,2表示矩阵列,也可以是c(,)
例:
>xxx<-matrix(:,ncol=)
>apply(xxx,,mean)
[] 8.5 9.5 10.5 11.5 12.5
>apply(xxx,,mean)
[]
>xxx
[,] [,] [,] [,]
[,]
[,]
[,]
[,]
[,] lapply {base}
通过对x的每一个元素运用函数,生成一个与元素个数相同的值列表
lapply(X, FUN, ...)
X表示一个向量或者表达式对象,其余对象将被通过as.list强制转换为list
例:
> x <- list(a = :, beta = exp(-:), logic = c(TRUE,FALSE,FALSE,TRUE))
> x
$a
[]
$beta
[] 0.04978707 0.13533528 0.36787944 1.00000000 2.71828183 7.38905610
[] 20.08553692
$logic
[] TRUE FALSE FALSE TRUE
> lapply(x,mean)
$a
[] 5.5
$beta
[] 4.535125
$logic
[] 0.5 sapply {base}
这是一个用户友好版本,是lapply函数的包装版。该函数返回值为向量、矩阵,如果simplify=”array”,且合适的情况下,将会通过simplify2array()函数转换为阵列。sapply(x, f, simplify=FALSE, USE.NAMES=FALSE)返回的值与lapply(x,f)是一致的。
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)
X表示一个向量或者表达式对象,其余对象将被通过as.list强制转换为list
simplify 逻辑值或者字符串,如果可以,结果应该被简化为向量、矩阵或者高维数组。必须是命名的,不能是简写。默认值是TRUE,若合适将会返回一个向量或者矩阵。如果simplify=”array”,结果将返回一个阵列。
USE.NAMES 逻辑值,如果为TRUE,且x没有被命名,则对x进行命名。
例:
> sapply(k, paste,USE.NAMES=FALSE,:,sep="...")
[,] [,] [,]
[,] "a...1" "b...1" "c...1"
[,] "a...2" "b...2" "c...2"
[,] "a...3" "b...3" "c...3"
[,] "a...4" "b...4" "c...4"
[,] "a...5" "b...5" "c...5"
> sapply(k, paste,USE.NAMES=TRUE,:,sep="...")
a b c
[,] "a...1" "b...1" "c...1"
[,] "a...2" "b...2" "c...2"
[,] "a...3" "b...3" "c...3"
[,] "a...4" "b...4" "c...4"
[,] "a...5" "b...5" "c...5"
> sapply(k, paste,USE.NAMES=TRUE,:,sep="...",simplyfy=TRUE)
a b c
[,] "a...1...TRUE" "b...1...TRUE" "c...1...TRUE"
[,] "a...2...TRUE" "b...2...TRUE" "c...2...TRUE"
[,] "a...3...TRUE" "b...3...TRUE" "c...3...TRUE"
[,] "a...4...TRUE" "b...4...TRUE" "c...4...TRUE"
[,] "a...5...TRUE" "b...5...TRUE" "c...5...TRUE"
> sapply(k, paste,simplify=TRUE,USE.NAMES=TRUE,:,sep="...")
a b c
[,] "a...1" "b...1" "c...1"
[,] "a...2" "b...2" "c...2"
[,] "a...3" "b...3" "c...3"
[,] "a...4" "b...4" "c...4"
[,] "a...5" "b...5" "c...5"
> sapply(k, paste,simplify=FALSE,USE.NAMES=TRUE,:,sep="...")
$a
[] "a...1" "a...2" "a...3" "a...4" "a...5"
$b
[] "b...1" "b...2" "b...3" "b...4" "b...5"
$c
[] "c...1" "c...2" "c...3" "c...4" "c...5" vapply {base}
vapply类似于sapply函数,但是它的返回值有预定义类型,所以它使用起来会更加安全,有的时候会更快
在vapply函数中总是会进行简化,vapply会检测FUN的所有值是否与FUN.VALUE兼容,以使他们具有相同的长度和类型。类型顺序:逻辑<</span>整型<</span>实数<</span>复数
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
X表示一个向量或者表达式对象,其余对象将被通过as.list强制转换为list
simplify 逻辑值或者字符串,如果可以,结果应该被简化为向量、矩阵或者高维数组。必须是命名的,不能是简写。默认值是TRUE,若合适将会返回一个向量或者矩阵。如果simplify=”array”,结果将返回一个阵列。
USE.NAMES 逻辑值,如果为TRUE,且x没有被命名,则对x进行命名。
FUN.VALUE 一个通用型向量,FUN函数返回值得模板
例:
> x<-data.frame(a=rnorm(,,),b=rnorm(,,),c=rnorm(,,))
> vapply(x,mean,c(c=))
a b c
1.8329043 6.0442858 -0.1437202
> k<-function(x)
+ {
+ list(mean(x),sd(x))
+ }
> vapply(x,k,c(c=))
错误于vapply(x, k, c(c = )) : 值的长度必需为1,
但FUN(X[[]])结果的长度却是2
> vapply(x,k,c(c=,b=))
错误于vapply(x, k, c(c = , b = )) : 值的种类必需是'double',
但FUN(X[[]])结果的种类却是'list'
> vapply(x,k,c(list(c=,b=)))
a b c
c 1.832904 6.044286 -0.1437202
b 1.257834 1.940433 3.649194 tapply {base}
对不规则阵列使用向量,即对一组非空值按照一组确定因子进行相应计算
tapply(X, INDEX, FUN, ..., simplify = TRUE)
x 一个原子向量,典型的是一个向量
INDEX 因子列表,和x长度一样,元素将被通过as.factor强制转换为因子
simplify 若为FALSE,tapply将以列表形式返回阵列。若为TRUE,FUN则直接返回数值
例:
> height <- c(, , , , )
> sex<-c("F","F","M","F","M")
> tapply(height, sex, mean)
F M eapply {base}
eapply函数通过对environment中命名值进行FUN计算后返回一个列表值,用户可以请求所有使用过的命名对象。
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
env 将被使用的环境
all.names 逻辑值,指示是否对所有值使用该函数
USE.NAMES 逻辑值,指示返回的列表结果是否包含命名
例:
> require(stats)
>
> env <- new.env(hash = FALSE) # so the order is fixed
> env$a <- :
> env$beta <- exp(-:)
> env$logic <- c(TRUE, FALSE, FALSE, TRUE)
> # what have we there?
> utils::ls.str(env)
a : int [:]
beta : num [:] 0.0498 0.1353 0.3679 2.7183 ...
logic : logi [:] TRUE FALSE FALSE TRUE
>
> # compute the mean for each list element
> eapply(env, mean)
$logic
[] 0.5 $beta
[] 4.535125 $a
[] 5.5 > unlist(eapply(env, mean, USE.NAMES = FALSE))
[] 0.500000 4.535125 5.500000
>
> # median and quartiles for each element (making use of "..." passing):
> eapply(env, quantile, probs = :/)
$logic
% % %
0.0 0.5 1.0 $beta
% % %
0.2516074 1.0000000 5.0536690 $a
% % %
3.25 5.50 7.75 > eapply(env, quantile)
$logic
% % % % %
0.0 0.0 0.5 1.0 1.0 $beta
% % % % %
0.04978707 0.25160736 1.00000000 5.05366896 20.08553692 $a
% % % % %
1.00 3.25 5.50 7.75 10.00 mapply {base}
mapply是sapply的多变量版本。将对...中的每个参数运行FUN函数,如有必要,参数将被循环。
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
MoreArgs FUN函数的其他参数列表
SIMPLIFY 逻辑或者字符串,可以减少结果成为一个向量、矩阵或者更高维阵列,详见sapply的simplify参数
USE.NAMES 逻辑值,如果第一个参数...已被命名,将使用这个字符向量作为名字
例:
> mapply(rep, :, :)
[[]]
[] [[]]
[] [[]]
[] [[]]
[] rapply {base}
rapply是lapply的递归版本
rapply(X, FUN, classes = "ANY", deflt = NULL, how = c("unlist", "replace", "list"), ...)
X 一个列表
classes 关于类名的字符向量,或者为any时则匹配任何类
deflt 默认结果,如果使用了how=”replace”,则不能使用
how 字符串匹配三种可能结果
其中,replicate 函数 不明所以,用到再研究。
5.3数据处理难题的一套解决方案
书上的处理中,步骤7重点看一下,其他的基本已经熟悉了。
sapply函数分别提取列表中每个成分的第一个元素和第二个元素并储存,用的是“[”函数,这个函数是提取某个对象的一部分。
5.4控制流
术语:
语句:statement,一条R语句或者一组R语句
条件:cond,TRUE或者FALSE
表达式:expr,一条数值或者字符串求值语句
序列:seq,一个数值或字符串序列
5.4.1重复和循环
for和while:
for(i in c(1:10)) {expr}
while(cond) {expr}
注意:尽量避免循环,尽量使用R内置函数,比如apply族函数。
5.4.2条件执行
1、if-else结构
if(cond)
statement1
else
statement2
2、ifelse结构
ifelse(cond,statement1,statement2)
是if-else的紧凑版本,如果是二元程序行为,或者希望输入输出均为向量是,用ifelse.
3、switch结构
switch(expr,...)
#这里的expr是判断条件,后面的...是对应expr的不同情况的执行情况
5.5用户自编函数
形式为:
functionname <- function(arglist) {
expr
return(object)
}
#注意arglist可以指定参数的默认值
可以用一些函数为函数添加错误捕获和纠正功能。写一下:
warning函数:
warning(..., call. = TRUE, immediate. = FALSE, noBreaks. = FALSE,
domain = NULL)
#此函数加在一个函数后面,可以显示警告信息
message函数:生成一个参数的诊断信息
#message(..., domain = NULL, appendLF = TRUE)
stop函数:#停止执行并输出一个错误信息,可以配合try使用
#stop(..., call. = TRUE, domain = NULL)
以上函数在写函数的时候可以试一试。
一旦开始自己写函数,调试就不可避免。Debugging in R,http://www.stats.uwo.ca/faculty/murdoch/software/debuggingR/,描述了不少常见的调试情况。very good!附录B描述了如何定制R环境。
“你可在本书末尾的参考文献部分找到:Venables & Ripley(2000)以及Chambers(2008)。这两本书共同提供了大量细节和众多示例。”--这是引用。
5.6整合与重构
R中提供了许多用来整合(aggregate)和重塑(reshape)数据的方法。通过整合数据,往往是将观测值数据替换为这些数据的描述统计量。重塑数据时通过修改数据的结构(行和列)来决定数据的组织方式。用mtcars为例。
5.6.1转置
t函数,将矩阵或数据框转置。
5.6.2整合数据
aggregate函数:使用一个或者多个by变量和一个预先定义好的函数FUN来折叠(collapse)数据.
aggregate(x, ...) ## Default S3 method:
aggregate(x, ...) ## S3 method for class 'data.frame' #对数据框作用
aggregate(x, by, FUN, ..., simplify = TRUE) ## S3 method for class 'formula' #对公式作用
aggregate(formula, data, FUN, ...,
subset, na.action = na.omit) ## S3 method for class 'ts' #对时间序列作用
aggregate(x, nfrequency = , FUN = sum, ndeltat = ,
ts.eps = getOption("ts.eps"), ...) #这个函数是将数据按行进行分组,把函数FUN作用在每一组数据上,注意by后面必须是list,
#即使一个参数也得用list。
#formula是一个公式: y ~ x 或者 cbind(y1, y2) ~ x1 + x2,这里y或者cbind(y1,y2)按照x或者x1+x2分组,并执行后面的函数。
#subset是指定一个数据子集
#nfrequency:时间序列每个单位时间内的新数字,必须是x频率的因数
#ndeltat:连续观测采样区间的新分数,必须是x采样间隔的因数
#ts.eps:决定nfrequency是否是原始频率的sub-multiple
5.6.3reshape包
reshape或者reshape2包是一套重构和整合数据集的“绝妙工具”,reshape2更强大。数据处理分为融合(melt)和重铸(cast)两个过程。融合过程是将每一个观测值加上唯一的标识符,重铸过程可是对数据运用“任何函数”进行整合。
看下面的一个数据形式。
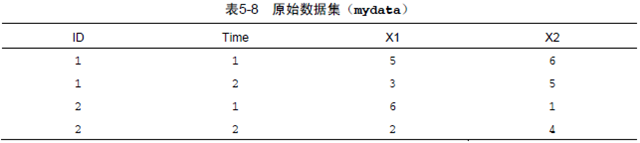
上面的数据中,每一行的值组合在一起成为唯一标识符,后面的X1和X2称为测量(measurement).
1、融合
执行下面的命令:
md <- melt(data,id=(c("id","time")))
得到下面结果:
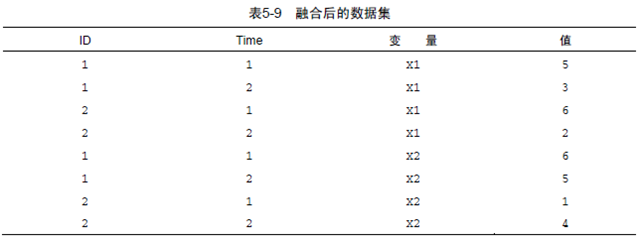
也就是说,将id和time和在一起作为唯一标识符,将每一个测量单一列出来.这里发现一个问题:要是列太多怎么办?
下面就可以用cast来对其进行重铸了.
2、重铸
用cast函数:
大致运行是这样的:
newdata <- cast(md,formula,FUN)
#md是融合以后的数据,formula描述想要的结果,而FUN是(可选的)数据整合函数.
公式的形式为
rowvar1+rowvar2+...~colvar1+colvar2+...


上面是几个例子.
下面准备开始第二部分,第一部分花的时间太多了,下面要看快点.
《R语言实战》读书笔记--第五章 高级数据管理的更多相关文章
- R语言实战读书笔记(二)创建数据集
2.2.2 矩阵 matrix(vector,nrow,ncol,byrow,dimnames,char_vector_rownames,char_vector_colnames) 其中: byrow ...
- R语言实战读书笔记(三)图形初阶
这篇简直是白写了,写到后面发现ggplot明显更好用 3.1 使用图形 attach(mtcars)plot(wt, mpg) #x轴wt,y轴pgabline(lm(mpg ~ wt)) #画线拟合 ...
- R语言实战读书笔记(五)高级数据管理
5.2.1 数据函数 abs: sqrt: ceiling:求不小于x的最小整数 floor:求不大于x的最大整数 trunc:向0的方向截取x中的整数部分 round:将x舍入为指定位的小数 sig ...
- R语言实战读书笔记1—语言介绍
第一章 语言介绍 1.1 典型的数据分析步骤 1.2 获取帮助 help.start() help("which") help.search("which") ...
- R语言实战读书笔记2—创建数据集(上)
第二章 创建数据集 2.1 数据集的概念 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和变量(variable) ,数据库分析师则称其为记录(record)和字 ...
- R语言实战读书笔记(八)回归
简单线性:用一个量化验的解释变量预测一个量化的响应变量 多项式:用一个量化的解决变量预测一个量化的响应变量,模型的关系是n阶多项式 多元线性:用两个或多个量化的解释变量预测一个量化的响应变量 多变量: ...
- R语言实战读书笔记(七)基本统计分析
summary() sapply(x,fun,options):对数据框或矩阵中的每一个向量进行统计 mean sd:标准差 var:方差 min: max: median: length: rang ...
- R语言实战读书笔记(四)基本数据管理
4.2 创建新变量 几个运算符: ^或**:求幂 x%%y:求余 x%/%y:整数除 4.3 变量的重编码 with(): within():可以修改数据框 4.4 变量重命名 包reshape中有个 ...
- R语言实战读书笔记(一)R语言介绍
1.3.3 工作空间 getwd():显示当前工作目录 setwd():设置当前工作目录 ls():列出当前工作空间中的对象 rm():删除对象 1.3.4 输入与输出 source():执行脚本
随机推荐
- GNU汇编 伪指令
伪指令 本身并没有所对应的机器码 它只是在编译的时候起作用,或者转换为其他的实际指令来运行 global ascii byte word data equ align @ 下面的例子是在数据段存放数据 ...
- JAVA / MySql 编程——第六章 Mysql 创建账户的相关命令
1. 创建普通用户: 语法: CREATE USER `user`@`host` [IDENTIFIED 'password']; //user:用户名,host:主机名,passw ...
- 解决php文字及图片显示乱码的问题
我们在学习PHP的过程中,想必有不少新手朋友们都遇到过乱码的问题,解决乱码问题不仅是小白们必须掌握的基础知识点,也是最为常见的PHP面试题之一.下面就结合简单代码示例给大家总结介绍下,PHP遇到乱码时 ...
- 基本数据类型补充,set集合,深浅拷贝等
1.join:将字符串,列表,用指定的字符连接,也可以用空去连接,这样就可以把列表变成str ll = ["wang","jian","wei&quo ...
- 将Komodo Edit打造成Python开发的IDE
Komodo Edit 支持Python 界面清爽, 将Komodo Edit 设置成Python的IDE,具体操作方法如下: 先添加自定义命令. 再设置命令行参数 设置高级选项 设置快捷键 完成.
- 华为ensp工具栏丢失解决方法
电脑是win8系统 不知道什么原因,华为模拟器的工具栏神奇的消失了,感觉很郁闷,每次要写字的时候都找不到在哪里(菜单里也没有),于是在官方论坛里面找了一下终于找出原因了. 关闭ensp,点击属性,进入 ...
- POJ 1286 Pólya定理
Necklace of Beads Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 9162 Accepted: 3786 ...
- POJ-2251 三维迷宫
题目大意:给一个三维图,可以前后左右上下6种走法,走一步1分钟,求最少时间(其实就是最短路) 分析:这里与二维迷宫是一样的,只是多了2个方向可走,BFS就行(注意到DFS的话复杂度为O(6^n)肯定会 ...
- POJ:2456-Aggressive cows
Aggressive cows Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 18313 Accepted: 8716 Desc ...
- jdk1.8源码学习笔记
前言: 前一段时间开始学习了一些基本的数据结构和算法,算是弥补了这方面的知识短板,但是仅仅是对一些算法的了解,目前工作当中也并没有应用到这些,因此希望通过结合实际例子来学习,巩固之前学到的内容,思前想 ...