kmeans聚类中的坑 基于R shiny 可交互的展示
龙君蛋君
2015年5月24日
1.背景介绍
最近公司在用R 建模,老板要求用shiny 展示结果,建模的过程中用到诸如kmean聚类,时间序列分析等方法。由于之前看过一篇讨论kmenas聚类针对某一特定数据类型,聚类结果非常不靠谱的文章,于是这个周末突发奇想,用shiny可交互的展示kmeans聚类中的坑。。。这篇博文就当是记录学习shiny和加深对kmeans、层次聚类的理解吧。
2.知识引用与学习
2)Shiny Gallery-This gallery contains useful examples to learn from
3.代码与图形展示
一个完整的shiny app 包含两个.R文件,ui.R和server.R。园主大人的这篇文章Shiny的架构浅析解释的很详细,可帮助理解shiny。
part 1 : ui.R
library(shiny)
library(dplyr)
library(broom)
shinyUI(
pageWithSidebar(
# Application title
headerPanel("kmeans VS hclust"),
sidebarPanel(
numericInput('n', 'Number of obs', 500 ,min=200 ,max=1000),
selectInput("type", "Select a clust approach:",c("kmeans","hclust"),"kmeans") ),
mainPanel(plotOutput("plot"))
)
)
part 2 : server.R
library(shiny)
library(dplyr)
library(broom)
shinyServer(function(input, output,session) {
#----data 1 for kmeans clust----
set.seed(500)
selectedData <- reactive({ rbind(
data_frame(x = rnorm(input$n), y = rnorm(input$n)),
data_frame(r = rnorm(input$n, 5, .25), theta = runif(input$n, 0, 2 * pi),
x = r * cos(theta), y = r * sin(theta)) %>%
dplyr::select(x, y)
)
})
#----data2 for hclust use----
selectedData_clust <- reactive({
cbind(selectedData(),hclust_assignments=selectedData() %>% dist() %>% hclust(method = "single") %>% cutree(2) %>% factor()%>%as.data.frame()
)
}) #-----plot-----
output$plot <- renderPlot({ switch(input$type,
"kmeans" =( plot(selectedData(),
col = kmeans(selectedData(),2)$cluster,
pch = 20, cex = 1)
), "hclust" = (plot(selectedData_clust()[,1:2],
col = selectedData_clust()[,3],
pch = 20, cex = 1)
)
)
})
#----end---
})
先解释下,用k-means进行聚类,常常假定数据是球状的,code中生成的数据集是非球状的,以便证明kmeans针对这种非球状数据集,会给出坑爹的结果。参考大数据分析之——k-means聚类中的坑。
part 3 :看图,也就是shiny的展示。
图1-kmeans聚类:
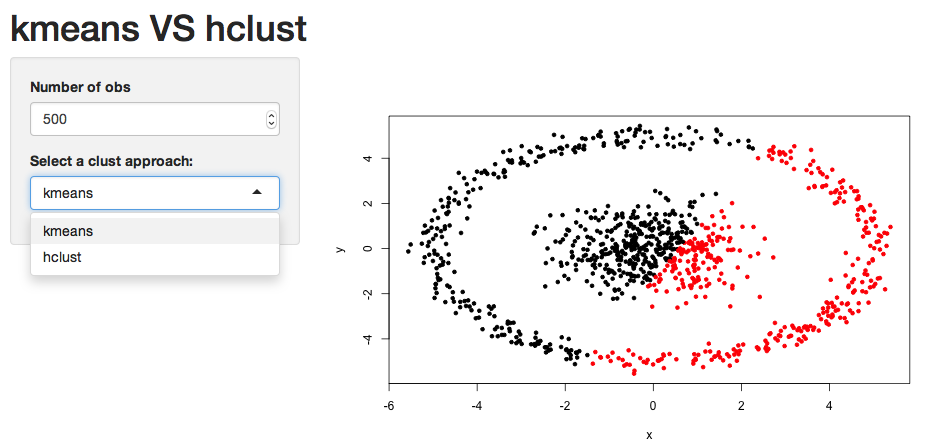
图2-hclust聚类(Hierarchical Clustering):

明显这种数据集,用层次聚类得出的结果才是正确的。
4.总结
1)要勤写博客,不能太懒!
2)Shiny Gallery-This gallery contains useful examples to learn from 这里有很多shiny 的例子,学习shiny的绝佳之地。
3)再推荐一个博客,r-bloggers 最前沿的R资讯分享,hadley都在上面写文章的哦!
4)Rstudio 真是个伟大的公司,开发了那么多好用,好玩的东西。
以上。
kmeans聚类中的坑 基于R shiny 可交互的展示的更多相关文章
- 用肘方法确定 kmeans 聚类中簇的最佳数量
说明: KMeans 聚类中的超参数是 K,需要我们指定.K 值一方面可以结合具体业务来确定,另一方面可以通过肘方法来估计.K 参数的最优解是以成本函数最小化为目标,成本函数为各个类畸变程度之和,每个 ...
- (数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明. 数据说明: 本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉 ...
- K-Means 聚类
机器学习中的算法主要分为两类,一类是监督学习,监督学习顾名思义就是在学习的过程中有人监督,即对于每一个训练样本,有对应的标记指明它的类型.如识别算法的训练集中猫的图片,在训练之前会人工打上标签,告诉电 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
- k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
来源:, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, ...
- 基于R实现k-means法与k-medoids法
k-means法与k-medoids法都是基于距离判别的聚类算法.本文将使用iris数据集,在R语言中实现k-means算法与k-medoids算法. k-means聚类 首先删去iris中的Spec ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
随机推荐
- 转 Alert.log shows No Standby Redo Logfiles Of Size 153600 Blocks Available
http://blog.itpub.net/23135684/viewspace-703620/ Alert.log shows No Standby Redo Logfiles Of Size 15 ...
- input校验不能以0开头的数字
不以零开头 <input type="text" class="form-control" onkeyup="value=value.rep ...
- 使用cucumber & selenium实现一个简单的bddtest
1.Cucumber介绍 + feature : read requirement +scenario : testing situation,including + Given/ + when/ + ...
- 06-spring常见的连接池配置
1 准备工作 首先,我们准备jdbc属性文件 database.properties,用于保存连接数据库的信息,利于我们在配置文件中使用. 只要在applicationContext.xml(Spri ...
- mac os安装macvim
1 brew install macvim 安装 macvim 2 alias vim='/usr/local/Cellar/macvim/7.4-73_1/MacVim.app/Contents/M ...
- java多线程优先级问题
java 中的线程优先级的范围是1-10,默认的优先级是5.“高优先级线程”会优先于“低优先级线程”执行. 例子: package com.ming.thread.threadpriority; pu ...
- pat1091. Acute Stroke (30)
1091. Acute Stroke (30) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue One impo ...
- HDU 5375——Gray code——————【dp||讨论】
Gray code Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total S ...
- AngularJS 学习(-)Hello world
早期的AngularJS使我们的前端开发模式发生很大的变化,基使用MVC. Model - html 模板:Controller - js脚本; Model 来自于Web API 或其他Service ...
- display详细说明
display:block,inline,inline-block区别 display:block就是将元素显示为块级元素. block元素的特点是: 总是在新行上开始: 高度,行高以及顶和底边距都可 ...