NeurIPS2018: DropBlock: A regularization method for convolutional networks
NIPS 改名了!改成了neurips了。。。
深度神经网络在过参数化和使用大量噪声和正则化(如权重衰减和 dropout)进行训练时往往性能很好。dropout 广泛用于全连接层的正则化,但它对卷积层的效果没那么好。原因可能在于卷积层中的激活单元是空间关联的,使用 dropout 后信息仍然能够通过卷积网络传输到下一层。相比于dropout一个一个扔掉神经元,自然而然我们就要成块成块扔。因此就产生了这种叫dropblock的方法来对卷积网络进行正则化约束,它会丢弃特征图相邻区域中的单元。此外,在训练过程中逐渐增加丢弃单元的数量会带来更高的准确率,使模型对超参数选择具备更强的鲁棒性。
如下图更加形象生动:

图(a)中图片狗的区域是包含语义信息的,(b)中dropout扔神经元基本是这样随机扔,这就导致了很多狗这个实例的相关性信息被保存下来了,如(c), dropblock的思想是随机找一些点,然后自定义一个区域(block)把这里的信息一股脑全扔了。这样语义信息就不会冗余,从一定程度上使学习到的特征更加鲁棒。
如何操作:
block_size: 控制block的区域大小
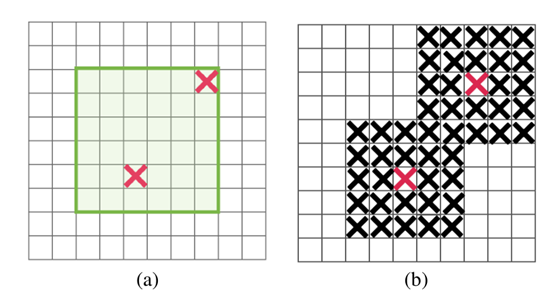
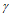 : 控制丢掉多少神经元,注意这里的神经元不是真正丢了,而是某一次不用它的概率。
: 控制丢掉多少神经元,注意这里的神经元不是真正丢了,而是某一次不用它的概率。

参数设置:
Blocksize设置为1的时候和dropout类似,但是只在图中绿色区域丢
 设置:
设置:
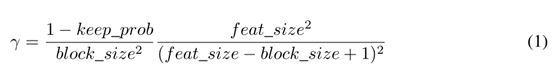
Keep_prob 为保存信息的比率
feat_size 为整个feature map的大小
feat_size-block_size+1 为绿色区域的大小,我把它命名为语义信息区域吧。。
我的想法:
读了这篇文章,我倒是有些想法,我们的目标不是去除图像像素之间的冗余特征吗,那么我们根据这样一句话:
the m best features are not the best m features....在卷积层与全连接层的中间加一个去冗余层。
扔特征的目标是不是就是找出含有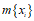 个特征的特征子集S?其实相对于也是丢弃一部分特征
个特征的特征子集S?其实相对于也是丢弃一部分特征
那我们这样:
1:与标签的最大相关性:
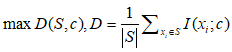 (2)
(2)
C为类别,S 为特征子集,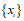 为第i个特征。
为第i个特征。
变量间的最小冗余度:
 (3)
(3)
其中I函数为给定两个随机变量x和y,他们的概率密度函数(对应于连续变量)为p(x),p(y),p(x,y)p(x),p(y),p(x,y),则互信息为 :
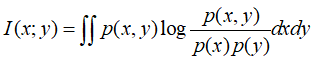
那么我们整个神经网络优化公式为:
传统损失 - 公式(2)+公式(3)
当然上面思想主要来自于mrmr算法,正好可以结合卷积来做一下。一点初步的idea,有空实现下,在来分享。
NeurIPS2018: DropBlock: A regularization method for convolutional networks的更多相关文章
- (原)DropBlock A regularization method for convolutional networks
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/9985027.html 论文网址: https://arxiv.org/abs/1810.12890 ...
- (转)ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks by KO ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- 论文翻译——Character-level Convolutional Networks for Text Classification
论文地址 Abstract Open-text semantic parsers are designed to interpret any statement in natural language ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 这篇论文
由Andrew Zisserman 教授主导的 VGG 的 ILSVRC 的大赛中的卷积神经网络取得了很好的成绩,这篇文章详细说明了网络相关事宜. 文章主要干了点什么事呢?它就是在在用卷积神经网络下, ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition 转载请注明:http://blog.csdn.net/stdcou ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
随机推荐
- 【VBA】获取Excle的安装路径
在VBA中,如何获取Excle的安装路径呢?请看以下代码: Sub 获取Excle的安装路径() MsgBox "Excle的安装路径为:" & Application.P ...
- 命令行添加pod示例
1.创建AlamFireDemo 工程,关闭工程 2.进入到工程目录 执行 pod init 命令 生成 PodFile文件 3.vi PodFile编辑该文件 启用:platform :ios, ' ...
- 正则化--L2正则化
请查看以下泛化曲线,该曲线显示的是训练集和验证集相对于训练迭代次数的损失. 图 1 显示的是某个模型的训练损失逐渐减少,但验证损失最终增加.换言之,该泛化曲线显示该模型与训练集中的数据过拟合.根据奥卡 ...
- Memcached的LRU和缓存命中率
缓存命中率 命中:直接从缓存中读取到想要的数据. 未中:缓存中没有想要的数据,还需要到数据库进行一次查询才能读取到想要的数据. 命中率越高,数据库查询的次数就越少. 读取缓存的速度远比数据库查询的速度 ...
- Windows 10 优化
---恢复内容开始--- 0x00 使开始菜单,任务栏,和操作中心透明 --关闭 右下角开始菜单,选择设置,打开个性化菜单,找到颜色一栏.向下滑至最低端,使开始菜单,任务栏,和操作中心透明选项关闭 0 ...
- ASP.NET MVC自定义视图引擎ViewEngine 创建Model的专属视图
MVC内置的视图引擎有WebForm view engine和Razor view engine,当然也可以自定义视图引擎ViewEngine. 本文想针对某个Model,自定义该Model的专属视图 ...
- kafka eagle 使用教程
下载 地址:http://download.smartloli.org/ github:https://github.com/smartloli/kafka-eagle 环境 Windows: 安装J ...
- MapReduce源码分析之JobSplitWriter
JobSplitWriter被作业客户端用于写分片相关文件,包括分片数据文件job.split和分片元数据信息文件job.splitmetainfo.它有两个静态成员变量,如下: // 分片版本,当前 ...
- 4.关于QT中的QFile文件操作,QBuffer,Label上加入QPixmap,QByteArray和QString之间的差别,QTextStream和QDataStream的差别,QT内存映射(
新建项目13IO 13IO.pro HEADERS += \ MyWidget.h SOURCES += \ MyWidget.cpp QT += gui widgets network CON ...
- redis+node.js
1.什么的cache 是一种更快的记忆存储数据集 存储空间有限 储存一部分重要数据 是一种相对的概念,只要比原本数据存储更快的介质就能作为cache 2.caching 策略 有限的存储空间,只能存储 ...