爬虫技术框架——Heritrix
Heritrix是一个由Java开发的开源Web爬虫系统,用来获取完整的、精确的站点内容的深度复制,
具有强大的可扩展性,运行开发者任意选择或扩展各个组件,实现特定的抓取逻辑。
一、Heritrix介绍
Heritrix采用了模块化的设计,用户可以在运行时选择要用的模块。它由核心类(core classes)和插件模块(pluggable modules)构成。
核心类可以配置,但不能被覆盖,插件模块可以由第三方模块取代。所以我们就可以用实现了特定抓取逻辑的第三方模块来取代默认的插件模块,从而满足自己的抓取需要。
CrawlController(下载控制器)整个下载过程的总控制者,整个抓取工作的起点,决定整个抓取任务的开始和结束。每个URI都有一个独立的线程,它从边界控制器(Frontier)获取新的URI,然后传递给Processor chains(处理链)经过一系列Processor(处理器)处理。
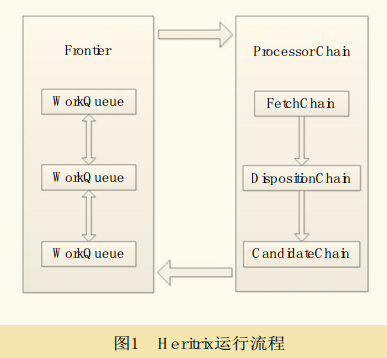
二、Heritrix架构
中央控制器 CrawlController 是核心组件,决定了整个抓取任务的开始与结束。
用户在 Heritrix web UI 控制台设置抓取任务后,heritrix首先构造XMLSettingsHandler对象,然后调用CrawlController的构造函数,构造一个CrawlController实例并初始化,这样,CrawlController就具备了运行条件。
此时,只需调用 requestCrawlStart()方法就可以启动线程池和Frontier,以便向线程池中工作线程提供抓取用的URL链接。
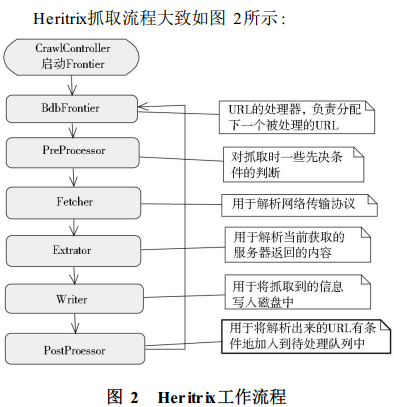
Heritrix 3.x 的框架主要分为 Engine 和 Component
三、一些API
org.archive.crawler.framework.CrawlJob;
org.archive.crawler.postprocessor.CandidatesProcessor;
org.archive.modules.CrawlURI;
等等
抓取任务CrawlOrder类:是整个抓取工作的起点。一次抓取任务包括许多属性,建立一个任务的方式有很多种,最简单的一种就是根据默认的order.xml来配置。
中央控制器CrawlController:该类决定着抓取任务的开始和结束。它包含以下几个组件:
CrawlOrder:该类保存了order.xml的属性配置;
CrawlScope:决定当前抓取范围;
ProcessorChainList:处理器链;
Frontier:一次抓取任务需要设定一个Frontier,以此来不断为其每个线程提供URI;
ToePool:它是一个线程池,管理了所有在当前任务中抓取过的Host名称和Server名称。
中央控制器CrawlControllr的类结构如图所示:
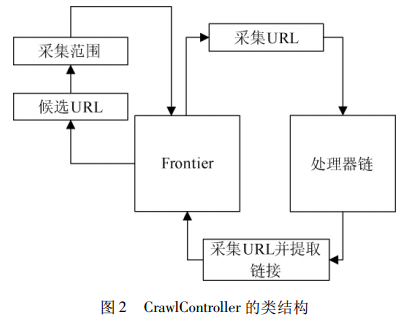
Frontier链接制造工厂:它表示一种为线程提供链接的工具,通过一些特定的算法来决定哪个链接将接下来被送入处理器链中,同时,它本身也负责一定的日志和状态报告功能。
BdbFrontier类:它是用Berkeley DB 实现的,Berkeley DB 就是一个HashTable,它能够按“key/value”方式保存数据,能够为应用程序提供可伸缩的、高性能的、有事务保护功能的嵌入式数据库。
Heritrix的多线程ToeThread和ToePool:要想更快更有效地抓取网页,必须采用多线程,Heritrix则采用多线程机制,提供了一个标准的线程池ToePool,用于管理所有的抓取线程。
处理器链 Processor:包括PreProcessor、Fetcher、Extractor、Writer、PostProcessor五种。
四、应用
作为爬虫模块,爬取数据
扫个红包吧!

Donate捐赠
如果我的文章帮助了你,可以赞赏我 6.66 元给我支持,让我继续写出更好的内容)


(微信) (支付宝)
微信/支付宝 扫一扫
爬虫技术框架——Heritrix的更多相关文章
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- .net 爬虫技术
关于爬虫 从搜索引擎开始,爬虫应该就出现了,爬的对象当然也就是网页URL,在很长一段时间内,爬虫所做的事情就是分析URL.下载WebServer返回的HTML.分析HTML内容.构建HTTP请求的模拟 ...
- 使用webcollector爬虫技术获取网易云音乐全部歌曲
最近在知乎上看到一个话题,说使用爬虫技术获取网易云音乐上的歌曲,甚至还包括付费的歌曲,哥瞬间心动了,这年头,好听的流行音乐或者经典老歌都开始收费了,只能听不能下载,着实很郁闷,现在机会来了,于是开始研 ...
- 利用python的爬虫技术爬去糗事百科的段子
初次学习爬虫技术,在知乎上看了如何爬去糗事百科的段子,于是打算自己也做一个. 实现目标:1,爬取到糗事百科的段子 2,实现每次爬去一个段子,每按一次回车爬取到下一页 技术实现:基于python的实现, ...
- 爬虫技术实现空间相册采集器V.0.0.1版本
一. 功能需求分析: 在很多时候我们需要做这样一个事情:我们想把我们QQ空间上的相册高清图像下载下来,怎么做?到网上找软件?答案是否定的,理由之一:网上很多软件不知有没有病毒,第二它有可能捆了很 ...
- 使用jsoup十分钟内掌握爬虫技术
对,就是十分钟,没有接触过爬虫的你,肯定一脸懵逼,感觉好高深的样子,一开始我也有点懵,但用了以后发现还是很简单的,java爬虫框架有很多,让我有种选择困难症,通过权衡比较还是感觉jsoup比较好用些, ...
- 总结整理 -- 爬虫技术(C#版)
爬虫技术学习总结 爬虫技术 -- 基础学习(一)HTML规范化(附特殊字符编码表) 爬虫技术 -- 基本学习(二)爬虫基本认知 爬虫技术 -- 基础学习(三)理解URL和URI的联系与区别 爬虫技术 ...
- App技术框架
一.App技术框架的类型 图1 三种App技术框架之间的关系 目前App的技术框架基本分为三种(图1): (1)Native App:互动型,iOS.Android.WP各一套,而且要维护历史版本,要 ...
随机推荐
- spring读取配置文件,且获取bean实例
import org.springframework.beans.factory.BeanFactory;import org.springframework.beans.factory.xml.Xm ...
- powdesigner建表
默认打开powerDesigner时,创建table对应的自动生成sql语句没有注释. 方法1.comment注释信息 在Columns标签下,一排按钮中找到倒数第2个按钮:Customize Col ...
- git push fatal: HttpRequestException encountered
原因: github禁用了TLS1.0/1.1协议 截至2018年2月22日,GitHub禁用了对弱加密的支持,这意味着许多用户会突然发现自己无法使用Git for Windows进行身份验证(影响版 ...
- CF628D Magic Numbers (数据大+数位dp)求[a,b]中,偶数位的数字都是d,其余为数字都不是d,且能被m整除的数的个数
题意:求[a,b]中,偶数位的数字都是d,其余为数字都不是d,且能被m整除的数的个数(这里的偶数位是的是从高位往低位数的偶数位).a,b<10^2000,m≤2000,0≤d≤9 a,b< ...
- SQL常用性能统计语句
1.查看SQL语句IO消耗 set statistics io on sql 语句 set statistics io off 2.查看SQL语句时间消耗 set statistics tim ...
- Asp.net获取系统信息
[DllImport("kernel32")] public static extern void GlobalMemoryStatus(ref MEMORY_INF ...
- MB Star C5 Functions
The MB STAR C5 notion and brand combination for hardware and software program components will be the ...
- Android Studio配置及使用OpenCV
1.下载及目录介绍 进入官网(http://opencv.org/)下载OpenCV4Android并解压(这里是OpenCV-3.2.0-android-sdk).下面是目录的结构图: sdk ...
- suffix ACM-ICPC 2017 Asia Qingdao
Consider n given non-empty strings denoted by s1 , s2 , · · · , sn . Now for each of them, you need ...
- 3n+1猜想
1001. 害死人不偿命的(3n+1)猜想 (15) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 卡拉兹(Ca ...