Oracle 多表查询(1)
一、基本概念
多表查询的语法如下:
SELECT [DISTINCT] * | 字段 [别名] [,字段 [别名] ,…]FROM 表名称 [别名], [表名称 [别名] ,…][WHERE 条件(S)][ORDER BY 排序字段 [ASC|DESC] [,排序字段 [ASC|DESC] ,…]];
但是如果要进行多表查询之前,首先必须先查询出几个数据 —— 雇员表和部门表中的数据量,这个操作可以通过COUNT()函数完成。
范例:查询emp表中的数据量 ——返回了14条记录
SELECT COUNT(*) FROM emp;
范例:查询dept表中的数据量 ——4条记录
SELECT COUNT(*) FROM dept;
额外补充一点:何为经验?
在日后的开发之中,很多人都肯定要接触到许多新的数据库和数据表,那么在这种时候有两种做法:
做法一:新人做法,上来直接输入以下的命令:
SELECT * FROM 表名称;
如果此时数据量较大的话,一上无法浏览数据,二有可能造成系统的死机;
做法二:老人做法,先看一下有多少条记录:
SELECT COUNT(*) FROM 表名称;
如果此时数据量较小,则可以查询全部数据,如果数据量较大则不能直接使用SELECT查询。
现在确定好了emp和dept表中的记录之后,下面完成一个基本的多表查询:
SELECT * FROM emp, dept;
但是现在查询之后发现一共产生了56条记录 = 雇员表的14条记录 * 部门表的4条记录,之所以会造成这样的问题,主要都是由数据库的查询机制所决定的,例如,如下图所示。

本问题在数据库的操作之中被称为笛卡尔积,就表示多张表的数据乘积的意思,但是这种查询结果肯定不是用户所希望的,那么该如何去掉笛卡尔积呢?
最简单的方式是采用关联字段的形式,emp表和dept表之间现在存在了deptno的关联字段,所以现在可以从这个字段上的判断开始。
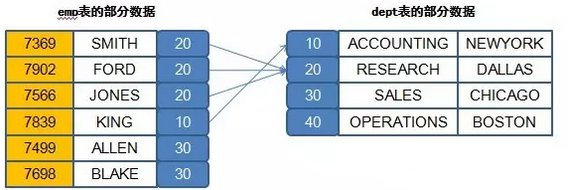
当在查询之中,不同的表中有了相同字段名称的时候,访问这些字段必须加上表名称,即“表.字段”。
SELECT * FROM empWHERE emp.deptno=dept.deptno;
此时的查询结果之中已经消除了笛卡尔积,但是现在只属于显示上的消除,而真正笛卡尔积现在依然存在,因为数据库的操作机制就属于逐行的进行数据的判断,那么如果按照这个思路理解的话,现在假设两张表的数据量都很大的话,那么使用这种多表查询的性能。
范例:以sh用户的大数据表为例
SELECT COUNT(*) FROM sales, costsWHERE sales.prod_id=costs.prod_id;
这两张表即便消除了笛卡尔积的显示,但是本身也会有笛卡尔积的问题,所以最终的查询结果会很慢显示,甚至是不显示,所以通过这道程序一定要记住,多表查询的性能是很差的,当然,性能差是有一个前提的:数据量大。
但是以上的程序也存在一个问题,在之前访问表中字段的时候使用的是“表.字段”名称,那么如果说现在假设表名称很长,例如“yinhexi_diqiu_yazhou_zhongguo_beijing_xicheng_ren”,所以一般在进行多表查询的时候往往都会为表起一个别名,通过别名.字段的方式进行查询。
SELECT * FROM emp e, dept dWHERE e.deptno=d.deptno;
范例:查询出每一位雇员的编号、姓名、职位、部门名称、位置
1、确定所需要的数据表:
emp表:可以查询出雇员的编号、姓名、职位;
dept表:可以查询出部门名称和位置;
2、确定表的关联字段:emp.deptno=dept.deptno;
第一步:查询出每一位雇员的编号、姓名、职位
SELECT e.empno, e.ename, e.jobFROM emp e;
第二步:为查询中引入部门表,同时需要增加一个消除笛卡尔积的条件
SELECT e.empno, e.ename, e.job, d.dname, d.locFROM emp e, dept, dWHERE e.deptno=d.deptno;
以后遇到问题,发现没有解决问题的思路,就按照上面的步骤进行,慢慢的分析解决,因为多表查询不可能一次性全部写出,需要逐步分析的。
范例:要求查询出每一位雇员的姓名、职位、领导的姓名。
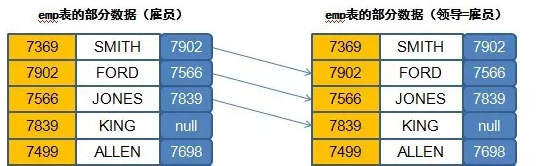
现在肯定要准备出两个emp表,所以这个时候可以称为emp表的自身关联,按照之前的分析如下:
1、确定所需要的数据表:
emp表(雇员):取得雇员的姓名、职位、领导编号;
emp表(领导):取得雇员的姓名(领导的姓名);
2、确定关联字段:emp.mgr=memp.empno(雇员的领导编号 = 领导(雇员)的雇员编号)
第一步:查询每一位雇员的姓名、职位
SELECT e.ename, e.jobFROM emp e;
第二步:查询领导信息,加入自身关联
SELECT e.ename, e.job, m.enameFROM emp e, emp mWHERE e.mgr=m.empno;
此时的查询结果之中缺少了“KING”的记录,因为KING没有领导,而要想解决这个问题,就需要等待之后讲解的左、右连接的问题了。
范例:查询出每个雇员的编号、姓名、基本工资、职位、领导的姓名、部门名称及位置。
1、确定所需要的数据表:
emp表:每个雇员的编号、姓名、基本工资、职位;
emp表(领导):领导的姓名;
dept表:部门的名称及位置。
2、确定已知的关联字段:
雇员和部门:emp.deptno=dept.deptno;
雇员和领导:emp.mgr=memp.empno;
第一步:查询出每个雇员的编号、姓名、基本工资、职位
SELECT empno, ename, sal, jobFROM emp;
第二步:加入领导的信息,引入自身关联,同时增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, e.job, m.enameFROM emp e, emp mWHERE e.mgr=m.empno;
第三步:加入部门的信息,引入dept表,既然有新的表进来,则需要继续增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, e.job, m.ename, d.dname, d.locFROM emp e, emp m, dept dWHERE e.mgr=m.empno AND e.deptno=d.deptno;
所以以后的所有类似的问题最好都能够按照如上的方式编写,形成自己的思路。
思考题:现在要求查询出每一个雇员的编号、姓名、工资、部门名称、工资所在公司的工资等级。
1、确定所需要的数据表:
emp表:雇员的编号、姓名、工资;
dept表:部门名称;
salgrade表:工资等级;
2、确定已知的关联字段:
雇员和部门:emp.deptno=dept.deptno;
雇员和工资等级:emp.sal BETWEEN salgrade.losal AND salgrade.hisal;
第一步:查询出每一个雇员的编号、姓名、工资
SELECT e.empno, e.ename, e.salFROM emp e;
第二步:引入部门表,同时增加一个消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, d.dnameFROM emp e, dept dWHERE e.deptno=d.deptno;
第三步:引入工资等级表,继续增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, d.dname, s.gradeFROM emp e, dept d, salgrade sWHERE e.deptno=d.deptno AND e.sal BETWEEN s.losal AND s.hisal;
如果现在有如下的进一步要求:将每一个工资等级替换成具体的文字信息,例如:
1 替换成 第五等工资、2 替换成 第四等工资、3 替换成 第三等工资,依次类推 --> 依靠DECODE()实现
SELECT e.empno, e.ename, e.sal, d.dname
DECODE(s.grade,1,’第五等工资’,2,’第四等工资’,3,’第三等工资’,4,’第二等工资’,5,’第一等工资’) gradeinfoFROM emp e, dept d, salgrade sWHERE e.deptno=d.deptno AND e.sal BETWEEN s.losal AND s.hisal;
以后的所有的题目都按照类似的方式分析,只要是表关联,肯定有关联字段,用于消除笛卡尔积,只是这种关联字段需要根据情况使用不同的限定符号。
二、左、右连接
关于左、右连接指的是查询判断条件的参考方向,例如,下面有如下查询:
SELECT * FROM emp e, dept d WHERE e.deptno=d.deptno;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- ---------
7782 CLARK MANAGER 7839 09-6月 -81 2450 10 10 ACCOUNTING NEW YORK
7839 KING PRESIDENT 17-11月-81 5000 10 10 ACCOUNTING NEW YORK
7934 MILLER CLERK 7782 23-1月 -82 1300 10 10 ACCOUNTING NEW YORK
7369 SMITH CLERK 7902 17-12月-80 800 20 20 RESEARCH DALLAS
7876 ADAMS CLERK 7788 23-5月 -87 1100 20 20 RESEARCH DALLAS
7902 FORD ANALYST 7566 03-12月-81 3000 20 20 RESEARCH DALLAS
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 20 RESEARCH DALLAS
7566 JONES MANAGER 7839 02-4月 -81 2975 20 20 RESEARCH DALLAS
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 30 SALES CHICAGO
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 30 SALES CHICAGO
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 30 SALES CHICAGO
7900 JAMES CLERK 7698 03-12月-81 950 30 30 SALES CHICAGO
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 30 SALES CHICAGO
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 30 SALES CHICAGO 已选择14行。
部门一共有四个,但是现在只返回了三个部门的信息,缺少40部门,因为在雇员表之中没有一条记录是属于40部门的,所以现在不会显示40部门的信息,即:现在的查询以emp表为参考,那么如果说现在非要显示40部门呢?就必须改变这种参考的方向,就需要用使用左、右连接。
SELECT * FROM emp e, dept d WHERE e.deptno(+)=d.deptno;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- ---------
7782 CLARK MANAGER 7839 09-6月 -81 2450 10 10 ACCOUNTING NEW YORK
7839 KING PRESIDENT 17-11月-81 5000 10 10 ACCOUNTING NEW YORK
7934 MILLER CLERK 7782 23-1月 -82 1300 10 10 ACCOUNTING NEW YORK
7369 SMITH CLERK 7902 17-12月-80 800 20 20 RESEARCH DALLAS
7876 ADAMS CLERK 7788 23-5月 -87 1100 20 20 RESEARCH DALLAS
7902 FORD ANALYST 7566 03-12月-81 3000 20 20 RESEARCH DALLAS
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 20 RESEARCH DALLAS
7566 JONES MANAGER 7839 02-4月 -81 2975 20 20 RESEARCH DALLAS
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 30 SALES CHICAGO
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 30 SALES CHICAGO
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 30 SALES CHICAGO
7900 JAMES CLERK 7698 03-12月-81 950 30 30 SALES CHICAGO
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 30 SALES CHICAGO
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 30 SALES CHICAGO
40 OPERATIONS BOSTON 已选择15行。
现在发现40部门出现了,所以发现参考的方向已经改变了,而“(+)”就用于左、右连接的更改,这种符号有以下两种使用情况:
(+)=:放在了等号的左边,表示的是右连接;
=(+):放在了等号的右边,表示的是左连接;
但是不用去刻意的区分是左还是右,只是根据查询结果而定,如果发现有些需要的数据没有显示出来,就使用此符号更改连接方向。
范例:查询每个雇员的姓名和领导的姓名
SELECT e.ename, e.job, m.enameFROM emp e, emp mWHERE e.mgr=m.empno(+);
可是这种符号是Oracle数据库自己所独有的,其他数据库不能使用。
三、SQL:1999语法
除了以上的表连接操作之外,在SQL语法之中,也提供了另外一套用于表连接的操作SQL,格式如下:
SELECT table1.column,table2.columnFROM table1 [CROSS JOIN table2]|[NATURAL JOIN table2]|[JOIN table2 USING(column_name)]|[JOIN table2 ON(table1.column_name=table2.column_name)]|[LEFT|RIGHT|FULL OUTER JOIN table2 ON(table1.column_name=table2.column_name)];
以上实际上是属于多个语法的联合,下面分块说明语法的使用。
1、交叉连接(CROSS JOIN):用于产生笛卡尔积
SELECT * FROM emp CROSS JOIN dept;
笛卡尔积本身并不是属于无用的内容,在某些情况下还是需要使用的。
2、自然连接(NATURAL JOIN):自动找到匹配的关联字段,消除掉笛卡尔积
SELECT * FROM emp NATURAL JOIN dept;
但是并不是所有的字段都是关联字段,设置关联字段需要通过约束指定;
3、JOIN…USING子句:用户自己指定一个消除笛卡尔积的关联字段
SELECT * FROM emp JOIN dept USING(deptno);
4、JOIN…ON子句:用户自己指定一个可以消除笛卡尔积的关联条件
SELECT * FROM emp JOIN dept ON(emp.deptno=dept.deptno);
5、连接方向的改变:
左(外)连接:LEFT OUTER JOIN…ON;
右(外)连接:RIGHT OUTER JOIN…ON;
全(外)连接:FULL OUTER JOIN…ON; --> 把两张表中没有的数据都显示
SELECT * FROM emp RIGHT OUTER JOIN dept ON(emp.deptno=dept.deptno);
在Oracle之外的数据库都使用以上的SQL:1999语法操作,所以这个语法还必须会一些(如果你一直使用的都是Oracle就可以不会了)。
再次强调:多表查询的性能肯定不高,而且性能一定要在大数据量的情况下才能够发现。
Oracle 多表查询(1)的更多相关文章
- oracle系统表查询
oracle查询用户下的所有表 select * from all_tab_comments -- 查询所有用户的表,视图等select * from user_tab_comments -- 查询本 ...
- Oracle锁表查询和解锁方法
数据库操作语句的分类 DDL:数据库模式定义语言,关键字:create DML:数据操纵语言,关键字:Insert.delete.update DCL:数据库控制语言 ,关键字:grant.remov ...
- oracle锁表查询
ORACLE EBS操作某一个FORM界面,或者后台数据库操作某一个表时发现一直出于"假死"状态,可能是该表被某一用户锁定,导致其他用户无法继续操作 复制代码代码如下: --锁表查 ...
- oracle 字典表查询
1.oracle 字典表查询 /*显示当前用户*/ show user 在sql plus中可用,在pl sql中不可用 /*查看所有用户名*/ select username,user_id,cre ...
- Oracle——多表查询
本次预计讲解的知识点 1. 多表查询的操作.限制.笛卡尔积的问题: 2. 统计函数及分组统计的操作: 3. 子查询的操作,并且结合限定查询.数据排序.多表查询.统计查询一起完成各个复杂查询的操作: 一 ...
- oracle锁表查询,资源占用,连接会话,低效SQL等性能检查
查询oracle用户名,机器名,锁表对象 select l.session_id sid, s.serial#, l.locked_mode, l.oracle_username, l.os_user ...
- oracle 多表查询
1.注意点 在查询过程中,不确定数据库表中的数据量,先查询数据量,数据量较大,则不能直接查询(select * from emp),如果数据量较大,直接查询容易造成死机或者数据读取较慢,如果较小可以查 ...
- oracle多表查询
多表查询首先要避免笛卡尔集,要避免笛卡尔集,那么查询条件不得少于表的个数-1. 1.显示雇员名,雇员工资以及雇员所在的部门: 2.显示部门号为10的部门名.员工名和工资: 3.显示各个雇员的姓名,工资 ...
- Oracle锁表查询与解锁
锁表查询和解锁 --查询SELECT object_name, machine, s.sid, s.serial# FROM gv$locked_object l, dba_objects o, gv ...
随机推荐
- 第四节课-反向传播&&神经网络1
2017-08-14 这节课的主要内容是反向传播的介绍,非常的详细,还有神经网络的部分介绍,比较简短. 首先是对求导,梯度的求解.反向传播的核心就是将函数进行分解,分段求导,前向计算损失,反向计算各个 ...
- php记录代码执行时间
$t1 = microtime(true); // ... 执行代码 ... $t2 = microtime(true); echo '耗时'.round($t2-$t1,3).'秒'; 简单说一下. ...
- source insigt、pc-lint、VS联合使用
前言: 近几天参加公司培训,公司要求,开发的时候使用source insight.PC-lint和VC来编程和调试,这不用不知道,一用吓一跳,这套工具一组合简直爽的根本停不下来. 先说一下各自的作用, ...
- HDFS文件访问权限
HDFS中的文件访问权限 针对文件和目录,HDFS的权限模式与POSIX非常相似一共提供三类权限模式:只读权限(r).写入权限(w)和可执行权限(x).读取文件或列出目录内容时需要只读权限.写入一个文 ...
- Elasticsearch Suggester 学习
suggester搜索就像百度搜索框中的提示类似. Elasticsearch 中提供类似的搜索功能. 答案就在Suggesters API. Suggesters基本的运作原理是将输入的文本分解为t ...
- div css 练习1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 英语发音规则---U字母-[复习中]
英语发音规则---U字母 一.总结 一句话总结:(注:本文所有//的音标为英音音标,[]的音标为美音音标) 1.U在开音节中发[ju ]/ ju: /? duty /'djuːtɪ/ ['dʊti] ...
- 代码题(59)— 字符串相加、字符串相乘、打印最大n位数
1.415. 字符串相加 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和. 思路:和链表相加类似,求进位. class Solution { public: string addS ...
- MLPClassifier 隐藏层不包括输入和输出
多层感知机(MLP)原理简介 多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以 ...
- element-ui dialog组件添加可拖拽位置 可拖拽宽高
edge浏览器下作的gifhttp://www.lanourteam.com/%E6... 有几个点需要注意一下 每个弹窗都要有唯一dom可操作 指令可以做到 拖拽时要添加可拖拽区块 header 由 ...