深入理解RocketMQ(四)--消息存储
一、MQ存储分类
MQ存储主要分为以下三类:
文件系统:RocketMQ/Kafka/RabbitMQ
关系型数据库DB:ActiveMQ(默认采用的KahaDB做消息存储)可选用JDBC的方式来做消息持久化
分布式KV存储:ZeroMQ
对比:
存储效率, 文件系统>分布式KV存储>关系型数据库DB
易于实现和快速集成,关系型数据库DB>分布式KV存储>文件系统,但是性能会下降很多
二、RocketMQ存储概要
(一)存储文件
RocketMQ文件存储在rocketmq文件夹下的store文件夹内,里面包含commitlog、config、consumerqueue、index这四个文件夹和abort、checkpoint两个文件。
其中,commitlog内存储的是消息内容
config内存储的是一些配置信息
consumerqueue存储的是topic信息
index存储的是消息队列的索引文件
abort主要是标记mq是正常退出还是异常退出
checkpoint文件存储的是commitlog、consumerqueue、index文件的刷盘时间
对于以上内容,下文会详细说明。
文件层级如下(一个层级代表一个文件夹):
rocketmq
|--store
|-commitlog
| |-00000000000000000000
| |-00000000001073741824
|-config
| |-consumerFilter.json
| |-consumerOffset.json
| |-delayOffset.json
| |-subscriptionGroup.json
| |-topics.json
|-consumequeue
| |-SCHEDULE_TOPIX_XXX
| |-topicA
| |-topicB
| |-0
| |-1
| |-2
| |-3
| |-00000000000000000000
| |-00000000001073741824
|-index
| |-00000000000000000000
| |-00000000001073741824
|-abort
|-checkpoint
(二)对象封装
对于磁盘上的对剑,在程序内都有对应的封装对象,实际操作的时,启动时,加载磁盘内容到封装对象,处理时,处理的是封装的对象,最后再刷盘到磁盘中。
(1)CommitLog: 对应commitlog文件
(2)ConsumeQueue:对应consumerqueue文件
(3)IndexFile:对应index文件
(4)MappedFile:文件存储的直接内存映射业务抽象封装类,源码中通过操作该类,可以把消息字节写入内存映射缓存区(commit),或者原子性地将消息持久化的刷盘(flush);
(5)MapedFileQueue:对连续物理存储的抽象封装类,源码中可以通过消息存储的物理偏移量位置快速定位该offset所在MappedFile(具体物理存储位置的抽象)、创建、删除MappedFile等操作;
(6)MappedFileBuff:堆外内存
三、文件存储
(一)存储对象关系
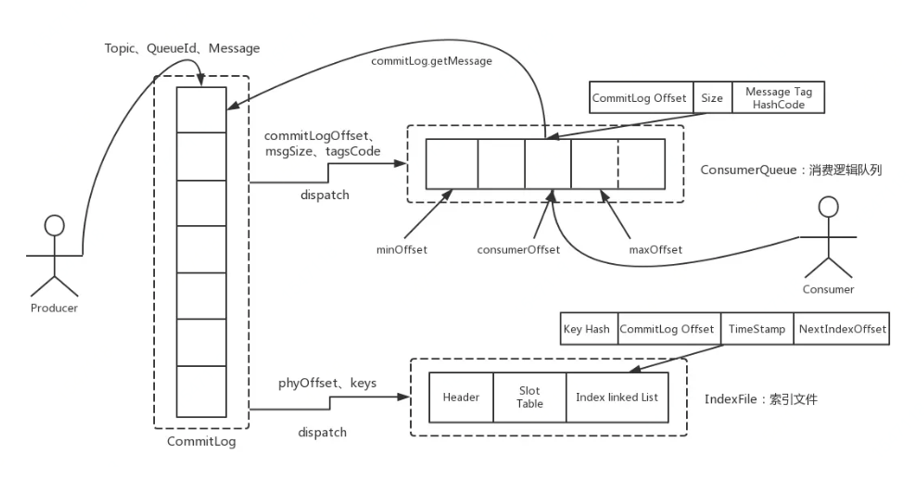
消息存储的主要流程:
生产者发送消息后,消息存储:
(1)将消息内容存入commitlog文件
(2)将topic信息存入consumerqueue文件,里面存入包括topic、起始偏移量、消息长度等内容
(3)将一些索引信息存入index文件
消费者消费信息时,根据topic查询consumerqueue文件,找到对应的topic,开始读取消息,此时读取到的数据是消息的起始偏移量和消息长度,根据消息的起始偏移量从commitlog中查找对应的偏移量位置,然后根据消息长度取commitlog中的数据,即取到了指定的消息内容。
如果消费者获取消息使用了tag标签,会使用index文件,获取消息内容方式与上面类似。
具体流程如下图所示:
(二) 文件存储对象间流程
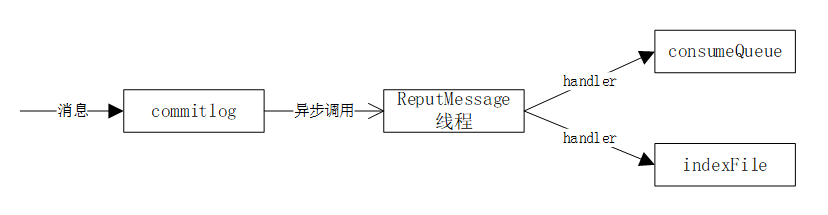
RocketMQ使用Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
此处有一个关键参数:reputFromOffset
消息允许重复:reputFromOffset
= commitlog的提交指针
消息不允许重复:reputFromOffset
= commitlog中内存的最大偏移量
commitDispacherBuildConsumeQueue(handler):构建消息消费队列
1、 根据消息主题和消息ID获取消息消费队列ConsumeQueue
2、 依次将消息的偏移量、消息长度、taghash写入ByteBufff,然后根据ConsumeQueueOffset计算出ConsumeQueue的物理地址,将内容追加到内存映射文件中
commitDispacherBuildIndex(handler):构建索引文件
这里有个配置项:messageIndexEnable,如果位true,则会构建索引文件
1、 创建或获取indexFile的最大物理偏移量,如果该消息的物理偏移量小于索引文件的物理偏移量,说明是重复消息,则忽略本次构建
2、 如果索引唯一键不为空,则添加到hash索引中
3、 构建索引列
(三)文件存储流程(以commitlog为例)
对于文件的存储,以commitlog为例,当一次写动作完成时,提交指针(commitedPosition)和写指针(wrotePosition)位置一致,当新的消息到来时,写指针会向后移动,如果发生commit动作时,会将写指针和提交指针之间的内容提交到堆外缓存中(MapprByteBuffer)。
堆外缓存有提交指针(commitPosition)、写指针(wrotePosition)和刷盘指针(flushPosition);当一次提交后,提交指针和写指针是在同一位置,当一次刷盘操作完成时,刷盘指针和提交指针在同一位置。以三个指针都在同一位置为例,当消息被提交到堆外缓存时,堆外缓存的写指针向后移动;当到达需要提交时,提交之后,提交指针和写指针在同一位置;当需要刷盘时,将提交指针与刷盘指针之间的内容,写入磁盘(此使写指针一直在写,一直在向后移动),因此,通常情况下,写指针的位置在最前,刷盘指针的位置在最后。
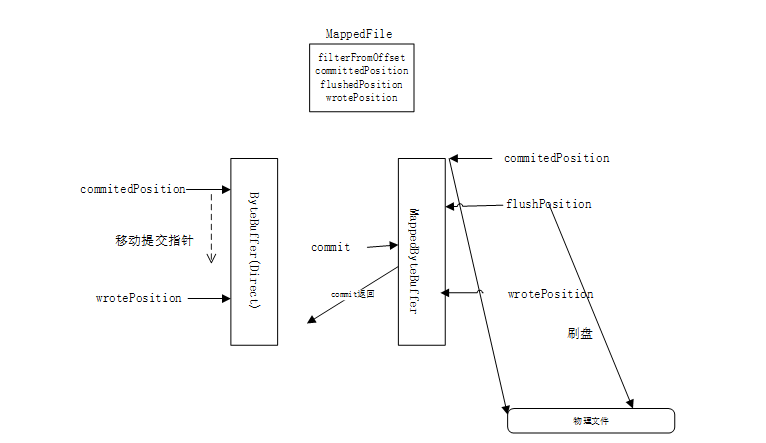
对于刷盘,有同步刷盘和异步刷盘两种方式,在源码中,存在一个参 transientStorePoolEable ,是否开启堆外内存,如果开启,则是异步刷盘,否则,则是同步刷盘。
流程:
同步刷盘:内存映射文件直接写入磁盘
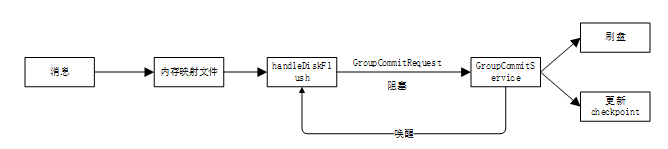
这里需要特殊说一个机制:为了避免同步刷盘消费任务与其他消息生产者提交的任务直接产生竞争锁,因此GroupCommitService提供了写容器和读容器,每次刷盘完毕后,两者会做身份交换。因此后面说到consumerqueue中默认有4个队列,实际上一读一写,默认是8个队列。
异步刷盘:内存映射文件写入堆外内存后异步刷盘

Commitlog存储消息流程:
1、 消息写入,写指针往后移动
2、 异步提交commit(commitRealTimeService)
(1)异步Commit的条件(commitRealTimeService):
commit条件主要有三个维度:
a、执行间隔时间
b、最小提交页数
c、两次执行最大实际间隔
执行条件:
a、 到执行时间(每200ms执行一次),如果提交页数大于最小提交页数,则提交
b、距上次提交时间间隔超过了两次执行的最大执行间隔
(2)Commit流程
a、校验broker状态、角色、消息大小
b、延迟队列的特殊处理
c、获取当前可以写入的commitlog文件
d、获取putMessageLock,准备写入(由此可见,写入时串行写入)
e、设置消息的存储时间(如果没有文件,则创建一个新文件)
f、 将消息加载到MappedFile中
g、创建全局唯一的消息ID
h、获取消息在队列的偏移量计算消息
i、机选消息总长度
j、如果消息总长度+8>commitlog的空闲长度,则新建一个commitlog文件(8个长度表示文件剩余长度+魔数)
k、将消息存到buff中(内存映射文件)
l、更新消息队列偏移量
m、释放putMessageLock
3、内存映射更新写指针位置
4、 移动提交指针到上次提交时的写指针
5、 异步flush(FlushRealTimeService)
(1)异步执行条件
可执行维度:
a、等待方式(await/sleep)
b、线程运行的时间间隔
c、一次刷写最小页数
d、两次执行的最大间隔(10s)
可译性条件与异步提交commit一致
(2)执行步骤
a、异步commit执行成功,唤醒刷盘线程,flushRealTimeService
b、执行条件通过,提交线程
c、刷盘完成,更新checkpoint中刷盘时间点(将内存中数据写入磁盘(FileChannel中的force),更新checkpoint中commitlog文件刷盘时间戳)
说明:checkpoint中commitlog文件刷盘时间戳刷盘在更新消息消费队列时触发。
四、文件恢复
(一)consumeQueue和Index恢复
1、判断上次退出是否时异常,如果时异常退出
2、加载延迟队列
3、判断commitlog文件大小是否与配置文件大小一致,如果不一致,删除commitlog文件,创建MappedFile对象
4、加载消息消费队列,构建consumeQueue对象
5、加载checkpoint
6、加载索引文件
如果上次异常退出且索引文件的上次刷盘时间小于索引文件的最大的消息时间戳,则立即销毁该文件
7、执行恢复策略
8、consumeQueue恢复后,在commitlog存储消息的逻辑偏移量
(二)正常退出文件恢复
1、从倒数第三个文件开始恢复,如果不足三个文件,则从第一个文件开始恢复
2、校验消息。
mappedFileOffset:校验通过的偏移量
processOffset:文件已确认的偏移量
(1)消息查找校验为true,且消息大小大于0,说明是正常消息存储,继续校验下一个消息
(2)消息查找校验为true,消息大小为0,说明是到了文件尾部,继续下一个文件
(3)消息查找校验为false,说明该文件未填满,结束循环处理(此处即为消息的偏移量)
3、更新MappedFileQueue中的刷盘指针和提交指针到offset
4、删除offset之后的所有文件
(1)offset > 文件尾部offse,说明是正常文件,忽略
(2)文件头部offset < offset < 文件尾部offset,说明offset在该文件偏移量内,设置MappedFile的commitPosition和flushPosition
(3)offset < 文件头部offset,说明是在有效文件之后创建的,删除(清理MappedFile占用的资源,删除物理文件)
(三)异常退出文件恢复
异常退出恢复的流程和正常退出文件恢复的流程基本一致,有两点差异:
1、 文件读取顺序
正常恢复:从倒数第三个文件开始,向后遍历
异常恢复:从最后一个开始,向前遍历到第一个正确存储的文件
2、 空文件夹处理
正常:无需处理
异常恢复:如果commitlog文件夹是空的,则删除消息消费队列下的所有文件
判断是否是正确文件:
1、 魔数判断
2、 文件的第一条消息长度为0,说明未存储消息
3、 对比文件第一条消息的offset,与checkpoint中(commitlog/consumeQueue/index)的刷盘时间对比
第一条消息offset < checkpoint中刷盘时间,说明是正确文件
4、 验证合法性,转发到MappedFile
5、 如果未找到MappedFile,重置commitPosition和flushPosition,销毁消息消费队列文件
五、文件删除
(一)触发条件(任意满足一条即可触发):
1、 每天凌晨执行定时任务(4点)
2、 磁盘不足
频率:每10ms查询一次磁盘是否充足,不充足,则调用文件删除
磁盘不足维度:
(1)文件所在磁盘的最大使用量
(2)磁盘使用率
(3)磁盘使用率阈值
(4)磁盘使用率预警值
磁盘不足条件:
(1)磁盘使用率大于预警阈值,建议立即清除文件
(2)磁盘使用率大于磁盘使用率阈值
3、 手动触发(未封装)
(二)判断删除哪些文件
触发后是否要删除文件,需要满足以下条件的文件才会被删除:
1、文件保存时间
2、删除物理文件时间间隔
3、距第一次删除被拒绝可保留时间
(三)删除过程:
从倒数第二个文件开始
1、 删除MappedFile所占用的资源
2、 删除MappedFile对应的文件
深入理解RocketMQ(四)--消息存储的更多相关文章
- 深入理解RocketMQ的消费者组、队列、Broker,Topic
1.遇到的问题:上测试环境,上次描述的鸟问题又出现了,就是生产者发3条数据,我这边只能收到1条数据. 2.问题解决: (1)去控制台看我的消费者启动情况,貌似没什么问题 , (2)去测试服务器里看日志 ...
- Java反射理解(四)-- 获取成员变量构造函数信息
Java反射理解(四)-- 获取成员变量构造函数信息 步骤 获取成员变量信息: obj.getClass() 获取类类型对象 成员变量也是对象,java.lang.reflect.Field 类中封装 ...
- java基础基础总结----- 数组深入理解(四)
一.数组的基本概念 数组可以看成是多个相同类型数据组合,对这些数据的统一管理. 数组变量属引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象的成员变量. 数组的元素可以是任何数据类型,包括基 ...
- 深入理解RocketMQ(一)---阅读源码准备
本文主要描述使用Idea获取rocketMQ源码及源码的读取. 在演示搭建源码环境前,先简要描述一下RocketMQ的设计目标. 1.架构模式 和大多数消息中间件一样,采用的是发布订阅模式,基本组件包 ...
- 深入理解JVM(四) -- 垃圾内存回收的判定方法和内容
上一篇文章我们学到了对象在内存中是如何存储的已经是如何被访问的,这篇文章将介绍当内存空间不够时,虚拟机将怎样判定对象可不可以被回收已经哪些地方会发生回收. 垃圾回收主要(不是全部)发生在堆内存中,当一 ...
- 深入理解C语言-深入理解内存四区
数组与指针 当数组做函数参数的时候,会退化为一个指针 此时在函数内是得不到数组大小的 因此,数组做函数参数的时候需要传递数组大小,也就是多传递一个参数 void func(int arr[], int ...
- 正确理解这四个重要且容易混乱的知识点:异步,同步,阻塞,非阻塞,5种IO模型
本文讨论的背景是Linux环境下的network IO,同步IO和异步IO,阻塞IO和非阻塞IO分别是什么 概念说明 在进行解释之前,首先要说明几个概念: - 用户空间和内核空间 - 进程切换 - 进 ...
- jvm入门及理解(四)——运行时数据区(堆+方法区)
一.堆 定义: Heap,通过new关键字创建的对象,都存放在堆内存中. 特点 线程共享,堆中的对象都存在线程安全的问题 垃圾回收,垃圾回收机制重点区域. jvm内存的划分: JVM内存划分为堆内存和 ...
- 深入理解RocketMQ(九)---实战(控制台搭建)
rocketMQ控制台搭建 (1)下载rocketmq-console代码:https://github.com/875279177/incubator-rocketmq-externals (2)修 ...
随机推荐
- Chisel3 - util - ReadyValid
https://mp.weixin.qq.com/s/g7Q9ChxHbAQGkbMmOymh-g ReadyValid通信接口.通信的双方为数据的生产者(Producer)和消费者(Consum ...
- 从0开始探究vue-公共变量的管理
背景 在Vue项目中,我们总会遇到一些公共数据的处理,如方法拦截,全局变量等,本文旨在解决这些问题 解决方案 事件总线 所谓事件总线,就是在当前的Vue实例之外,再创建一个Vue实例来专门进行变量传递 ...
- ASP.NET中AJAX的异步加载(Demo演示)
此次的Demo是一个页面,页面上有两行字,然后后面用AJAX,使用一个下拉框去替换第一行文字 第一个是被替换的网页 <!DOCTYPE html> <html> <hea ...
- Java实现 LeetCode 451 根据字符出现频率排序
451. 根据字符出现频率排序 给定一个字符串,请将字符串里的字符按照出现的频率降序排列. 示例 1: 输入: "tree" 输出: "eert" 解释: 'e ...
- Java实现 LeetCode 395 至少有K个重复字符的最长子串
395. 至少有K个重复字符的最长子串 找到给定字符串(由小写字符组成)中的最长子串 T , 要求 T 中的每一字符出现次数都不少于 k .输出 T 的长度. 示例 1: 输入: s = " ...
- Java实现 LeetCode 350 两个数组的交集 II(二)
350. 两个数组的交集 II 给定两个数组,编写一个函数来计算它们的交集. 示例 1: 输入: nums1 = [1,2,2,1], nums2 = [2,2] 输出: [2,2] 示例 2: 输入 ...
- java实现平面4点最小距离
已知平面上若干个点的坐标. 需要求出在所有的组合中,4个点间平均距离的最小值(四舍五入,保留2位小数). 比如有4个点:a,b,c,d, 则平均距离是指:ab, ac, ad, bc, bd, cd ...
- Java实现第九届蓝桥杯测试次数
测试次数 题目描述 x星球的居民脾气不太好,但好在他们生气的时候唯一的异常举动是:摔手机. 各大厂商也就纷纷推出各种耐摔型手机.x星球的质监局规定了手机必须经过耐摔测试,并且评定出一个耐摔指数来,之后 ...
- java实现第六届蓝桥杯灾后重建
灾后重建 题目描述 Pear市一共有N(<=50000)个居民点,居民点之间有M(<=200000)条双向道路相连.这些居民点两两之间都可以通过双向道路到达.这种情况一直持续到最近,一次严 ...
- (十一)DVWA全等级SQL Injection(Blind)盲注--手工测试过程解析
一.DVWA-SQL Injection(Blind)测试分析 SQL盲注 VS 普通SQL注入: 普通SQL注入 SQL盲注 1.执行SQL注入攻击时,服务器会响应来自数据库服务器的错误信息,信息提 ...