Spark学习笔记(三)-Spark Streaming
Spark Streaming支持实时数据流的可扩展(scalable)、高吞吐(high-throughput)、容错(fault-tolerant)的流处理(stream processing)。

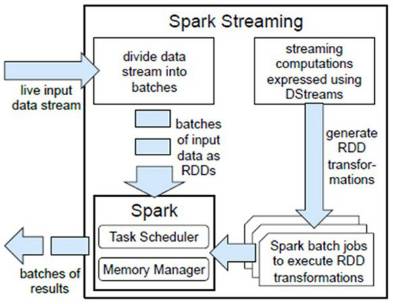
架构图
特性如下:
可线性伸缩至超过数百个节点;
实现亚秒级延迟处理;
可与Spark批处理和交互式处理无缝集成;
提供简单的API实现复杂算法;
更多的流方式支持,包括Kafka、Flume、Kinesis、Twitter、ZeroMQ等。
原理
Spark在接收到实时输入数据流后,将数据划分成批次(divides the data into batches),然后转给Spark Engine处理,按批次生成最后的结果流(generate the final stream of results in batches)。

API
DStream
DStream(Discretized Stream,离散流)是Spark Stream提供的高级抽象连续数据流。
组成:一个DStream可看作一个RDDs序列。
核心思想:将计算作为一系列较小时间间隔的、状态无关的、确定批次的任务,每个时间间隔内接收的输入数据被可靠存储在集群中,作为一个输入数据集。
特性:一个高层次的函数式编程API、强一致性以及高校的故障恢复。
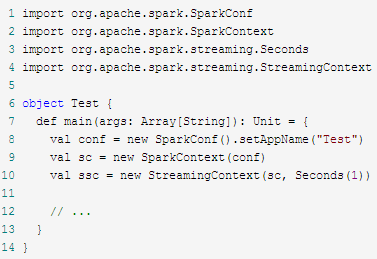
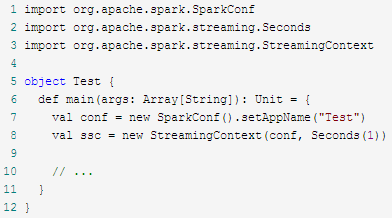
应用程序模板:
模板1
模板2
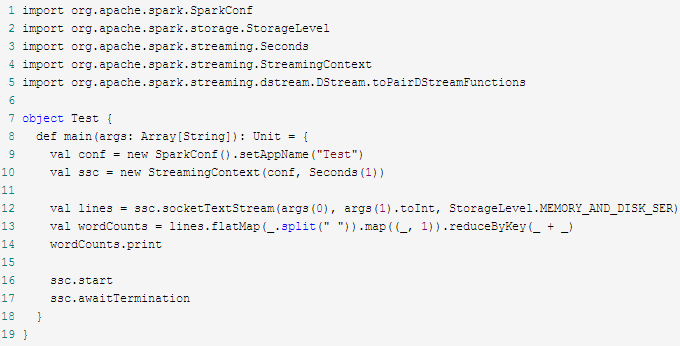
WordCount示例
Input DStream
Input DStream是一种从流式数据源获取原始数据流的DStream,分为基本输入源(文件系统、Socket、Akka Actor、自定义数据源)和高级输入源(Kafka、Flume等)。
- Receiver:
每个Input DStream(文件流除外)都会对应一个单一的Receiver对象,负责从数据源接收数据并存入Spark内存进行处理。应用程序中可创建多个Input DStream并行接收多个数据流。
每个Receiver是一个长期运行在Worker或者Executor上的Task,所以会占用该应用程序的一个核(core)。如果分配给Spark Streaming应用程序的核数小于或等于Input DStream个数(即Receiver个数),则只能接收数据,却没有能力全部处理(文件流除外,因为无需Receiver)。
Spark Streaming已封装各种数据源,需要时参考官方文档。
Transformation Operation
常用Transformation
* map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的DStream;
* flatMap(func):与map相似,但是每个输入项可用被映射为0个或者多个输出项;
* filter(func):返回一个新的DStream,仅包含源DStream中满足函数func的项;
* repartition(numPartitions):通过创建更多或者更少的分区改变DStream的并行程度;
* union(otherStream):返回一个新的DStream,包含源DStream和其他DStream的元素;
* count():统计源DStream中每个RDD的元素数量;
* reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream;
* countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数;
* reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来;
* join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新DStream;
* cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组;
* transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作。
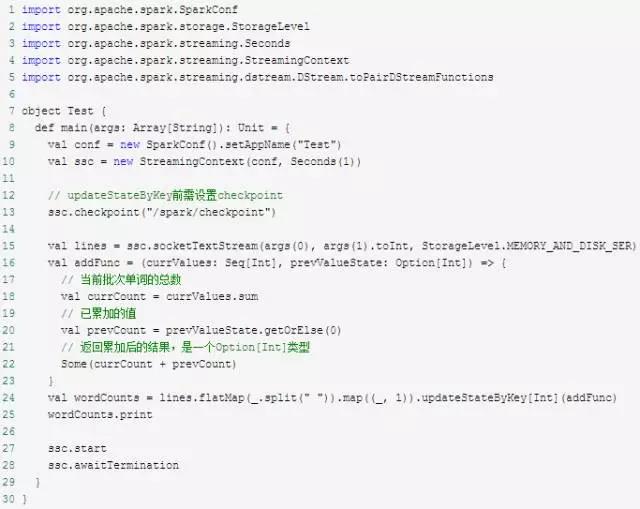
updateStateByKey(func)
updateStateByKey可对DStream中的数据按key做reduce,然后对各批次数据累加
WordCount的updateStateByKey版本
transform(func)
通过对原DStream的每个RDD应用转换函数,创建一个新的DStream。
官方文档代码举例

Window operations
窗口操作:基于window对数据transformation(个人认为与Storm的tick相似,但功能更强大)。
参数:窗口长度(window length)和滑动时间间隔(slide interval)必须是源DStream批次间隔的倍数。
举例说明:窗口长度为3,滑动时间间隔为2;上一行是原始DStream,下一行是窗口化的DStream。
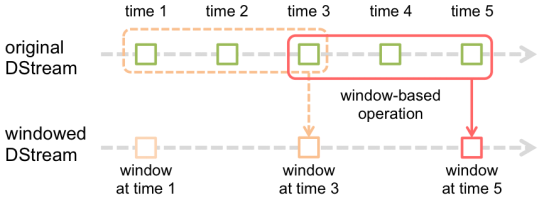
常见window operation
有状态转换包括基于滑动窗口的转换和追踪状态变化(updateStateByKey)的转换。
基于滑动窗口的转换
* window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的DStream;
* countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数;
* reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
* reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数;
* reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
* countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
官方文档代码举例

join(otherStream, [numTasks])
连接数据流
官方文档代码举例1

官方文档代码举例2

Output Operation

缓存与持久化
通过persist()将DStream中每个RDD存储在内存。
Window operations会自动持久化在内存,无需显示调用persist()。
通过网络接收的数据流(如Kafka、Flume、Socket、ZeroMQ、RocketMQ等)执行persist()时,默认在两个节点上持久化序列化后的数据,实现容错。
Checkpoint
用途:Spark基于容错存储系统(如HDFS、S3)进行故障恢复。
分类:
元数据检查点:保存流式计算信息用于Driver运行节点的故障恢复,包括创建应用程序的配置、应用程序定义的DStream operations、已入队但未完成的批次。
数据检查点:保存生成的RDD。由于stateful transformation需要合并多个批次的数据,即生成的RDD依赖于前几个批次RDD的数据(dependency chain),为缩短dependency chain从而减少故障恢复时间,需将中间RDD定期保存至可靠存储(如HDFS)。
使用时机:
Stateful transformation:updateStateByKey()以及window operations。
需要Driver故障恢复的应用程序。
使用方法
Stateful transformation
streamingContext.checkpoint(checkpointDirectory)
需要Driver故障恢复的应用程序(以WordCount举例):如果checkpoint目录存在,则根据checkpoint数据创建新StreamingContext;否则(如首次运行)新建StreamingContext。
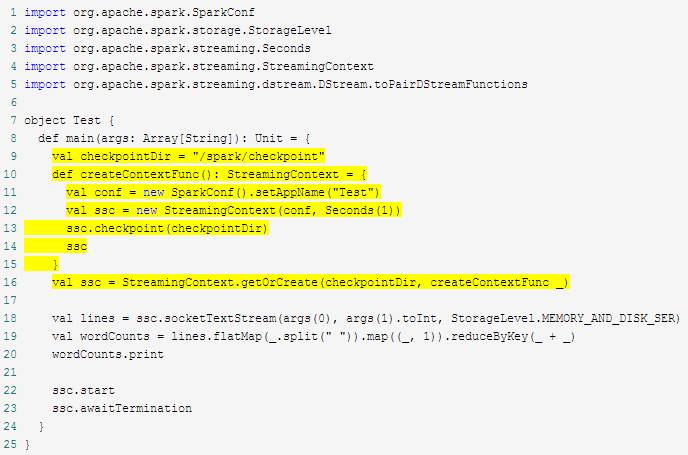
checkpoint时间间隔
方法:
dstream.checkpoint(checkpointInterval)
原则:一般设置为滑动时间间隔的5-10倍。
分析:checkpoint会增加存储开销、增加批次处理时间。当批次间隔较小(如1秒)时,checkpoint可能会减小operation吞吐量;反之,checkpoint时间间隔较大会导致lineage和task数量增长。
性能调优
降低批次处理时间
数据接收并行度
增加DStream:接收网络数据(如Kafka、Flume、Socket等)时会对数据反序列化再存储在Spark,由于一个DStream只有Receiver对象,如果成为瓶颈可考虑增加DStream。

设置“spark.streaming.blockInterval”参数:接收的数据被存储在Spark内存前,会被合并成block,而block数量决定了Task数量;举例,当批次时间间隔为2秒且block时间间隔为200毫秒时,Task数量约为10;如果Task数量过低,则浪费了CPU资源;推荐的最小block时间间隔为50毫秒。
显式对Input DStream重新分区:在进行更深层次处理前,先对输入数据重新分区。
inputStream.repartition(<number of partitions>)
数据处理并行度:reduceByKey、reduceByKeyAndWindow等operation可通过设置“spark.default.parallelism”参数或显式设置并行度方法参数控制。
数据序列化:可配置更高效的Kryo序列化。
设置合理批次时间间隔
原则:处理数据的速度应大于或等于数据输入的速度,即批次处理时间大于或等于批次时间间隔。
方法:
先设置批次时间间隔为5-10秒以降低数据输入速度;
再通过查看log4j日志中的“Total delay”,逐步调整批次时间间隔,保证“Total delay”小于批次时间间隔。
内存调优
持久化级别:开启压缩,设置参数“spark.rdd.compress”。
GC策略:在Driver和Executor上开启CMS。
Spark学习笔记(三)-Spark Streaming的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记-三种属性配置详细说明【转】
相关资料:Spark属性配置 http://www.cnblogs.com/chengxin1982/p/4023111.html 本文出处:转载自过往记忆(http://www.iteblog.c ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
- Spark学习笔记之-Spark远程调试
Spark远程调试 本例子介绍简单介绍spark一种远程调试方法,使用的IDE是IntelliJ IDEA. 1.了解jvm一些参数属性 -X ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
随机推荐
- 16 . PythonWeb框架之Django
Web框架简介 Web开发是Python语言应用领域的重要部分,也是目前最主要的Web开发语言之一,在其二十多年的历史中出现了数十种Web框架,比如Django.Tornado.Flask.Twist ...
- 【已解决】Ubuntu U盘启动出现“Failed to load ldlinux.c32”问题
利用UltraISO制作了Ubuntu的U盘启动,在USB启动时出现了 Failed to load ldlinux.c32 Boot failed: please change disks and ...
- Rocket - util - IDPool
https://mp.weixin.qq.com/s/Pe7FGKzfRufzzYDrl0fQ7g 介绍IDPool的实现. 1. 基本介绍 实现从ID池中分配和释放ID的功能. ...
- undefined attribute name (XXXX)
Window --> Preferences --> Web --> HTML Files --> Editor --> Validation --> Attrib ...
- ASP.NET生成验证码
首先,添加一个一般处理程序 注释很详细了,有不懂的欢迎评论 using System; using System.Collections.Generic; using System.Drawing; ...
- Java 第十一届 蓝桥杯 省模拟赛 递增序列
问题描述 在数列 a[1], a[2], -, a[n] 中,如果 a[i] < a[i+1] < a[i+2] < - < a[j],则称 a[i] 至 a[j] 为一段递增 ...
- Java实现 LeetCode 700 二叉搜索树中的搜索(遍历树)
700. 二叉搜索树中的搜索 给定二叉搜索树(BST)的根节点和一个值. 你需要在BST中找到节点值等于给定值的节点. 返回以该节点为根的子树. 如果节点不存在,则返回 NULL. 例如, 给定二叉搜 ...
- Java实现 LeetCode 350 两个数组的交集 II(二)
350. 两个数组的交集 II 给定两个数组,编写一个函数来计算它们的交集. 示例 1: 输入: nums1 = [1,2,2,1], nums2 = [2,2] 输出: [2,2] 示例 2: 输入 ...
- Java实现 蓝桥杯VIP 算法提高 交换Easy
算法提高 交换Easy 时间限制:1.0s 内存限制:512.0MB 问题描述 给定N个整数组成的序列,每次交换当前第x个与第y个整数,要求输出最终的序列. 输入格式 第一行为序列的大小N(1< ...
- java实现第二届蓝桥杯地铁换乘(C++)
地铁换乘. 为解决交通难题,某城市修建了若干条交错的地铁线路,线路名及其所属站名如stations.txt所示. 线1 苹果园 .... 四惠东 线2 西直门 车公庄 .... 建国门 线4 .... ...