java读源码 之 map源码分析(HashMap)二
在上篇文章中,我已经向大家介绍了HashMap的一些基础结构,相信看过文章的同学们,应该对其有一个大致了了解了,这篇文章我们继续探究它的一些内部机制,包括构造函数,字段等等~

字段分析:
// 默认容量16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量2的31次方
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表中元素超过8就进行树化
static final int TREEIFY_THRESHOLD = 8;
// 在哈希表扩容时,如果发现链表长度小于 6,则会由树重新退化为链表。
static final int UNTREEIFY_THRESHOLD = 6;
//在转变成树之前,还会有一次判断,只有键值对数量大于 64 才会发生转换。这是为了避免在哈希表建立初期,多个键 //值对恰好被放入了同一个链表中而导致不必要的转化。
static final int MIN_TREEIFY_CAPACITY = 64;
构造函数分析:
/**
* 用指定的初始容量跟负载因子构造一个空的HashMap
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
构造函数中调用了一个tableSizeFor方法,我们跟踪这个方法可以发现:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
有没有一种很眼熟的感觉?这个算法我们之前在ArrayDeque已经分析过啦,其实就是求一个比cap大的最小的2的n次方的数(在这个方法里,进行了减1,就是要找一个大于等于当前数的2的n次方的数),具体的分析大家可以看看这篇文章:https://blog.csdn.net/qq_41907991/article/details/94724829
// 构造一个指定初始容量的HashMap,采用的是默认的负载因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 容量跟负载因子均采用默认的值,初始容量为16,负载因子为0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 构建一个新的HashMap,用于保存原有map中的映射
// 在构建时会采用默认的负载因子0.75,同时会计算一个初始容量来保存这些映射
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
// 将集合中元素放入到新构建的map中
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
// 可以看到,不能放入一个null的map
int s = m.size();
if (s > 0) {
// 如果当前的HashMap还没经过初始化的话,现进行一次初始化
if (table == null) {
// 计算当前map需要的最小的容量=元素数量/负载因子,加1方便强转
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 如果容器中元素的数量已经大于了阈值,进行一次容量的初始化
if (t > threshold)
threshold = tableSizeFor(t);
}
// 如果当前的hashMap已经经过的初始化,判断元素数量是否大于阈值
else if (s > threshold)
// 进行一次扩容
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
// 循环添加
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
构造函数就到这里啦~,接下来就要进入我们今天的重头戏,hashMap的扩容机制:
扩容机制:
final Node<K,V>[] resize() {
// 旧容器底层数组
Node<K,V>[] oldTab = table;
// 旧容器容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧容器的阈值
int oldThr = threshold;
int newCap, newThr = 0;
// oldCap > 0说明容器已经经过了初始化
if (oldCap > 0) {
// 扩容前进行判断,如果oldCap>2的31次方
if (oldCap >= MAXIMUM_CAPACITY) {
// 直接将阈值设置为Integer.MAX_VALUE
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 这里可以看出容量每次被扩容为2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 阈值也变为原来2倍
newThr = oldThr << 1;
}
else if (oldThr > 0)
// 当我们调用HashMap(Map<? extends K, ? extends V> m)这个构造函数时,就会进入这个判断
newCap = oldThr;
else {
// oldCap=0 oldThr=0,说明还没经过初始化,直接给默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 还没有对新的阈值进行计算
if (newThr == 0) {
// 计算公式容量*负载因子
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 根据计算出来的容量创建一个对应长度的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 将这个数组赋值给我们的容器
table = newTab;
if (oldTab != null) {
// 原容器的数组不为null,说明曾经放入过元素
for (int j = 0; j < oldCap; ++j) {
// 遍历其中每一个节点
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 将原数组中的引用置为null,方便垃圾回收
oldTab[j] = null;
if (e.next == null)
// 根据key得到hash值跟新容器容量进行模运算,并将这个位置上的元素置为e
// 在arrayDeque的文章中已经详细分析过原理了
newTab[e.hash & (newCap - 1)] = e;
// TreeNode的相关东西我们还是单独做一章进行分析
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 说明在当前数组位置上,下挂了一个链表
// 需要将这个链表进行移动
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// e.hash & oldCap 很关键的一个判断
// 主要用来判断链表下挂的节点是否发生改变
// 后文会对这个判断进行详细分析
if ((e.hash & oldCap) == 0) {
// 解决jdk循环链表跟rehash后链表顺序颠倒的问题
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
到这里,我们已经对resize有了一个大致的了解,但是现在最大的问题就是上面这段代码最好那个循环了,它到底是干什么的?我们好不容易搞懂了e.hash & (newCap - 1)是一个模运算,现在这个(e.hash & oldCap) == 0又是什么鬼?不要急,跟着我一步步分析,包懂~~~~,要说清楚这个问题,我们需要将其与jdk7进行比较
jdk7中扩容导致的问题分析:
参考链接:https://www.jianshu.com/p/619a8efcf589
具体的源码我就不分析,相对于jdk8而言,代码还是很好理解的,这里主要说一下过程,以及它导致的死循环问题:(请注意,以下为jdk7的流程,不是jdk8,不要搞混了哦)
// jdk7中的resize方法
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
// 创建一个新的 Hash Table
Entry[] newTable = new Entry[newCapacity];
// 将 Old Hash Table 上的数据迁移到 New Hash Table 上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
// 迁移链表的方法
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
假设我们的 hash 算法就是简单的用 key mod 一下表的大小(也就是数组的长度)
最上面的是 old hash 表,其中的 Hash 表的 size = 2,所以 key = 3, 7, 5,在 mod 2 以后都冲突在 table[1] 这里了
接下来的三个步骤是 Hash 表 resize 成 4,然后所有的 <key, value> 重新 rehash 的过程
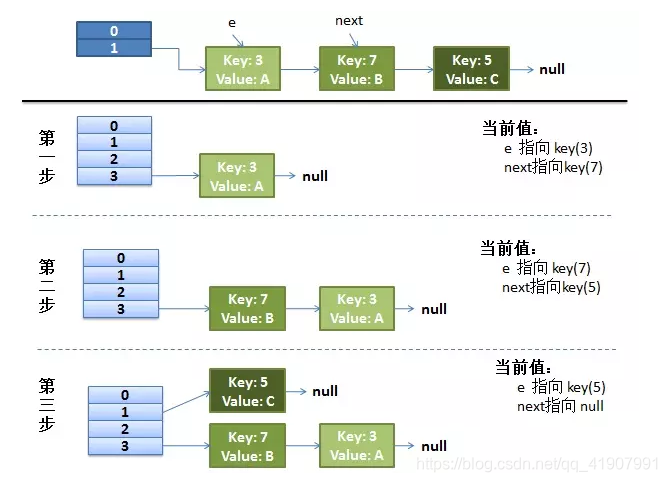
并发下的Rehash:
1)假设有两个线程
do {
Entry<K,V> next = e.next; // 假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
而线程二执行完成了。于是有下面的这个样子
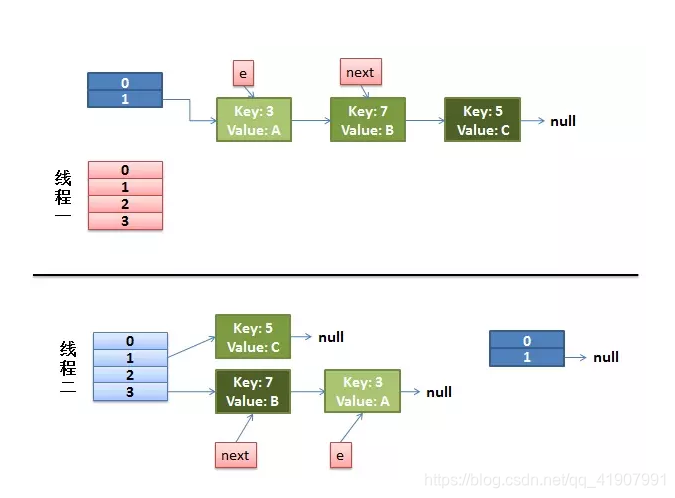
注意,线程二执行完成之后,key(7)已经指向了Key(3)
2)线程一被调度回来执行
- 先是执行 newTalbe[i] = e;
- 然后是 e = next,导致了 e 指向了 key(7)
- 而下一次循环的 next = e.next 导致了 next 指向了 key(3)
3)线程一接着工作。把 key(7) 摘下来,放到 newTable[i] 的第一个,然后把 e 和 next 往下移
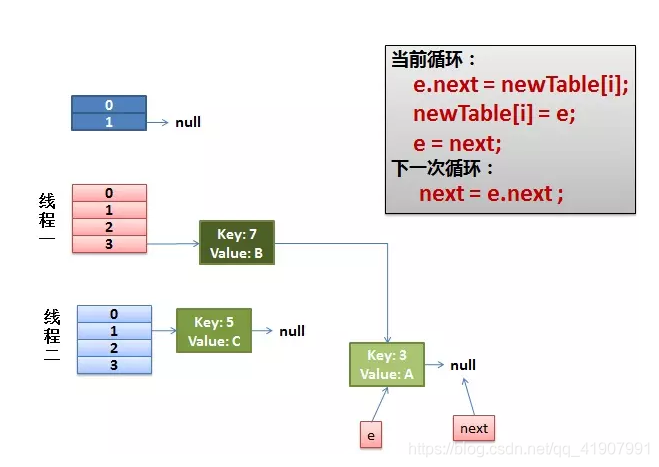
4)环形链接出现
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
此时的 key(7).next 已经指向了 key(3), 环形链表就这样出现了

在对jdk中hashmap存在的问题分析了之后,我们来看看jdk8是怎么解决的。
jdk8的改进方案:
我们先解答之前留下来的一个疑惑,if ((e.hash & oldCap) == 0),oldCap一定是2的n次方,用二进制表示可以是下面这个样子
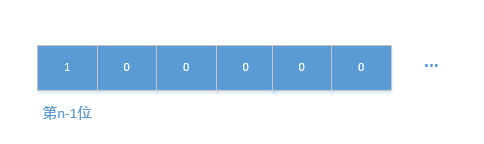
看到这种数,并且在进行与运算,我们就要知道,它其实就是为了确定e.hash的第n-1位上的到底是0还是1。
那么现在问题就成了,如果key的hash值对应的二进制第n-1位为0又意味着什么呢?为1又意味着什么呢?
我们分两种情况分析:
- key的hash值对应的二进制第n-1位为0
当我们确定了其n-1位为0的时候,这个时候,key.hash & 2的n次方一定等于key.hash & 2的n+1次方(也就是我们扩容后的容量),图解如下:
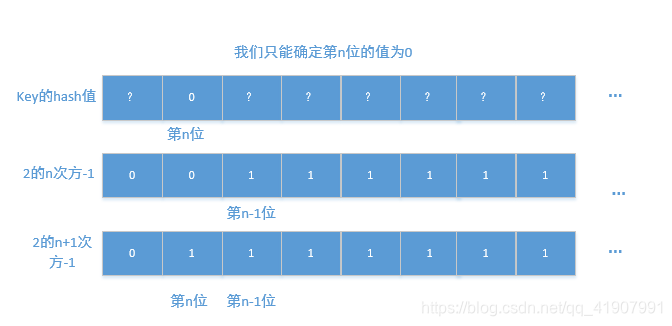
我们可以看到,当我们进行key.hash&(容量-1)的时候,因为新旧容量对应二进制数唯一的区别就是最高位上一个为0,一个为1,而当我们确定key的hash值在这个位置上的值为0后,就可以忽略这个差异性,因为0与1=0与0=0
这个时候说明了这个这个key在数组中的位置不需要被移动,还是在原来的角标位置上
- key的hash值对应的二进制第n-1位为1
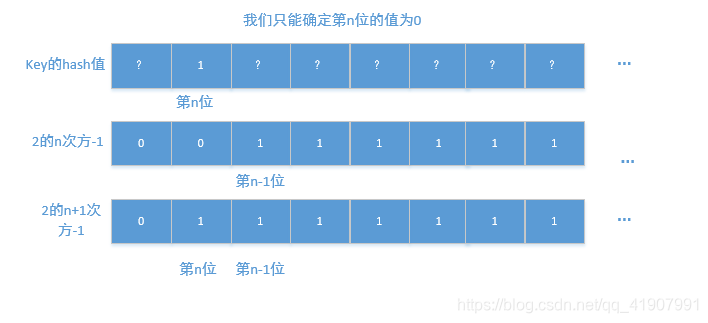
从图中可以很明显的看出来,key.hash & 2的n次方-1 跟 key.hash & 2的n+1次方-1,这两个结果相差什么呢?相差一个2的n次方嘛~,也就是oldCap。分析完了不得不感叹一句,真他娘的巧妙!
OK,解决了我们遗留的一个问题后,继续分析为什么jdk8能解决添加元素的时候的死循环问题,回到之前的代码:
// 位置为发生改变的节点对应链表的头尾节点
Node<K,V> loHead = null, loTail = null;
// 位置发生改变的节点对应链表的头尾节点
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 说明位置没有发生改变
if ((e.hash & oldCap) == 0) {
// 说明是第一次进行这个判断
if (loTail == null)
// 将头节点置为e
loHead = e;
else
// 否则将当前链表的最后一个节点指向e
loTail.next = e;
// loTail始终为加入的最后一个元素
loTail = e;
}
else {
// 说明位置发生了改变
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
// 说明有元素的位置没发生改变
loTail.next = null;
// 新数组原位置上的元素置为这个链表的头节点
newTab[j] = loHead;
}
if (hiTail != null) {
// 说明有元素的位置发生了改变
hiTail.next = null;
// 改变的位置为原位置+oldCap
newTab[j + oldCap] = hiHead;
}
可以看出,相比于jdk7,jdk8在移动元素时不会该变其顺序,而是保持原来的顺序,这样就解决了jdk7中的死循环问题
到这里,扩容机制我们就介绍完啦希望你能从中学习到知识哦~~,预计HashMap还有两篇文章
码字不易,喜欢的朋友加个关注,点个赞吧~

java读源码 之 map源码分析(HashMap)二的更多相关文章
- java:Map借口及其子类HashMap二
java:Map借口及其子类HashMap二 重点:所有的集合必须依赖Iterator输出 Map<String, Integer> map = new HashMap<String ...
- Java 数据类型:集合接口Map:HashTable;HashMap;IdentityHashMap;LinkedHashMap;Properties类读取配置文件;SortedMap接口和TreeMap实现类:【线程安全的ConcurrentHashMap】
Map集合java.util.Map Map用于保存具有映射关系的数据,因此Map集合里保存着两个值,一个是用于保存Map里的key,另外一组值用于保存Map里的value.key和value都可以是 ...
- java读源码 之 map源码分析(HashMap,图解)一
开篇之前,先说几句题外话,写博客也一年多了,一直没找到一种好的输出方式,博客质量其实也不高,很多时候都是赶着写出来的,最近也思考了很多,以后的博客也会更注重质量,同时也尽量写的不那么生硬,能让大家 ...
- Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析
Java 读写锁 ReentrantReadWriteLock 源码分析 转自:https://www.javadoop.com/post/reentrant-read-write-lock#toc5 ...
- Java读源码之ReentrantLock
前言 ReentrantLock 可重入锁,应该是除了 synchronized 关键字外用的最多的线程同步手段了,虽然JVM维护者疯狂优化 synchronized 使其已经拥有了很好的性能.但 R ...
- Java读源码之ReentrantLock(2)
前言 本文是 ReentrantLock 源码的第二篇,第一篇主要介绍了公平锁非公平锁正常的加锁解锁流程,虽然表达能力有限不知道有没有讲清楚,本着不太监的原则,本文填补下第一篇中挖的坑. Java读源 ...
- Java读源码之CountDownLatch
前言 相信大家都挺熟悉 CountDownLatch 的,顾名思义就是一个栅栏,其主要作用是多线程环境下,让多个线程在栅栏门口等待,所有线程到齐后,栅栏打开程序继续执行. 案例 用一个最简单的案例引出 ...
- 源码分析— java读写锁ReentrantReadWriteLock
前言 今天看Jraft的时候发现了很多地方都用到了读写锁,所以心血来潮想要分析以下读写锁是怎么实现的. 先上一个doc里面的例子: class CachedData { Object data; vo ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
随机推荐
- 选择IT行业的自我心得,希望能帮助到各位!(一)
我记得当时我还在读书的时候,也是卡在高三在后面,纠结我该怎么选择专业,一边顶着高考的压力又担心这担心那的,前怕狼后怕虎,一直犹犹豫豫,知道有一天我就听到谁谁谁的哥哥学IT老牛逼了,一个月多少多少钱,买 ...
- matlab计算相对功率
1.对脑电数据进行db4四层分解,因为脑电频率是在0-64HZ,分层后如图所示, 细节分量[d1 d2 d3 d4] 近似分量[a4] 重建细节分量和近似分量,然后计算对应频段得相对功率谱,重建出来得 ...
- C++基础的一些代码和笔记 stl乱炖
STL: 标准模板库.各种函数的模板和类的模板几个概念:容器:可容纳各种数据类型的通用数据结构,是类模板.迭代器:可用于依次存取容器中的元素,类似于指针,用iterator来进行对一个容器中单个元素的 ...
- L7过拟合欠拟合及其解决方案
1.涉及语句 import d2lzh1981 as d2l 数据1 : d2lzh1981 链接:https://pan.baidu.com/s/1LyaZ84Q4M75GLOO-ZPvPoA 提取 ...
- work of weekend 12/12/2015~12/14/2015
part 组员 周末工作+今日工作 工作耗时/h 明日计划 工作耗时/h backup 冯晓云 try the backup plan:brower:rewrite bi ...
- 学习JVM参数前必须了解的
JVM参数是什么 大家照相通常使用手机就够用了,但是针对发烧友来说会使用更专业的设备,比如单反相机,在单反里有好几个模式,P/A/S/M,其中P是傻瓜模式,程序会自动根据环境设置快门速度和光圈大小,以 ...
- S7通信协议之你不知道的事儿
在电气学习的路上,西门子PLC应该是我的启蒙PLC,从早期的S7-300/400 PLC搭建Profibus-DP网络开始接触,到后来的S7-200Smart PLC,再到现在的S7-1200/150 ...
- Java 基础讲解
Hello,老同学们,又见面啦,新同学们,你们好哦! 在看完本人的<数据结构与算法>专栏的博文的老同学,恭喜你们在学习本专栏时,你们将会发现好多知识点都讲解过,都易于理解,那么,没看过的同 ...
- Springboot:员工管理之登录、拦截器(十(4))
1:构建登录javaBean com\springboot\vo\LoginUser.java package com.springboot.vo; import lombok.Data; @Data ...
- 控制反转IOC,依赖注入DI理解
IOC:控制反转,常规下,高层依赖低层,项目是不稳定的.我们则应该把高层对低层的依赖去掉,换成对抽象的依赖,细节交给第三方来决定,这就是控制反转,反转的目的是为了降低依赖,增强扩展性. DI:依赖注入 ...