Innodb特性以及实现原理
1.insert buffer
2.double write
3.自适应哈希索引
4.异步io
5.邻接页刷新
1.insert buffer(change buffer)
作用:将非聚集索引上的DML操作从随机IO变成顺序IO,减少IO次数,提高效率
innodb使用insert buffer"欺骗"数据库:对于为非唯一索引,辅助索引的修改操作并非实时更新索引的叶子页,而是把若干对同一页面的更新缓存起来做合并为一次性更新操作,转化随机IO 为顺序IO,这样可以避免随机IO带来性能损耗,提高数据库的写性能。
insert buffer使用的条件:
- 索引是辅助索引
- 索引是非唯一索引(如果是唯一索引,每次变更都要判断索引的唯一性,又产生了离散读取,使insert buffer失去了意义)
具体查看
show engines inndo status 过滤
Ibuf: size 1, free list len 14316, seg size 14318(插入缓冲区的总大小 页的数量X16KB), 466174 merges(已经合并的meregs数量)
merged operations: insert 547399(插入记录被merge的次数), delete mark 42008(删除操作被merge的次数), delete 32055(更新操作被merge了多少次)
如果merges/merged的值等于3/1,则代表插入缓冲对于非聚集索引页的IO请求大约降低了3倍
change buffer
insert buffer的升级版,可以对DML都进行缓冲,insert ,delete,update,他们分别对应:insert buffer,delete buffer,purge buffer
对应参数
innodb_change_buffering:控制开启哪种buffer,可选值为:inserts,deletes,purgees,changes,all,none.
- all:默认值,缓存插入、标记删除和后台物理清理
- none:不缓存任何操作产生的数据
- inserts:缓存insert产生的数据
- deletes:缓存标记删除对辅助索引产生的变化
- changes:inserts和deletes的合并项
- purges:内部物理清除所产生的数据
innodb_change_buffer_max_size:控制change buffer最大使用内存数量,默认25(内存的1/4)
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 98, seg size 100, 0 merges
merged operations:具体每个操作的次数
insert 0, delete mark 0(delete buffer), delete 0 (purge buffer)
discarded operations:当change buffer 发生merge时,表已经呗删除,此时无需再将记录合并(merge)到辅助索引了
insert 0, delete mark 0, delete 0
insert buffer 的内部实现
insert buffer是一颗B+ 树,4.1版本后全局只有一个B+树,存放在ibdata1中
非叶子节点存放的是查询的search key.
一共9个字节:
- space:待插入记录所在表的表空间id,4个字节
- marker:兼容老版本insert buffer,1个字节
- offset:页所在的偏移量,4个字节
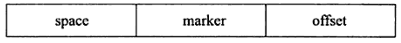
1.当插入一条数据,同时要更新辅助索引时,先在缓冲池中找要更新的索引所在的页,如果找到,直接更新索引,
不在,将操作缓冲到change buffer中>在下次进行操作这个数据页时,数据页读入内存,进行操作数据页(更新,插入)->写事务日志
merge insert buffer情况
- 辅助索引页被读入缓冲池
- insert buffer bitmap页追踪到该辅助索引页已经没有可用空间
- master thread调度机制
Master Thread的调度规则
a 主动merger[innodb主线程定期完成,用户线程无感知]
主动merger:
原理:主动merge通过innodb主线程(svr_master_thread)判断:若过去1s之内发生的I/O小于系统I/O能力的5%,
则主动进行一次insert buffer的meger操作。meger的页面数为系统I/O能力的5%,读取采用async io模式。
每10s,必定触发一次insert buffer meger操作。meger的页面数仍旧为系统 I/O能力的5%。
步骤:
1.主线程发出async io请求,async读取需要被meger的索引页面
2.I/O handler 线程,在接受到完成的async I/O之后,进行merger
b 被动merge[用户线程完成,用户能感受到meger操作带来的性能影响]
被动merge:
情况一:
insert操作,导致页面空间不足,需要分裂(split)。由于insert buffer只针对单个页面,不能buffer page split[页已经在内存里],因此引起页面的被动meger。同理,update操作导致页面空间不 足;purge导致页面为空等。总之:若 当前操作引起页面split or merge,那么就会导致被动merge。
情况二:
insert操作,由于其它各种原因,insert buffer优化返回false,需要真正读取page时,要进行被动merge。与一不同的是,页在disk上,需要读取到内存里。
情况三:
在进行insert buffer操作,发现insert buffer太大,需要压缩insert buffer,这时需要强制被动merge,不允许 insert 操作进行。
2.double write
保障innodb引擎的可靠性
背景
部分写失效问题(partial page write)
InnoDB 的Page Size一般是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。而计算机硬件和操作系统,在极端情况下(比如断电)往往并不能保证这一操作的原子性,16K的数据,写入4K 时,发生了系统断电/os crash ,只有一部分写是成功的,这种情况下就是 partial page write 问题。
很多DBA 会想到系统恢复后,MySQL 可以根据redolog 进行恢复,而mysql在恢复的过程中是检查page的checksum,checksum就是pgae的最后事务号,发生partial page write 问题时,page已经损坏,找不到该page中的事务号,就无法恢复。
如果想通过redo log恢复业务无法实现的,因为redo log记录的是对页的物理操作,如偏移量200写‘jinhailan’记录,页本身发生了损坏,无法进行重做.所以需要维护一个副本,在写入失效后,可以通过副本来还原该页在进行重做.
Double write 是InnoDB在 tablespace上的128个页(2个区)是2MB.
原理:
为了解决 partial page write 问题 ,当mysql将脏数据flush到data file的时候, 先使用memcopy 将脏数据复制到内存中的double write buffer ,之后通过double write buffer再分2次,每次写入1MB到共享表空间,然后马上调用fsync函数,同步到磁盘上,避免缓冲带来的问题,在这个过程中,doublewrite是顺序写,开销并不大,在完成doublewrite写入后,在将double write buffer写入各表空间文件,这时是离散写入。
如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏,那么此时就可以从doublewrite buffer中进行数据恢复了。
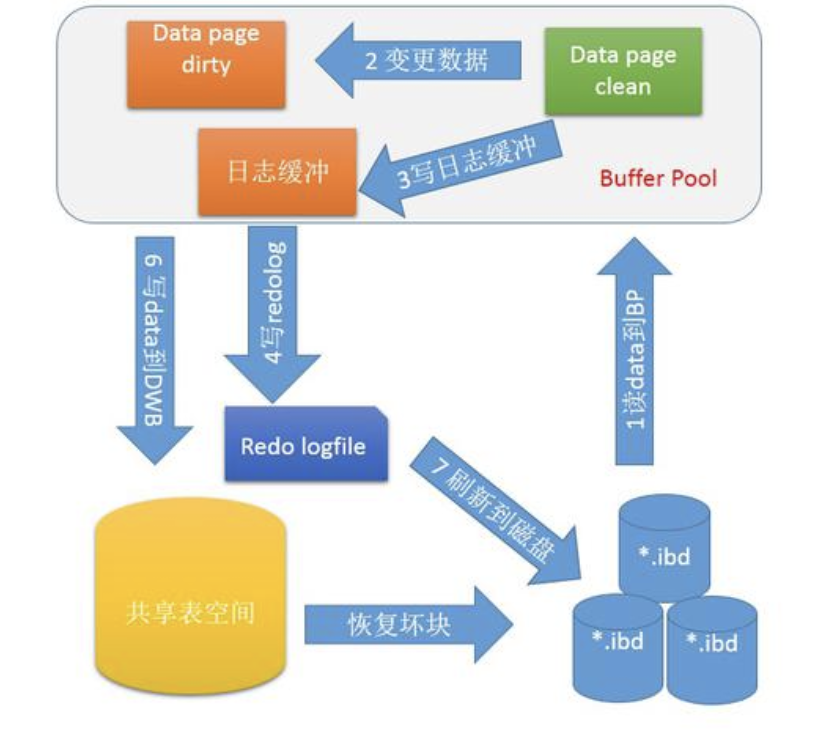
doublewrite的缺点是什么?
位于共享表空间上的doublewrite buffer实际上也是一个文件,写共享表空间会导致系统有更多的fsync操作, 而硬盘的fsync性能因素会降低MySQL的整体性能,但是并不会降低到原来的50%。这主要是因为:
- doublewrite是在一个连续的存储空间, 所以硬盘在写数据的时候是顺序写,而不是随机写,这样性能更高。
- 将数据从doublewrite buffer写到真正的segment中的时候,系统会自动合并连接空间刷新的方式,每次可以刷新多个pages。
double write在恢复时如何工作
If there’s a partial page write to the doublewrite buffer itself, the original page will still be on disk in its real location.---如果是写doublewrite buffer本身失败,那么这些数据不会被写到磁盘,InnoDB此时会从磁盘载入原始的数据,然后通过InnoDB的事务日志来计算出正确的数据,重新 写入到doublewrite buffer.
When InnoDB recovers, it will use the original page instead of the corrupted copy in the doublewrite buffer. However, if the doublewrite buffer succeeds and the write to the page’s real location fails, InnoDB will use the copy in the doublewrite buffer during recovery.
--如果 doublewrite buffer写成功的话,但是写磁盘失败,InnoDB就不用通过事务日志来计算了,而是直接用buffer的数据再写一遍.
InnoDB knows when a page is corrupt because each page has a checksum at the end; the checksum is the last thing to be written, so if the page’s contents don’t match the checksum, the page is corrupt. Upon recovery, therefore, InnoDB just reads each page in the doublewrite buffer and verifies the checksums. If a page’s checksum is incorrect, it reads the page from its original location.
--在恢复的时候,InnoDB直接比较页面的checksum,如果不对的话,就从硬盘载入原始数据,再由事务日志 开始推演出正确的数据.所以InnoDB的恢复通常需要较长的时间.
是否一定需要doublewrite
在一些情况下可以关闭doublewrite以获取更高的性能。比如在slave上可以关闭,因为即使出现了partial page write问题,数据还是可以从中继日志中恢复。设置InnoDB_doublewrite=0即可关闭doublewrite buffer。
如何使用 double write
InnoDB_doublewrite=1表示启动double write
show status like 'InnoDB_dblwr%'可以查询double write的使用情况;
相关参数与状态
Double write的使用情况:
show status like "%InnoDB_dblwr%";
InnoDB_dblwr_pages_written 从bp flush 到 DBWB的个数
InnoDB_dblwr_writes 写文件的次数
每次写操作合并page的个数= InnoDB_dblwr_pages_written/InnoDB_dblwr_writes
自适应哈希索引
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升
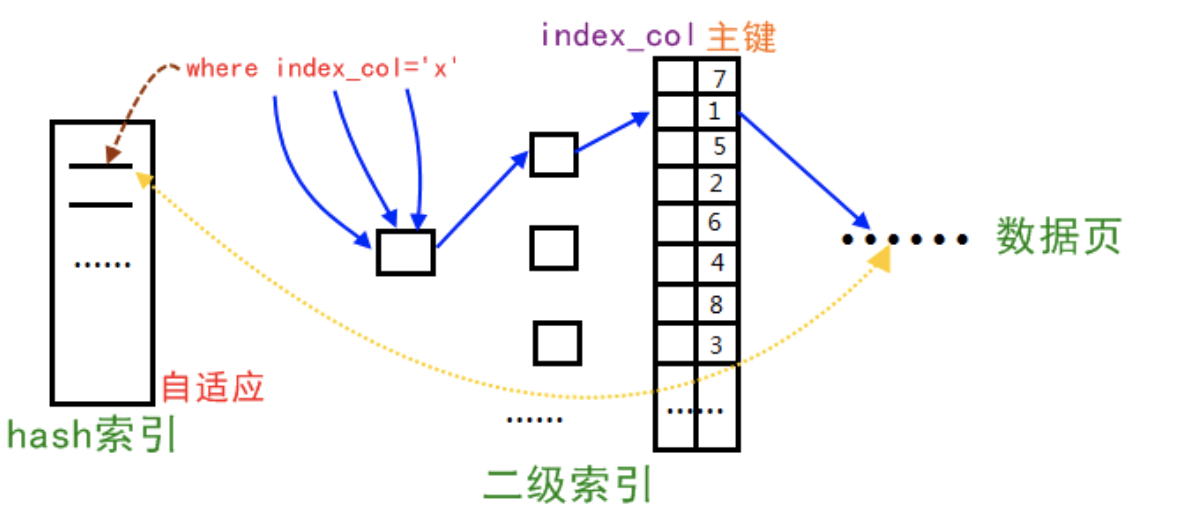
经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
特点
1、无序,没有树高
2、降低对二级索引树的频繁访问资源
索引树高<=4,访问索引:访问树、根节点、叶子节点
3、自适应
3、缺陷
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读。
限制
1、只能用于等值比较,例如=, <=>,in
2、无法用于排序
3、有冲突可能
4、MySQL自动管理,人为无法干预。
由于innodb不支持hash索引,但是在某些情况下hash索引的效率很高,于是出现了adaptive hash index功能,但是通过上面的状态监控,可以计算其收益以及付出,控制该功能开启与否。
默认开启,建议关掉,意义不大。可以通过 set global innodb_adaptive_hash_index=off/on 关闭和打开该功能。
异步IO
为了提高磁盘操作性能,当前的数据库系统都采用异步IO的方式来处理磁盘操作。
1、异步IO:用户可以在发出一个IO请求后立即再发出另外一个IO请求,当全部IO请求发送完毕后,等待所有IO操作完成,这就是AIO。
2、与AIO对应的是Sync IO,即每进行一次IO操作,需要等待此次操作结束才能继续接下来的操作。
异步IO的好处
1、不用等待直接响应上一个用户的请求;
2、多次的请求在一起排序,请求的数据页是在一起的,一次读出来,减少多次读。(数据库的读写请求队列放在文件系统中单独分配的一块小内存结构里,非文件系统的缓存)
邻接页刷新
当刷新一个脏页时,innodb存储引擎会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,增大写入量,减少了物理写IO,故该工作机制在传统机械磁盘下有着显著的优势。
1、在写入次数基本不增加的情况下,增加了写入的量;
2、加速了脏页的回收;
3、充分利用double write每次1M写入的特征;
4、这个功能打开以后会发现iostat里面的wrqm(合并写)这个值会比较高
Flush neighbor page的影响
1、对于insert频繁的系统,这个功能比较适合
2、对于update频繁的系统,这个功能可能会带来一些副作用
1、update顺带着刷新其他页;
2、对于update频繁的表,这些页马上就脏了,白白浪费写负载。
Innodb特性以及实现原理的更多相关文章
- 深入学习MySQL事务:ACID特性的实现原理
事务是MySQL等关系型数据库区别于NoSQL的重要方面,是保证数据一致性的重要手段.本文将首先介绍MySQL事务相关的基础概念,然后介绍事务的ACID特性,并分析其实现原理. MySQL博大精深,文 ...
- 一文说尽MySQL事务及ACID特性的实现原理
MySQL 事务基础概念 事务(Transaction)是访问和更新数据库的程序执行单元:事务中可能包含一个或多个 sql 语句,这些语句要么都执行,要么都不执行.作为一个关系型数据库,MySQL 支 ...
- MySQL InnoDB 实现高并发原理
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- MongoDB · 引擎特性 · MongoDB索引原理
MongoDB · 引擎特性 · MongoDB索引原理数据库内核月报原文链接 http://mysql.taobao.org/monthly/2018/09/06/ 为什么需要索引?当你抱怨Mong ...
- 浅析Mysql InnoDB存储引擎事务原理
浅析Mysql InnoDB存储引擎事务原理 大神:http://blog.csdn.net/tangkund3218/article/details/47904021
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
- 一文快速搞懂MySQL InnoDB事务ACID实现原理(转)
这一篇主要讲一下 InnoDB 中的事务到底是如何实现 ACID 的: 原子性(atomicity) 一致性(consistency) 隔离性(isolation) 持久性(durability) 隔 ...
- innodb master thread 工作原理
参考 innodb参数汇总 InnoDB的Master Thread工作原理 innodb_max_dirty_pages_pct 默认值 show variables like 'innodb_m ...
- InnoDB 数据表压缩原理与限制
http://liuxin1982.blog.chinaunix.net/uid-24485075-id-3523032.html 压缩理念 通过提高CPU利用率和节约成本,降低数据库容量及I/O负载 ...
随机推荐
- 【转】WdatePicker日历控件使用方法
转 自: https://www.cnblogs.com/yuhanzhong/archive/2011/08/10/2133276.html WdatePicke官 ...
- liunx命令用到的
su:切换成root用户 sudo su:普通用户申请root权限 ping命令可以检查linux是否联网 ping www.baidu.com 如图就是联网了 结束ping包括其他linux的指令 ...
- POJ 3050 Hopscotch 四方向搜索
Hopscotch Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6761 Accepted: 4354 Descrip ...
- NO27 定时任务
linux定时任务的设置 为当前用户创建cron服务 1. 键入 crontab -e 编辑crontab服务文件 例如 文件内容如下: */2 * * * * /bin/sh /home/a ...
- Adapter之GridAdapter
前言: 在我们写界面的时候想让我们展示的页面是网格的,这是我们可以使用GridAdapter,这个和listView的使用有相似之处,如果学过ListView的话还是很简单的 正文: 下面我们来看看G ...
- windows下安装多台mysql数据库且实现主从复制
版本如下: windows server 2012 R2 mysql server 5.7.25安装版 / mysql server 5.7.25 解压版 * 这里为啥还要有安装版和解压版勒,主要是因 ...
- Android的事件处理机制之基于回调的事件处理
回调机制 如果说事件监听机制是一种委托式的事件处理,那么回调机制则与之相反,对于基于回调的事件处理模型来说,事件源与事件监听器是统一的,换种方法说事件监听器完全消失了,当用户在GUI组件上激发某个事件 ...
- java#类的实例化顺序
关于类的实例化,不用弄的那么细致,这里只说单一类,没有其他父类(排除Obejct)的情况.要实例化一个类,需要加载class文件到jvm并且验证通过了是安全的字节码文件. 初始化大致上是按照如下步骤: ...
- vDom和domDiff
虚拟dom和domDiff 1. 构建虚拟DOM var tree = el('div', {'id': 'container'}, [ el('h1', {style: 'color: blue'} ...
- Problem B: Bulbs
Problem B: Bulbs Greg has an m×n grid of Sweet Lightbulbs of Pure Coolness he would like to turn on. ...