3.k均值的算法
一、课堂练习
# 课堂练习
from sklearn.datasets import load_iris
# 导入鸢尾花数据
iris=load_iris()
iris
iris.keys()
data=iris['data'] #鸢尾花数据
target=iris.target #标签,属于哪一种花
iris.feature_names #特征名:花萼长度、花萼宽度、花瓣长度、花瓣宽度
# 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'
图:

二、作业
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类


| 第一次分类 | 第一次类中心 | 1 | 8 | 13 |
| sum | 18 | 127 | 86 | |
| mean | 18/8 | 127/18 | 86/7 | |
| 第二次分类 | 第二次类中心 | 2.25 | 7.05 | 12.28 |
| sum | 18 | 107 | 106 | |
| mean | 18/8 | 107/16 | 106/9 | |
| 第三次分类 | 第三次新中心 | 2.25 | 6.68 | 11.77 |
| sum | 18 | 107 | 106 | |
| mean | 18/8 | 107/16 | 106/9 | |
| 聚类中心 | 中心 | 2.25 | 6.68 | 11.77 |
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
from sklearn.datasets import load_iris #导入数据
import numpy as np #numpy库
import random #生成随机的类中心
import matplotlib.pyplot as plt #画图
# 定义的参数是:数据源、聚类中心个数、属性个数
def KKmeans(dataset,k): #定义一个函数,参数是数据源和k值
n=dataset.shape[0] #样本数
m=dataset.shape[1] #样本属性
rand=random.sample(range(0,n),k)
center=dataset[rand,] #k是聚类中心数,k=3的话,从中随机取三个
dist=np.zeros([n,k+1]) #相当于一个nx(k+1)的矩阵,前k列是聚类中心值,最后一列用来分类
centernew=np.zeros([k,m]) #新的聚类中心就是一个kxm的矩阵,k是k行,m是属性个数
while True:
for i in range(n): # 每一行都做运算
for j in range(k): # 第一行的第一列就是第一个数与聚类中心的欧式距离
dist[i, j] = np.sqrt(sum((dataset[i, :] - center[j, :]) ** 2)) # 欧式距离
dist[i, k] = np.argmin(dist[i, :k]) # 从前k个值中取最小值的下标赋给分类的列 for i in range(k): #这一步进行归类和归类后的平均值计算,得到新的类中心
index = dist[:, k] == i
centernew[i, :] = dataset[index, :].mean(axis=0) if (np.all(center == centernew)): #如果新的类中心所有的元素和类中心一样,跳出程序
break;
else:
center = centernew #没有一样的类中心,就将新的类中心赋值,从新再聚类
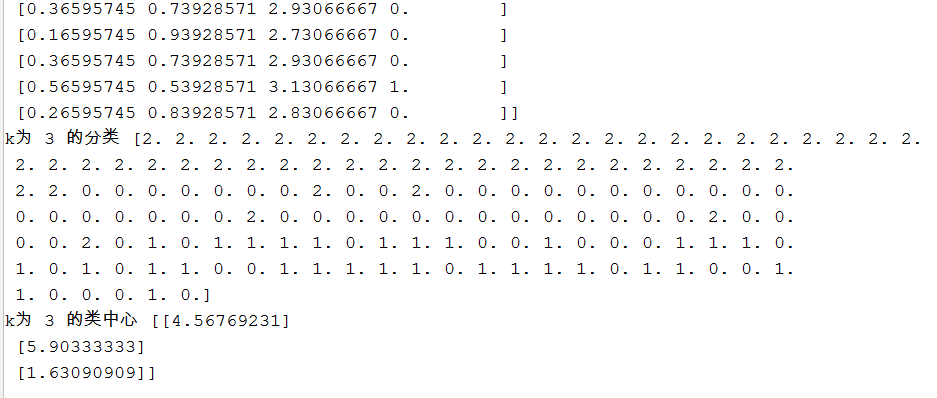
print("k为",k,"的欧式距离和分类",dist)
print("k为",k,"的分类",dist[:,3])
print("k为",k,"的类中心",centernew)
return dist[:, 3]
kdata=iris.data[:,2].reshape(-1,1) #数据是鸢尾花的花瓣长度
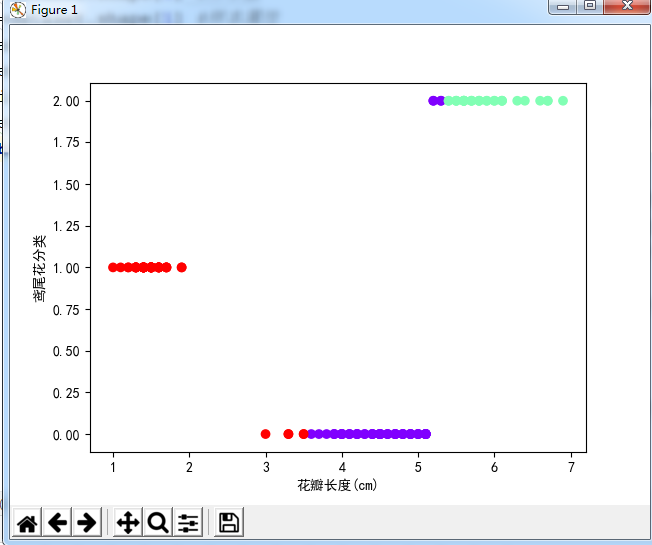
KKmeans(kdata,3) #调用函数,第一个参数是数据,第二个参数是k值,即聚类中心
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.scatter(kdata,KKmeans(kdata,3),c=KKmeans(kdata,3),cmap="rainbow")
plt.xlabel("花瓣长度(cm)")
plt.ylabel("鸢尾花分类")
plt.show()
图:
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 导入鸢尾花数据
iris=load_iris()
data=iris['data'] #鸢尾花数据
petal=data[:,2] #花瓣长度数据
# # 换成n行1列,-1是任意行的意思
X_petal=petal.reshape(-1,1)
model1=KMeans(n_clusters=3) #构建模型,聚类中心个数为3
model1.fit(X_petal) #模型训练
Y_petal=model1.predict(X_petal) #模型训练过后,根据花瓣长度预测分类
# c是按颜色分类,cmap是设置颜色
# x轴是花瓣数据,y轴是鸢尾花分类
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.scatter(X_petal[:,0],Y_petal,c=Y_petal,cmap="rainbow")
plt.xlabel("花瓣长度(cm)")
plt.ylabel("鸢尾花分类")
图:

4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 导入鸢尾花数据
iris=load_iris()
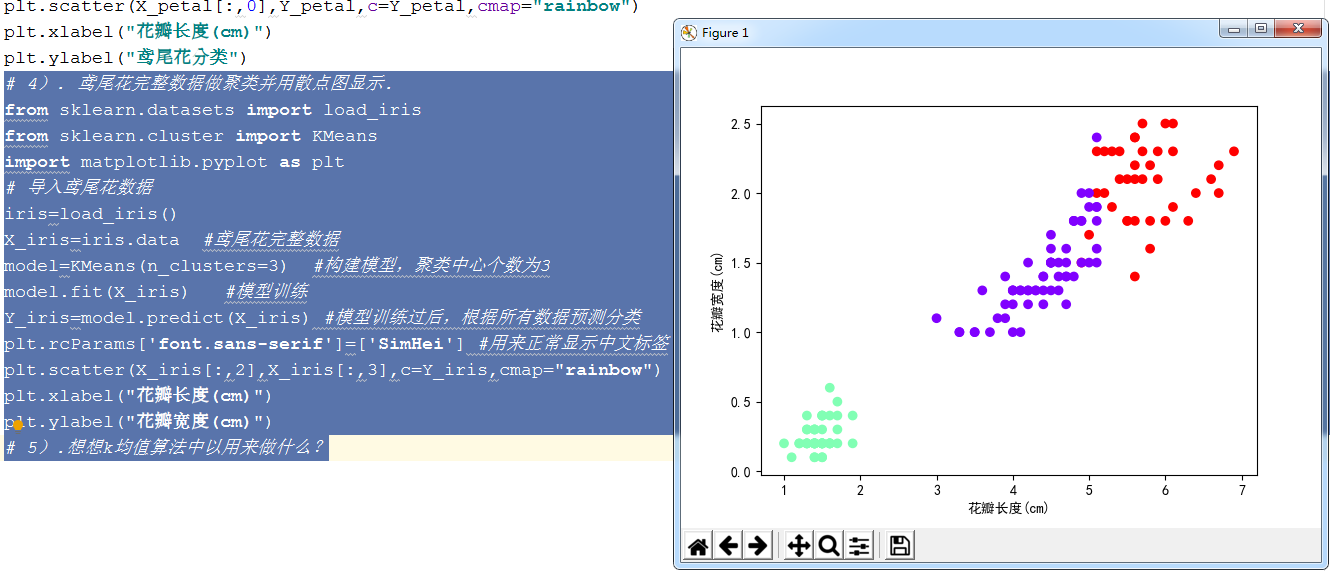
X_iris=iris.data #鸢尾花完整数据
model=KMeans(n_clusters=3) #构建模型,聚类中心个数为3
model.fit(X_iris) #模型训练
Y_iris=model.predict(X_iris) #模型训练过后,根据所有数据预测分类
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.scatter(X_iris[:,2],X_iris[:,3],c=Y_iris,cmap="rainbow")
plt.xlabel("花瓣长度(cm)")
plt.ylabel("花瓣宽度(cm)")
图
5).想想k均值算法中以用来做什么?
K均值算法属于聚类算法,可以将没有标签的数据进行分类。
在实际生活中,可以帮助细分市场,可以将客户划分至不同的细分市场组,以便营销和服务;
又或者可以进行社交网络分析,观察人与人之间的互相来往,从而查找一群互相有关系的人等等。
3.k均值的算法的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- K-Means(K均值)算法
昨晚在脑内推导了一晚上的概率公式,没推导出来,今早师姐三言两语说用K-Means解决,太桑心了,昨晚一晚上没睡好. 小笨鸟要努力啊,K-Means,最简单的聚类算法,好好实现一下. 思路: 共有M个样 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法总结
这几天在一个项目上需要用到K均值聚类算法,以前都是直接利用百度老师copy一个Kmeans算法代码,这次想自己利用已知的算法思想编写一下,编写才知道,虽然熟悉了算法思想,真正实现时,还是遇到不少bug ...
随机推荐
- 经验总结:超详细的 Linux C/C++ 学习路线!大厂面试指南
❝ 文章每周持续更新,「三连」让更多人看到是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) ❞ 最近在知乎经常被邀请回答类似如何学习C++和C++后台开 ...
- Spring Boot整合Thymeleaf视图层
目录 Spring Boot整合Thymeleaf Spring Boot整合Thymeleaf 的项目步骤 Thymeleaf 语法详解 Spring Boot整合Thymeleaf Spring ...
- Luogu1039 侦探推理
题目描述 明明同学最近迷上了侦探漫画<柯南>并沉醉于推理游戏之中,于是他召集了一群同学玩推理游戏.游戏的内容是这样的,明明的同学们先商量好由其中的一个人充当罪犯(在明明不知情的情况下),明 ...
- 【Net】ABP框架学习之它并不那么好用
前言 上一篇文章介绍了ABP的Web API,本文在继续介绍ABP的其他内容. 在ABP中,WEBAPI是一个值得用的东西.但其他东西,就不一定是那么好用了. 下面我们看一下ABP的Controlle ...
- js实现 多级联动
<head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8&quo ...
- 使用 Spring data redis 结合 Spring cache 缓存数据配置
使用 JavaConfig 方式配置 依赖 jar 包: jedis.spring-data-redis 首先需要进行 Redis 相关配置 @Configuration public class R ...
- SSAS 第一篇:多维数据分析基础
多维数据分析是指按照多个维度(即多个角度)对数据进行观察和分析,多维的分析操作是指通过对多维形式组织起来的数据进行切片 .切块.聚合.钻取 .旋转等分析操作,以求剖析数据,使用户能够从多种维度.多个侧 ...
- MTK Android修改System分区
Z:\rk3326_p_hq_rf8637sa\device\rockchip\common\BoardConfig.mk #Calculate partition size from paramet ...
- Golang微信支付跳过X509验证
游戏支付提交到微信的post: 微信: https://pay.weixin.qq.com/wiki/doc/api/micropay.php?chapter=23_4 错误信息: err:Post ...
- 了解这5大K8S管理服务,为你节省50%的部署时间!
Kubernetes已然成为IT世界的重要组成部分,并且仍在不断地发展壮大,现阶段,Kubernetes已经可以帮助企业进行微服务训练,加速企业数字化转型.尽管Kubernetes是一款如此令人印象深 ...