PCA主成分分析(上)
之前看3DMM的论文的看到其用了PCA的方法,一开始以为自己对于PCA已经有了一定的理解,但是当看到式子的时候发现自己好像对于原理却又不甚明了,所以又回顾了以下PCA的原理,在此写一个总结。
PCA目的
主成分分析(principal component analysis, PCA) 是常用的一种降维方法,其目的是为了让数据合理的降维,在降低维度的同时尽量保证数据的原始信息不过于流失,同时减少数据的相关性。也可以理解为,对于正交属性空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。
基于以上的目的可以大致分为两种
- 最大可分性: 样本点在这个超平面上的投影尽可能的分开(即投影后的方差最大)
- 最近重构性: 样本点到这个超平面的距离都足够近
最大可分性(最大投影方差)
我们的目的是为了让投影后的信息量的尽量保持原样,那么为什么方差越大信息量就越多?
我们知道信息量可以通过信息熵来描述,信息熵的定义为:变量的概率分布和每个变量的信息量构成了一个随机变量,这个随机变量的期望就是这个分布产生的信息量的熵
\]
其描述了样本的不确定度。举个例子,如果一个文档中字母全是 a,那么 \(p(a) = 1\),其信息量为 \(logp(a) = 0\) 可以知道这个文档的信息量完全不混乱,换言之字母a所承载的信息量为0,也可以理解为字母a对于这个系统毫无意义,所以采取 \(logp(a) = 0\) 来表示。同时也可以看到其方差也为0。
那是不是所有的方差都和熵表达的是一样的事呢?
再看看方差的定义:一个随机变量的方差描述的是它的离散程度,也就是该变量离其期望值的距离。
\]
通过以上的两个定义可以看出,方差描述的是与均值(期望)的离散程度, 而信息熵描述的是 不确定程度 ,仅仅与随机变量的分布有关,与其的具体取值无关。
在某些情况下,当方差越大,信息熵不一定越大。如下图
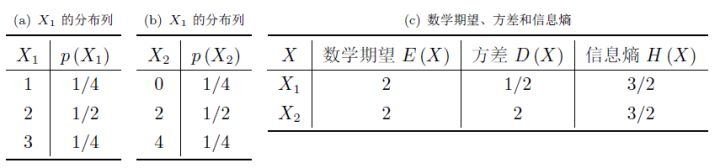
再回到PCA的目的,是为了保持降维后信息量的最大化。但由于我们当处理一个具体的事件时,并无法准确得到数据是以什么概率分布产生的,这样计算信息熵也就没有什么意义。而对于某些分布,如下

可以看出,在大部分情况下,方差越大信息熵也越大,即用方差去描述不确定性和信息熵描述不确定性在这些分布的情况下等价。
当然也有不等价的情况,只是在这种情况下,考虑方差就不一定成立.
以上是一种考虑方式,另一种直接通过投影如下图
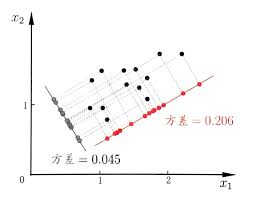
图片来源于西瓜书
可以看到,可以将二维向量投影到红线或者灰线,当然还有很多可以选择的投影方向,那么问题在于哪一个投影方向是最好的呢?对于红线而言投影后样本点更分散,所以其包含的信息量更大。
所以,根据以上信息我们需要找到的是进行降维后,对于不同样本在同一纬度的值差异大的纬度
投影
假设有m个n维数据 \(X(x^{(1)}, x^{(2)},...,x^{(m)})( n \times m)\) (后面均用这个例子),该数据需要先经历中心化,然后经过投影变换后得到了新的坐标系为 \(\{w_1,w_2,...,w_n\}\),其中 \(w\) 是标准正交基, 即 \(||w||_2=1, w_i^Tw_j=0\)。
这里可以想象成对于任意一个样本点 \(x_i\) 投影到任意新坐标轴 \(w_j\) 上的所表达的坐标为 \(z_j = w_j^Tx_i\), 所以这里 \(z_j\) 就表示了低纬坐标系里第 \(j\) 纬的坐标。
即对于任意一个样本 \(x^{(i)}\) 在新坐标系中的投影为 \(W^Tx^{(i)}\)
优化目标
所以对于基于最大方差投影的PCA算法的优化目标是:
- 降维后投影在各个方向的方差和最大
- 不同纬度之间的相关性为0
根据优化目标如何得到降维后的数据呢?
这里先给出步骤:
将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
求出协方差矩阵 \(C=\frac{1}{m}XX^\mathsf{T}\)
求出协方差矩阵的特征值及对应的特征向量
取最大的 \(n'\) 个特征值所对应的所对应的特征向量,组成的矩阵 \(W\) 即是投影矩阵
\(Z=W^TX\)即为降维到 \(n'\) 维后的数据集
关键点
- 为什么要将X的每一行进行0均值化(即每一个属性字段0均值化)
- 为什么要求去协方差矩阵
首先我们知道同一特征的协方差表示该元素的方差,不同特征之间的协方差表示他们的相关性,如下, 假设针对特征 \((f_1,f_2,...,f_n)\) 有协方差矩阵为
\]
其中, 对于特征 \((X,Y)\)
Cov\left( X,Y \right)&=E\left[ \left( X-E\left( X \right) \right)\left( Y-E\left( Y \right) \right) \right] \\ &=\frac{1}{n-1}\sum_{i=1}^{n}{(x_{i}-\bar{x})(y_{i}-\bar{y})}
\end{aligned}
\]
所以根据我们的求取的目标(同一纬度方差最大化,不同纬度相关性为0)可以用以下的协方差矩阵来表示
\]
这里引入矩阵的迹
数学定义: 在线性代数中,一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。
假设将数据从 \(n\) 维降到 \(n'\) 维, 所以要优化的目标之一便是令 \(Cov(f_1,f_2, ..., f_{n'})\) 矩阵对角线元素之和最大,即 \(max(\delta_{11}, \delta_{22}, ... ,\delta_{n'n'})\)
推导
设有m个n维数据\(X (x^{(1)}, x^{(2)},...,x^{(m)})(n \times m)\) , 首先将数据X的每一维进行中心化, 原因在于求协方差矩阵的时候需要用到 \((x_i - \bar x)(y_i - \bar y)\) 所以原始数据变成
\begin{bmatrix}
x_{11} - u_1 & x_{12} - u_1 & ... & x_{1m} - u_1 \\
x_{21} - u_2 & x_{22} - u_2 & ... & x_{2m} - u_2 \\
... & ... & ... & ... \\
x_{n1} - u_n & x_{n2} - u_n & ... & x_{nm} - u_n
\end{bmatrix}\]
\(W \{w_1,w_2,...,w_n\}\) 为 \((n \times n)\) 的标准正交基矩阵(投影矩阵), \(Y = W^TX\) 为投影后的样本矩阵(新坐标系中任何一个样本的投影方差为 \(x^{(i)T}WW^Tx^{(i)}\))
则 \(Y\) 的协方差矩阵(根据维度数来考虑)为
C_Y &= \frac{1}{m} YY^T \\
&= \frac{1}{m} W^TXX^TW \\
&= W^T (\frac{1}{m} XX^T) W
\end{aligned}
\]
设 \(C = \frac{1}{m} XX^T\) 可得
\]
而优化的目标为
\underbrace{arg\;max}_{W}\;tr( W^TCW ) \\
W^TW=I
\end{matrix}\right. \tag1
\]
由于 \(C\) 已知,目的是为了求取极值, 利用拉格朗日函数(设给定函数 \(z=ƒ(x,y)\) 在满足 \(φ(x,y)=0\)下的条件极值,可以转化为函数 \(F(x,y,\lambda) = f(x,y) + \lambda φ(x,y)\) 的无条件极值问题)
所以上式(1) 就转化为
\]
等式两遍对W求导
\]
令导数为0,即 \(\frac{\partial f}{\partial W} = 0\), 且有性质 \(\frac{\partial tr(AB)}{\partial A} = B^T\), \(\frac{\partial tr(AB)}{\partial B} =A^T\),\(\frac{\partial X^TX}{\partial X} = X\) 可得
\]
由上式可以看出, \(W\) 是 \(XX^T\) 的特征向量组成的矩阵, 而 \(-\lambda\) 是 \(XX^T\) 的若干个特征值组成的矩阵,特征值在主对角线上,其余位置为0。 当将数据从 \(n\) 维降到 \(n'\) 维时, 需要找到最大的 \(n'\) 个特征值对应的特征向量, 这 \(n'\) 个特征向量组成的矩阵 \(W\) 即维我们需要的新坐标系矩阵,对于原始的数据集, 只需要利用 \(W^TX\), 就可以把原始数据集降维到最小投影距离的 \(n'\) 维数据集。
ps: 这里有一个性质 实对称矩阵不同特征值对应的特征向量互相正交, 在这里我们的 \(C_Y\) 是一个协方差矩阵,而协方差矩阵是一个实对称矩阵
为什么要找最大特征值对应的特征向量呢?
假设有样本点如下(已经做过预处理,均值为0),以及可投影的维度
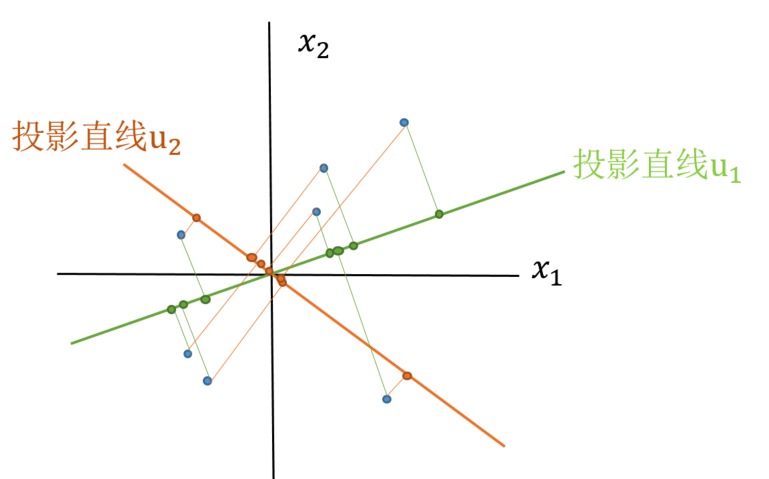
我们知道向量点乘的意义是,一个向量对于某一个单位向量的投影(向量对这个单位向量的线性变换),即 \(\vec{A} \cdot \vec{B}\) 的意义是向量A在向量B上的投影长度乘以向量B的模长(对如果B是一个平面也适用,即B为新的平面的基向量)。
所以对于任意维度的投影直线 \(u\)(列向量) 其投影后的样本方差为:
\]
由于已经在一开始就进行了 \(X\) 的零均值处理,以及向量加法的分配律可以得知 \(所有{{x^{i}}^Tu}的均值 = 0\)
所以最终方差为
\]
对上式进行变换 (根据向量的交换律\(a \cdot b = b \cdot a\))
\]
由上式可以发现,括号内的部分就是样本特征的协方差矩阵, 现在我们已经得到这个方差的表达方式,那么如何使得这个方差最大呢?令方差 \(\frac{1}{m} \sum_{i=1}^{m}({x^{i}}^Tu )^2 = \lambda, C = \frac{1}{m}\sum_{i=1}^{m}{x^ix^{i}}^T\) ,于是上式就变成了
\]
因为 \(u^Tu = 1\) 同理, 为了使得方差最大,利用拉格朗日乘子法可以得知:
\]
将上式求导,是之为0, 得到:
\]
所以为了使得方差 \(\lambda\) 最大,也就是取协方差矩阵 \(C\) 的最大特征值,与其对应的特征向量,为了使选取的 \(n'\) 维空间各个维度方差之和最大,就是取最大的 \(n'\) 个特征值以及其对应的特征向量。 从这里也可以看出,由于 \(C\) 使协方差矩阵,也就是实对称矩阵, 所以其特征特征向量两两正交。
参考:
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
https://www.cnblogs.com/pinard/p/6239403.html#!comments
https://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
PCA主成分分析(上)的更多相关文章
- 用PCA(主成分分析法)进行信号滤波
用PCA(主成分分析法)进行信号滤波 此文章从我之前的C博客上导入,代码什么的可以参考matlab官方帮助文档 现在网上大多是通过PCA对数据进行降维,其实PCA还有一个用处就是可以进行信号滤波.网上 ...
- 机器学习之PCA主成分分析
前言 以下内容是个人学习之后的感悟,转载请注明出处~ 简介 在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性.人们自然希望变量个数较少而得到的 信息较多.在很 ...
- PCA主成分分析Python实现
作者:拾毅者 出处:http://blog.csdn.net/Dream_angel_Z/article/details/50760130 Github源代码:https://github.com/c ...
- 机器学习 - 算法 - PCA 主成分分析
PCA 主成分分析 原理概述 用途 - 降维中最常用的手段 目标 - 提取最有价值的信息( 基于方差 ) 问题 - 降维后的数据的意义 ? 所需数学基础概念 向量的表示 基变换 协方差矩阵 协方差 优 ...
- PCA(主成分分析)方法浅析
PCA(主成分分析)方法浅析 降维.数据压缩 找到数据中最重要的方向:方差最大的方向,也就是样本间差距最显著的方向 在与第一个正交的超平面上找最合适的第二个方向 PCA算法流程 上图第一步描述不正确, ...
- PCA 主成分分析
链接1 链接2(原文地址) PCA的数学原理(转) PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表 ...
- PCA主成分分析方法
PCA: Principal Components Analysis,主成分分析. 1.引入 在对任何训练集进行分类和回归处理之前,我们首先都需要提取原始数据的特征,然后将提取出的特征数据输入到相应的 ...
- 【建模应用】PCA主成分分析原理详解
原文载于此:http://blog.csdn.net/zhongkelee/article/details/44064401 一.PCA简介 1. 相关背景 上完陈恩红老师的<机器学习与知识发现 ...
- PCA主成分分析+白化
参考链接:http://deeplearning.stanford.edu/wiki/index.php/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90 h ...
随机推荐
- 为什么scanf(" %c",&c)中%c前要空格?
空格确实不是必须的,但有了空格就可以忽略你输入的空格. ****例如:scanf(" %c" ,&c),你输入了' a'(a前面有个空格),a就能被c接受. 但控制符前如果 ...
- 【linux】【tomcat】linux下定时重启tomcat 【CentOS 6.4】【CentOS 7.6】
本章内容以CentOS 6.4 和 CentOS 7.6 两个版本为例.[6和7的命令不同] 转载 :https://www.cnblogs.com/sxdcgaq8080/p/10730 ...
- ArrayList 迭代器学习笔记
我们先来看一段代码: List<String> list = new ArrayList<>(); list.add("str1"); list.add(& ...
- VBScript - 弹出“文件选择对话框”方法大全!
本文记录,VBScript 中,各种打开 "文件选择对话框" 的方法. 实现方法-1 (mshta.exe): 首先,我们要实现的就是,弹出上面的这个"文件选择对话框&q ...
- Nginx知多少系列之(一)前言
目录 1.前言 2.安装 3.配置文件详解 4.工作原理 5.Linux下托管.NET Core项目 6.Linux下.NET Core项目负载均衡 7.Linux下.NET Core项目Nginx+ ...
- udev规则,部署Multipath
部署Multipath多路径环境 配置iSCSI服务 编写udev规则 配置并访问NFS共享 部署Multipath多路径环境 1 配置iSCSI服务 1.1 问题 本案例要求先搭建好一台iSCSI服 ...
- C语言数据结构无向图
#include<stdio.h>#include<stdlib.h>#define num 8struct nearnode{ int order; nearnode* pn ...
- .bundle文件如何安装
1. sudo chmod +x X.bundle 2. sudo X.bundle
- template_homepage
homepage用到的方法 使用 {% for ... in ...%} 加 {% endfor %} 实现循环结构 举例: {% for post in posts %} <p style ...
- Flutter 吐血整理组件继承关系图
老孟导读:前几天一个读者和我说能不能整理一个各个控件之间的继承关系,这2天抽时间整理了一下,不整理不知道,一整理真的吓一跳啊,仅仅Widget的子类(包括间接子类)就高达353个,今天发群里给大家浏览 ...