基于R语言的航空公司客户价值分析
分析航空公司现状
1.行业内竞争
民航的竞争除了三大航空公司之间的竞争之外,还将加入新崛起的各类小型航空公司、民营航空公司,甚至国外航空巨头。航空产品生产过剩,产品同质化特征愈加明显,于是航空公司从价格、服务间的竞争逐渐转向对客户的竞争。
2.行业外竞争
随着高铁、动车等铁路运输的兴建,航空公司受到巨大冲击。
航空公司客户数据说明
目前航空公司已积累了大量的会员档案信息和其乘坐航班记录。
以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据,44个特征,总共62988条记录。数据特征及其说明如下表所示。

案例目标
结合目前航空公司的数据情况,实现以下目标。
1、数据清洗
(1)数据分析,找出数据存在的问题(例如:异常值、缺失值),给出处理办法
(2)使用R语言对数据进行处理,给出代码、对使用的函数进行说明
2、构建航空客户价值分析的关键特征
构建航空客户价值分析的关键特征(从44个变量中选择出适合后期聚类的变量),选择客户价值分析模型,对模型进行解释。
3、数据标准化
(1)数据标准化的目的是什么?
(2)对于2中选出的变量进行标准化(代码)
(3)并将标准化后的数据存入文件
(4)截图(5分)
4.对数据进行聚类分群
(1)给出聚类算法(代码+函数解释)
(2)分析聚类结果,对客户价值进行评价
(3)对结果进行可视化表示,可选择多种图形进行表示
(4)给出营销策略
实现过程
数据清洗
(1)数据分析,找出数据存在的问题(例如:异常值、缺失值),给出处理办法
- 通过对数据观察发现原始数据中存在票价为空值,票价最小值为0,折扣率最小值为0,总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成。
处理方法:丢弃票价为空的记录。 - 其他的数据可能是客户乘坐0折机票或者积分兑换造成。由于原始数据量大,这类数据所占比例较小,对于问题影响不大,因此对其进行丢弃处理。
处理方法:丢弃票价为0,平均折扣率不为0,总飞行公里数大于0的记录。
(2)使用R语言对数据进行处理,给出代码、对使用的函数进行说明
#设置工作空间
setwd("D:/develop/R/workspace")
#读取数据
datafile<-read.csv('./data/航空公司数据集.csv',header=T)
#查询数据
View(datafile)
#选择数据探索变量
col=c(15:18,20:29)
#输出数据概览
summary(datafile[,col])
#找出票价为缺失值的数据
na_index<-is.na(datafile$SUM_YR_1) | is.na(datafile$SUM_YR_2)
na_datafile<-datafile[which(na_index==1),]
#缺失值数据占总数据的比例
nrow(na_datafile)/nrow(datafile) *100
#丢弃票价为空的记录
#先识别观测窗口第一年、第二年票价收缺失值所在的行,然后删除;$符号表示中文“的”意思, “,”前面表示行,后面表示列。
delet_na = datafile[-which(is.na(datafile$SUM_YR_1) |
is.na(datafile$SUM_YR_2)),]
#查看相应记录及所占比例
index<-((delet_na$SUM_YR_1==0 & delet_na$SUM_YR_2==0)
*(delet_na$avg_discount!=0)
*(delet_na$SEG_KM_SUM>0))
nrow(delet_na[which(index==1),])/nrow(datafile) *100
#丢弃异常的记录
deletdata<-delet_na[-which(index==1),]
#保存数据
write.csv(deletdata,'./tmp/cleanedfile.csv',row.names = FALSE)


构建航空客户价值分析的关键特征
LRFMC模型:将客户关系长度L,消费时间间隔R,消费频率F,飞行里程M和折扣系数的平均值C作为航空公司识别客户价值的关键特征记为LRFMC模型。
L;会员入会时间距观测窗口结束的月数。
R:客户最近一次乘坐公司飞机距观测窗口结束的月数。
F:客户在观测窗口内乘坐公司飞机的次数。
M:客户在观测窗口内累计的飞行里程。
C:客户在观测窗口内乘坐舱位所对应的折扣系数的平均值。
#读取数据
cleanedfile<-read.csv('./tmp/cleanedfile.csv',header = T)
#查看字段名
names(cleanedfile)
#选取6个相关属性变量
LRFMC<-c('FFP_DATE','LOAD_TIME','FLIGHT_COUNT','SEG_KM_SUM','LAST_FLIGHT_DATE','avg_discount')
reduceddata<-cleanedfile[,LRFMC]
#保存数据
write.csv(reduceddata,'./tmp/reducedfile.csv',row.names = FALSE)
#读取数据
cleanedfile<-read.csv('./tmp/cleanedfile.csv',header = T)
#查看字段名
names(cleanedfile)
#选取6个相关属性变量
LRFMC<-c('FFP_DATE','LOAD_TIME','FLIGHT_COUNT','SEG_KM_SUM','LAST_FLIGHT_DATE','avg_discount')
reduceddata<-cleanedfile[,LRFMC]
#保存数据
write.csv(reduceddata,'./tmp/reducedfile.csv',row.names = FALSE)
#数据读取
reducedfile<-read.csv('./tmp/reducedfile.csv',header = T)
#查看数据字段类型
str(reducedfile)
#因子型数据转换为日期格式
reducedfile$FFP_DATE<-as.Date(reducedfile$FFP_DATE)
reducedfile$LOAD_TIME<-as.Date(reducedfile$LOAD_TIME)
reducedfile$LAST_FLIGHT_DATE<-as.Date(reducedfile$LAST_FLIGHT_DATE)
#添加L和R L为离当前时间的入会月数 R为离当前时间的最近坐飞机的时间
reducedfile<-transform(reducedfile,L=difftime(LOAD_TIME,FFP_DATE,units = 'days')/30,
R=difftime(LOAD_TIME,LAST_FLIGHT_DATE,units = 'days')/30)
#查看概要
summary(reducedfile)
#删除缺失值 na.omit为删除所有包含缺失值的行
reducedfile<-na.omit(reducedfile)
#摘取有用的数据 并对指标进行重命名
transformeddata<-reducedfile[,c('L','R','FLIGHT_C','SEG_KM_SUM','avg_discount')]
colnames(transformeddata)<-c('L','R','F','M','C')
#保存数据
write.csv(transformeddata,'./tmp/transformedfile.csv',row.names = FALSE)
数据标准化
(1)数据标准化的目的是什么
五个特征的取值范围数据差异较大,数据标准化可以消除数据量级对数据带来的影响。
(2)对于2中选出的变量进行标准化(代码)
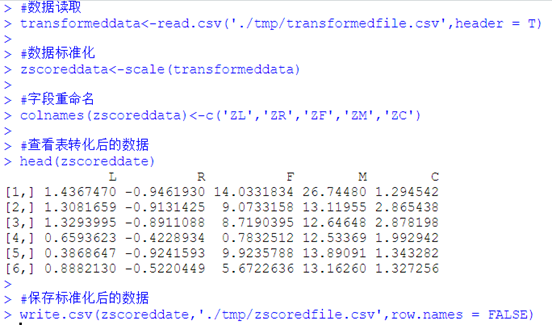
#数据读取
transformeddata<-read.csv('./tmp/transformedfile.csv',header = T)
#数据标准化
zscoreddata<-scale(transformeddata)
#字段重命名
colnames(zscoreddata)<-c('ZL','ZR','ZF','ZM','ZC')
#查看表转化后的数据
head(zscoreddate)
(3)并将标准化后的数据存入文件
#保存标准化后的数据
write.csv(zscoreddate,'./tmp/zscoredfile.csv',row.names = FALSE)
(4)截图
对数据进行聚类分群
(1)给出聚类算法(代码+函数解释
#数据读取
inputfile<-read.csv('./tmp/zscoredfile.csv',header = T)
#聚类分析
result<-kmeans(inputfile,5)
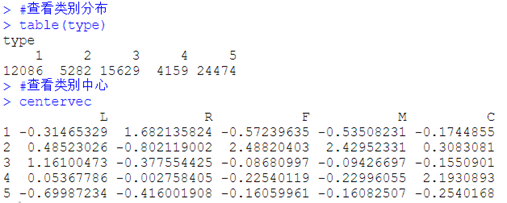
#结果输出 cluster表示各类别编号 center表示各类的中心
type<-result$cluster
centervec<-result$centers
#查看类别分布
table(type)
#查看类别中心
centervec
(2)分析聚类结果,对客户价值进行评价
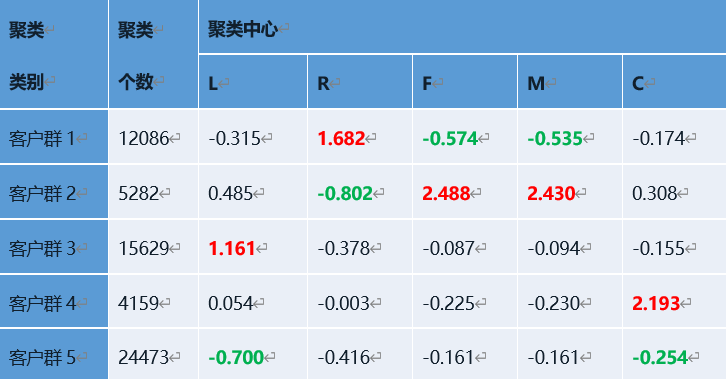
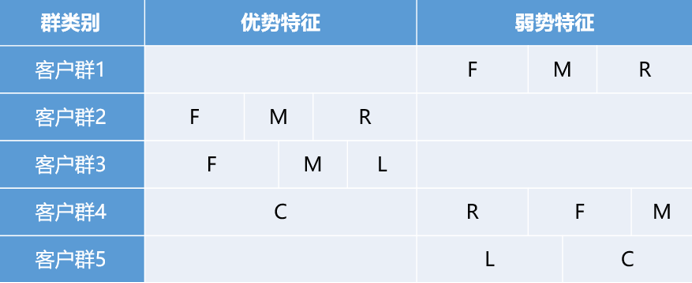
基于特征描述,定义五个等级的客户类别:重要保持客户,重要发展客户,重要挽留客户,低价值客户。每种客户类别的特征如图所示。

客户群1,R最大已经很久没有登机了,同时F、L、M、G最小,也就是说这个客户极可能是折扣率很低的时候才选择坐飞机,属于低价值客户。
客户群2,公里数M、登机的频次F比较高,最近登机的时间间隔R以及折扣C比较低,这样的客户是重要保持客户。
客户群3,入会时间L最长,但是距最近登记时间间隔R比较短,折扣率C比较低,公里数M和频次F也比较低,属于重要挽留客户。
客户群4,尽管公里数M和频次F比较小,但是入会时间L和最近登机的间隔R很短,同时折扣率C最高,属于重要发展客户。
客户群5,R、F、L、M、C五个指标都很小,属于一般客户。
(3)对结果进行可视化表示,可选择多种图形进行表示
雷达图:
①设置各个变量的取值范围,即最大值和最小值
②设置准备绘图指标类型的数据
③把变量取值范围和数据组合成为新的数据集
④进行绘图
#绘制雷达图
#导入数据包
library(fmsb)
#设置各变量的最大值最小值
#centervec为矩阵对象,2表示列操作,max/min为处理数据函数
max<-apply(centervec,2,max)
min<-apply(centervec,2,min)
#把变量取值范围和数据组合成为新的数据集
df=data.frame(rbind(max,min,centervec))
#绘制雷达图
#seg=5表示分为五个等分,plty=1表示使用实线,vlcex为坐标字体大小
radarchart(df=df,seg=5,plty=1,vlcex=0.7)

绿线代表的客户群1属于低价值客户。
深蓝线代表的客户群2是重要保持客户。
红线代表的客户群3属于重要挽留客户。
黑线代表的客户群4属于重要发展客户。
浅蓝线代表的客户群5属于一般客户。
(4)给出营销策略
- 会员的升级与保级:航空公司可以在对会员升级或保级进行评价的时间点之前,对那些接近但尚未达到要求的较高消费客户进行适当提醒甚至采取一些促销活动,刺激他们通过消费达到相应标准。这样既可以获得收益,同时也提高了客户的满意度,增加了公司的精英会员。
- 首次兑换:采取的措施是从数据库中提取出接近但尚未达到首次兑换标准的会员,对他们进行提醒或促销,使他们通过消费达到标准。一旦实现了首次兑换,客户在本公司进行再次消费兑换就比在其他公司进行兑换要容易许多,在一定程度上等于提高了转移的成本。
- 交叉销售:通过发行联名卡等与非航空类企业的合作,使客户在其他企业的消费过程中获得本公司的积分,增强与公司的联系,提高他们的忠诚度。
博客主页:https://www.cnblogs.com/p1ng/
欢迎转载,转载请注明出处。
出错之处,敬请交流、雅正!
创作不易,您的 " 推荐 " 和 " 关注 " ,是给我最大的鼓励!
基于R语言的航空公司客户价值分析的更多相关文章
- Python数据挖掘-航空公司客户价值分析
出处:http://www.ithao123.cn/content-11127869.html 航空公司客户价值分析 目标:企业针对不同价值的客户制定个性化的服务,将有限的资源集中于高价值客户. 1. ...
- 概率图模型 基于R语言 这本书中的第一个R语言程序
概率图模型 基于R语言 这本书中的第一个R语言程序 prior <- c(working =0.99,broken =0.01) likelihood <- rbind(working = ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- 基于R语言的结构方程:lavaan简明教程 [中文翻译版]
lavaan简明教程 [中文翻译版] 译者注:此文档原作者为比利时Ghent大学的Yves Rosseel博士,lavaan亦为其开发,完全开源.免费.我在学习的时候顺手翻译了一下,向Yves的开源精 ...
- 【转】基于R语言构建的电影评分预测模型
一,前提准备 1.R语言包:ggplot2包(绘图),recommenderlab包,reshape包(数据处理) 2.获取数据:大家可以在明尼苏达州大学的社会化计算研 ...
- 航空公司客户价值分析(KMeans聚类)
PS.图片可能不清楚,代码 数据集都在 https://github.com/xubin97/Data-Mining_exp1 项目介绍: 本案例的目标是客户价值识别,通过航空公司客户数据识别不同价值 ...
- 中文分词实践(基于R语言)
背景:分析用户在世界杯期间讨论最多的话题. 思路:把用户关于世界杯的帖子拉下来.然后做中文分词+词频统计,最后将统计结果简单做个标签云.效果例如以下: 兴许:中文分词是中文信息处理的基础.分词之后.事 ...
随机推荐
- scheduler_default_filters 详解
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步: 通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute) 通过权 ...
- 彻底解决Python编码问题
1. 基本概念 字符集(Character set) 解释:文字和符合的总称 常见字符集: Unicode字符集 ASCII字符集(Unicode子集) GB2312字符集 编码方法(Encoding ...
- [nodejs] 同步/异步创建多层目录
背景 有时项目里需要同时创建多层目录的功能,但低版本的nodejs并没有提供快捷的api 尽管在v10.12.0版本 mkdir() 第二个参数支持recursive 参数,为true时能递归创建,但 ...
- Django中MySQL事务的使用
Django中事物的使用 from django.db import transaction @transaction.atomic通过transaction的@transaction.atomic装 ...
- ajax---post跨域思路
ajax跨域需要加的代码 header("Access-Control-Allow-Methods:GET,POST");
- ansible的剧本play(四)
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAA68AAAETCAYAAADZDzDOAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjw
- The new SFCB broker fails to start with a SSL-related error: Failure setting ECDH curve name (secp22
# openssl ecparam -list_curves secp384r1 : NIST/SECG curve over a 384 bit prime field secp521r1 : NI ...
- 点击 QTableView,触发事件
Here is an example of how you can get a table cell's text when clicking on it. Suppose a QTableView ...
- VC++ QT 数组的初始化
数组有时会初始化为0. 但加了一个 QThread 的派生类对象之后,数组就不再被初始化为0了. 所以对于数组还是要手动初始化,否则可能产生无法预料的现象.
- opencv-2-VS2017与QT显示图像
opencv-2-VS2017与QT显示图像 opencvqtVSC++ 目的 使用 VS 构建第一个 opencv 程序 使用 QT 构建 第一个 opencv 程序 VS 导入 QT 程序 开始 ...