【HBase】底层原理
系统架构
在文章【HBase】基本介绍和基础架构中已经有简单介绍
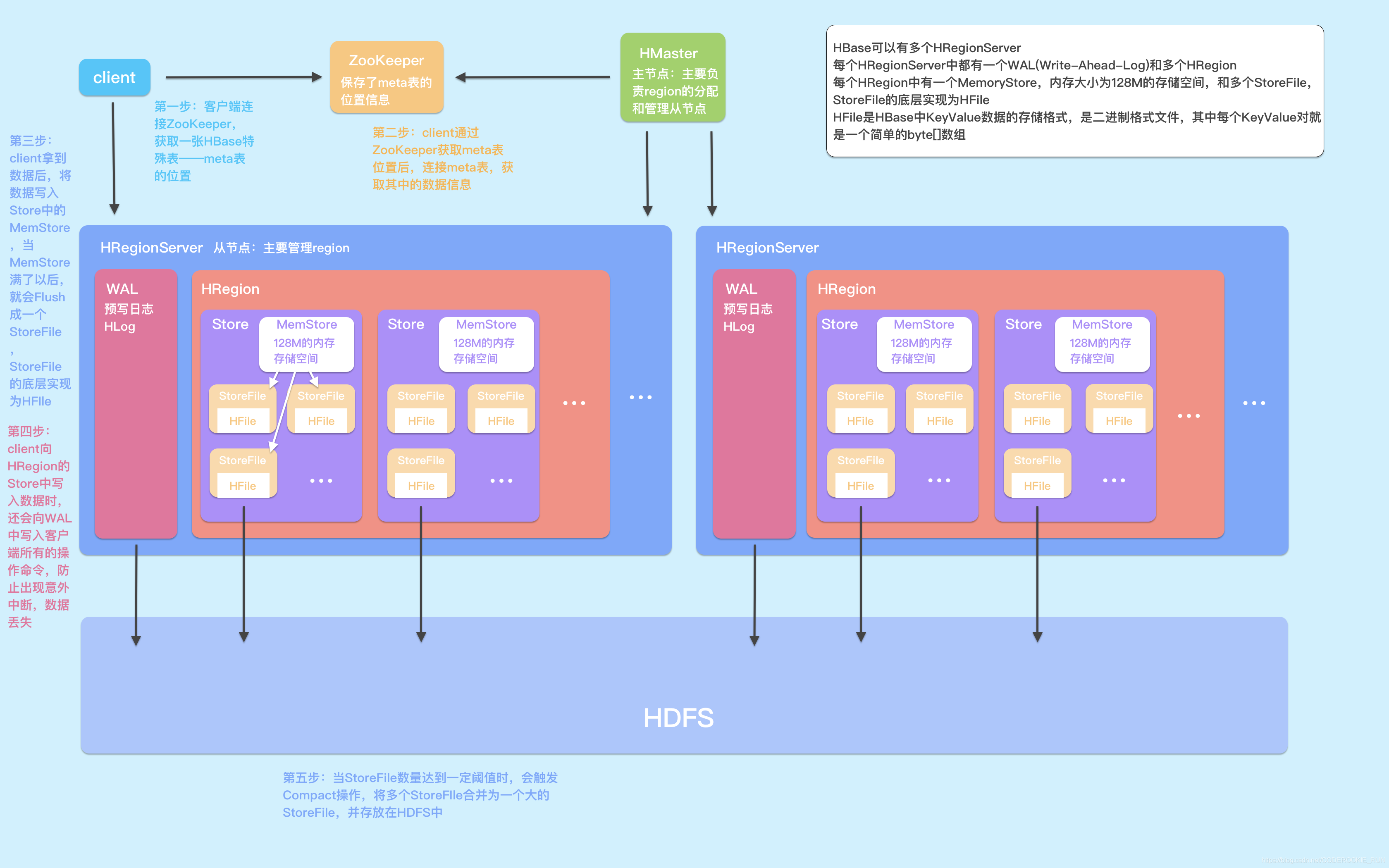
Client —— 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息。
Zookeeper:
1.保证任何时候,集群中只有一个master
2.存贮所有Region的寻址入口----root表在哪台服务器上。
3.实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4.存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master:
1.为Region server分配region
2.负责region server的负载均衡
3.发现失效的region server并重新分配其上的region
4.HDFS上的垃圾文件回收
5.处理schema更新请求
Region Server:
1.Region server维护Master分配给它的region,处理对这些region的IO请求
2.Region server负责切分在运行过程中变得过大的region
client访问HBase数据的过程中并不需要HMaster的参与,是直接通过ZooKeeper读取HRegionServer中Meta表存放的HRegion位置
表数据模型
基本介绍在【HBase】表模型和基本操作介绍
注意:
1.列族的访问控制、磁盘和内存的使用统计都是在列族层面进行,一般一张表不要设置太多列族,因为列族越多,读取一行数据时所要参与IO、搜寻的文件就越多
2.每条数据默认3个版本号
物理存储

1.Table中所有行都按照rowKey的字典顺序排列,并且在行的方向上分割为多个HRegion
2.HRegion是HBase中分布式存储和负载均衡的最小单元,不同的HRegion可以分布在不同的HRegionServer上,但同一个HRegion不会拆分到不同的HRegionServer
3.HRegion由多个Store组成,每个Store保存一个列族(Column Family)
4.HFile是一种文件存储格式,类似于ORC、Parquet
meta表的数据信息
ROW COLUMN+CELL
hbase:namespace,,1557280798528. column=info:regioninfo, timestamp=1557280800325, value={ENCODED => 56c88e849283c869e74095d5
56c88e849283c869e74095d5bf616b4 bf616b49, NAME => 'hbase:namespace,,1557280798528.56c88e849283c869e74095d5bf616b49.', START
9. KEY => '', ENDKEY => ''}
hbase:namespace,,1557280798528. column=info:seqnumDuringOpen, timestamp=1557280800325, value=\x00\x00\x00\x00\x00\x00\x00\x
56c88e849283c869e74095d5bf616b4 02
9.
hbase:namespace,,1557280798528. column=info:server, timestamp=1557280800325, value=node02.hadoop.com:60020
56c88e849283c869e74095d5bf616b4
9.
hbase:namespace,,1557280798528. column=info:serverstartcode, timestamp=1557280800325, value=1557280788349
56c88e849283c869e74095d5bf616b4
9.
myuser,,1557285598626.9a6ee8080 column=info:regioninfo, timestamp=1557285599647, value={ENCODED => 9a6ee8080ee16457bb791a10
ee16457bb791a10cca6c498. cca6c498, NAME => 'myuser,,1557285598626.9a6ee8080ee16457bb791a10cca6c498.', STARTKEY => ''
, ENDKEY => ''}
myuser,,1557285598626.9a6ee8080 column=info:seqnumDuringOpen, timestamp=1557285599647, value=\x00\x00\x00\x00\x00\x00\x00\x
ee16457bb791a10cca6c498. 02
myuser,,1557285598626.9a6ee8080 column=info:server, timestamp=1557285599647, value=node02.hadoop.com:60020
ee16457bb791a10cca6c498.
myuser,,1557285598626.9a6ee8080 column=info:serverstartcode, timestamp=1557285599647, value=1557280788349
ee16457bb791a10cca6c498.
user,,1557283951792.5b54e4569a9 column=info:regioninfo, timestamp=1557284223555, value={ENCODED => 5b54e4569a9e7f541340077f
e7f541340077ff35c168f. f35c168f, NAME => 'user,,1557283951792.5b54e4569a9e7f541340077ff35c168f.', STARTKEY => '',
ENDKEY => ''}
user,,1557283951792.5b54e4569a9 column=info:seqnumDuringOpen, timestamp=1557284223555, value=\x00\x00\x00\x00\x00\x00\x00\x
e7f541340077ff35c168f. 05
user,,1557283951792.5b54e4569a9 column=info:server, timestamp=1557284223555, value=node01.hadoop.com:60020
e7f541340077ff35c168f.
user,,1557283951792.5b54e4569a9 column=info:serverstartcode, timestamp=1557284223555, value=1557280783177
e7f541340077ff35c168f.
3 row(s) in 0.0500 seconds
【HBase】底层原理的更多相关文章
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- 从HBase底层原理解析HBASE列族不能设计太多的原因?
在之前的文章<深入探讨HBASE>中,笔者详细介绍了: HBase基础知识(包括简介.表结构).系统架构.数据存储 WAL log和HBase中LSM树的应用 HBase寻址机制 mino ...
- HBase底层存储原理
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已! 首先HBase不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数 ...
- HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已!
理解HBase(一个开源的Google的BigTable实际应用)最大的困难是HBase的数据结构概念究竟是什么?首先HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.另一个不 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- HBASE工作原理
如上图所示:首先我们需要知道 HBase 的集群是通过 Zookeeper 来进行机器之前的协调,也就是说 HBase Master 与 Region Server 之间的关系是依赖 Zookeepe ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- (转)HBase 的原理和设计
转自:HBase的原理和设计 HBase架构:
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- 【T-SQL进阶】02.理解SQL查询的底层原理
本系列[T-SQL]主要是针对T-SQL的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础]04.表表达式 ...
随机推荐
- Ant概念
Ant是基于Java的.可以跨平台的项目编译和生成工具.
- python超实用的30 个简短的代码片段(二)
Python是目前最流行的语言之一,它在数据科学.机器学习.web开发.脚本编写.自动化方面被许多人广泛使用. 它的简单和易用性造就了它如此流行的原因. 如果你正在阅读本文,那么你或多或少已经使用过P ...
- Python - Python的基础知识结构,学习方法、难点和重点
[原创]转载请注明作者Johnthegreat和本文链接. 相信大家都知道,Python很容易学,有编程基础的人,最多两个星期就可以很愉快的撸Python的代码了,那么具体涉及的知识有哪些,下面为大家 ...
- Java IO 流 -- 设计模式:装饰设计模式
在java IO 流中我们经常看到这样的写法: ObjectOutputStream oos = new ObjectOutputStream( new BufferedOutputStream(ne ...
- 天池Docker学习赛笔记
容器的基本概念 什么是容器? 容器就是一个视图隔离.资源可限制.独立文件系统的进程集合.所谓"视图隔离"就是能够看到部分进程以及具有独立的主机名等:控制资源使用率则是可以对于内存大 ...
- Inno Setup 添加版权信息
[Setup]AppCopyright=Copyright (C) - My Company, Inc. 有以上一句,即可在右键 --> Property --> Details 里看见版 ...
- Spring boot 自定义banner
Spring Boot启动的时候会在命令行生成一个banner,其实这个banner是可以自己修改的,本文将会将会讲解如何修改这个banner. 首先我们需要将banner保存到一个文件中,网上有很多 ...
- CUBA:如何准备上线
"在我电脑上是好的呢!"现在看来,这句话更像是调侃开发人员的一个段子,但是"开发环境与生产环境"之间的矛盾依然存在.作为开发者,你需要记住,你写 ...
- OpenWrt-19.07.2 For HC5861(极路由3) /HiWiFi/Gee最新固件,极路由3刷openwrt
OpenWrt For HiWiFi(HC5861) 自编译精减固件,极路由3自用固件 HC5861-uboot.bin v19.07.2 下载 支持 NTFS 读写 支持 Wi-Fi 5G 驱动 默 ...
- 解决w3wp.exe占用CPU和内存问题
在WINDOWS2003+IIS6下,经常出现w3wp的内存占用不能及时释放,从而导致服务器响应速度很慢.可以做以下配置进行改善:1.在IIS中对每个网站进行单独的应用程序池配置.即互相之间不影响.2 ...