DPDK IP分片及重组库(学习笔记)
1 前置知识学习
1.1 MTU
MTU是最大传输单元( Maximum Transmission Unit)的缩写,指一个接口无需分片所能发送的数据包的最大字节数。
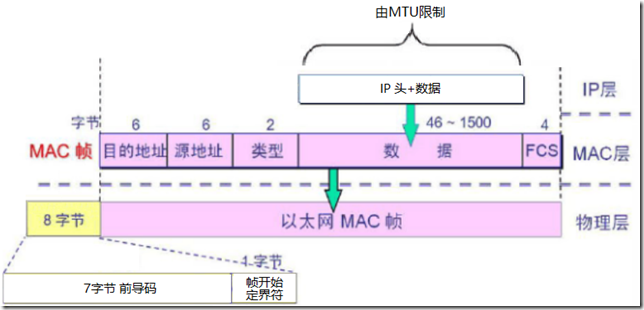
MTU范围在46 ~ 1500字节,默认一般都是1500。
1)MTU为1500时计算总长度
7字节前导码+1字节帧开始定界符+6字节的目的MAC+6字节的源MAC+2字节的帧类型+1500字节IP头及数据+4字节的 FCS = 1526字节。
2)为什么我们抓包得到的最大帧是1514字节?
当数据帧到达网卡时,在物理层上网卡要先去掉前导同步码和帧开始定界符,然后对帧进行CRC检验,如果帧校验和错,就丢弃此帧。如果校验和正确,就去掉FCS再交给“设备驱动程序”做进一步处理。这时我们的抓包软件才能抓到数据,因此,抓包软件抓到的是去掉前导码、帧开始定界符、FCS之外的数据,其最大值是 6+6+2+1500=1514。
3)如果MTU为46,不分片的最大以太帧长度
以太网规定,以太网帧数据域部分最小为46字节,也就是以太网帧最小是 6+6+2+46+4=64。抓包时要除去4个字节的FCS,因此,抓包看到是60字节。
当数据字段的长度小于46字节时,MAC层(由驱动程序)会在数据字段的后面填充数据,以满足数据帧长不小于64字节。
1.2 IP分片原理
IP分片发生在IP层,不仅源端主机会进行分片,中间的路由器也有可能分片,因为不同的网络的MTU是不一样的,如果传输路径上的某个网络的MTU比源端网络的MTU要小,路由器就可能对IP数据报再次进行分片。而分片数据的重组只会发生在目的端的IP层。
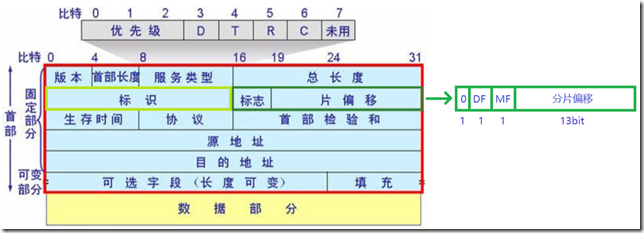
下图红色框里是我们熟悉的IP首部格式,与分片相关的是图中浅绿色+深绿色的方框(共32位)
1)浅绿框的“16字节标识”
同一个数据报的各个分片的标识是一样的,目的端会根据这个标识来判断IP分片是否属于同一个IP数据报。
2)深绿框的“标志”
占3个标志位。标志0:保留,必须为零;DF:不分段标记;MF:更多分片标记,,如果是最后一个分片,该标志位为0,否则为1。
3)深绿框的“片偏移”
它表示分片在原始数据中的偏移,这里的原始数据是IP层收到的TCP或UDP数据,不包含IP首部。需要注意的是,在分片的数据中,传输层的首部只会出现在第一个分片中,因为传输层的数据格式对IP层是透明的,传输层的首部只有在传输层才会有它的作用,IP层不知道也不需要保证在每个分片中都有传输层首部。所以,在网络上传输的数据包是有可能没有传输层首部的。
1.3 避免IP分片
在网络编程中,我们要避免出现IP分片。因为IP层是没有超时重传机制的,如果IP层对一个数据包进行了分片,只要有一个分片丢失了,只能依赖于传输层进行重传,结果是所有的分片都要重传一遍,会大大降低传输层传送数据的成功率,所以我们要避免IP分片。
1)UDP
我们需要在应用层去限制每个包的大小,一般不要超过1472字节(不考虑IP首部选项字段的情况),即以太网MTU(1500) - IP首部(20)- UDP首部(8)。
2)TCP(不用考虑IP分片)
应用层不需要考虑这个问题,因为传输层已经帮我们做了。在建立连接的三次握手的过程中,连接双方会相互通告MSS(Maximum Segment Size,最大报文段长度),MSS肯定是<=网络层的最大路径MTU,然后tcp数据封装成ip数据包通过网络层发送,当服务器端传输层接收到tcp数据之后进行tcp重组。TCP的ip数据包在传输过程中是不会发生分片的。
1.4 内核里的分片重组
linux实现分析:https://www.cnblogs.com/wanpengcoder/p/7604715.html
BSD:TCP/IP详解卷二,第十章
2 IP分片及重组库
IP分段和重组库实现IPv4和IPv6数据包的分段和重组。
2.1 数据包分片
数据包分段逻辑将输入的数据包划分为多个分段。 rte_ipv4_fragment_packet()和rte_ipv6_fragment_packet()函数均假定输入mbuf数据指向数据包IP报头的开头(即L2报头已被剥离)。为避免复制实际数据包的数据,使用了零拷贝技术(rte_pktmbuf_attach)。
对于每个片段,将创建两个新的mbuf:
- 直接mbuf,它包含新片段的L3头。
- 间接mbuf,它附加到带有原始数据包的mbuf。它的数据字段指向原始数据包数据的开头加上片段偏移量。
然后,将L3头部从原始mbuf复制到“直接”mbuf,并进行更新以反映新的分片状态。请注意,对于IPv4,不重新计算标头校验和,并将其设置为零。
最后,每个片段的“直接”和“间接” mbuf通过mbuf的next字段链接在一起,以组成新片段的数据包。
调用方可以明确指定应使用哪些内存池来分配“直接”和“间接” mbuf。
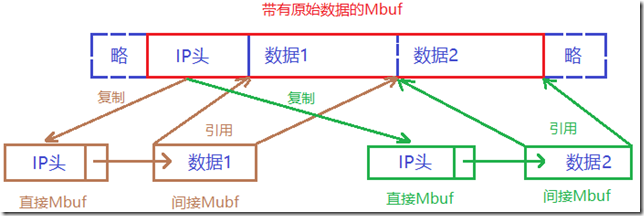
有关直接和间接mbuf的更多信息,请参考mbuf库的直接和间接缓冲区说明。
2.2 数据包重组
2.2.1 IP分片表
分片表中维护已经接收到的数据包片段的信息。
每个IP数据包均由有三个字段唯一标识:<源IP地址>,<目标IP地址>,<ID>。
请注意,片段表上的所有更新/查找操作都不是线程安全的。因此,如果不同的执行上下文(线程/进程)要同时访问同一张表时,必须提供一些外部同步机制。
每个表条目都可以保存有关数据包的信息,这些信息最多由RTE_LIBRTE_IP_FRAG_MAX(默认为4个)片段组成。
该代码示例演示了如何创建新的分片表:
frag_cycles = (rte_get_tsc_hz() + MS_PER_S - 1) / MS_PER_S * max_flow_ttl;
bucket_num = max_flow_num + max_flow_num / 4;
frag_tbl = rte_ip_frag_table_create(max_flow_num, bucket_entries, max_flow_num, frag_cycles, socket_id);
内部分片表是一个简单的哈希表。基本思想是使用两个哈希函数和主备两个hash桶,每个桶下有若干<bucket_entries>。这为每个键在哈希表中提供了2 * <bucket_entries>个可能的位置。当冲突发生并且所有2 * <bucket_entries>都被占用时,ip_frag_tbl_add()不会将现有键重新插入替代位置,而只会返回失败。(我的理解,这里是对hash库里cuckoo算法的简化说明)。
此外,表中驻留时间长于<max_cycles>的条目被视为无效,可以被新条目替换或删除。
请注意,重组需要分配大量的mbuf。在任何给定时间,最多可以将(2 * bucket_entries * RTE_LIBRTE_IP_FRAG_MAX * <每个数据包的最大mbufs个数>)存储在分片表中,以等待剩余的分片。
2.2.2 数据包重组
分片数据包的处理和重组是由rte_ipv4_frag_reassemble_packet()/ rte_ipv6_frag_reassemble_packet()函数完成的。它们要么返回一个指向“包含重组后数据包的有效mbuf“的指针,要么返回NULL(由于某种原因而无法完成据包重组数)。
这些功能包括:
- 在片段表中搜索数据包的<IPv4源地址,IPv4目标地址,数据包ID>。
- 如果找到该条目,则检查该条目是否已超时。如果是,则释放所有先前收到的片段,并从条目中删除有关它们的信息。
- 如果未找到带有此类密钥的条目,请尝试通过以下两种方法之一创建一个新的键:
1)占用一个空条目。
2)删除超时条目,释放与它相关联的mbufs,并在其中存储具有指定键的新条目。
- 使用新的片段信息更新条目,并检查包是否可以重新组合(包的条目包含所有片段)。
1)如果是,则重新组合数据包,将表的条目标记为空,然后将重新组合的mbuf返回给调用方。
2)如果否,则将NULL返回给调用方。
如果在数据包处理的任何阶段遇到错误(例如:无法将新条目插入分片表或无效/超时的片段),则该函数将释放所有与数据包分片相关的信息,标记表条目为无效,并将NULL返回给调用者。
2.2.3 调试日志记录和统计信息收集
RTE_LIBRTE_IP_FRAG_TBL_STAT配置宏控制分片表的统计信息收集。默认情况下不启用此宏。
RTE_LIBRTE_IP_FRAG_DEBUG控制IP分片处理和重组的调试日志记录。默认情况下禁用此宏。请注意,虽然日志记录包含许多详细信息,但它减慢了数据包处理的速度,并可能导致许多数据包的丢失。
参考:
DPDK官方编程指南:http://doc.dpdk.org/guides-20.02/prog_guide/ip_fragment_reassembly_lib.html
DPDK IP分片及重组库(学习笔记)的更多相关文章
- numpy, matplotlib库学习笔记
Numpy库学习笔记: 1.array() 创建数组或者转化数组 例如,把列表转化为数组 >>>Np.array([1,2,3,4,5]) Array([1,2,3,4,5]) ...
- IP2——IP地址和子网划分学习笔记之《子网掩码详解》
2018-05-04 16:21:21 在学习掌握了前面的<进制计数><IP地址详解>这两部分知识后,要学习子网划分,首先就要必须知道子网掩码,只有掌握了子网掩码这部分内容 ...
- IP地址和子网划分学习笔记之《IP地址详解》
2018-05-03 18:47:37 在学习IP地址和子网划分前,必须对进制计数有一定了解,尤其是二进制和十进制之间的相互转换,对于我们掌握IP地址和子网的划分非常有帮助,可参看如下目录详文. ...
- muduo网络库学习笔记(五) 链接器Connector与监听器Acceptor
目录 muduo网络库学习笔记(五) 链接器Connector与监听器Acceptor Connector 系统函数connect 处理非阻塞connect的步骤: Connetor时序图 Accep ...
- muduo网络库学习笔记(四) 通过eventfd实现的事件通知机制
目录 muduo网络库学习笔记(四) 通过eventfd实现的事件通知机制 eventfd的使用 eventfd系统函数 使用示例 EventLoop对eventfd的封装 工作时序 runInLoo ...
- muduo网络库学习笔记(三)TimerQueue定时器队列
目录 muduo网络库学习笔记(三)TimerQueue定时器队列 Linux中的时间函数 timerfd简单使用介绍 timerfd示例 muduo中对timerfd的封装 TimerQueue的结 ...
- IP地址和子网划分学习笔记之《预备知识:进制计数》
一.序:IP地址和子网划分学习笔记开篇 只要记住你的名字,不管你在世界的哪个地方,我一定会去见你.——新海诚 电影<你的名字> 在我们的日常生活中,每个人的名字对应一个唯一的身(敏)份(感 ...
- C++STL标准库学习笔记(三)multiset
C++STL标准库学习笔记(三)multiset STL中的平衡二叉树数据结构 前言: 在这个笔记中,我把大多数代码都加了注释,我的一些想法和注解用蓝色字体标记了出来,重点和需要关注的地方用红色字体标 ...
- 【python】numpy库和matplotlib库学习笔记
Numpy库 numpy:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成,并可与C++/Fortran语言无缝结合.树莓派Python v3默 ...
随机推荐
- php算--------法
<?php //冒泡排序:两两交换数值,最小的值在最左边,就如最轻的气泡在最上边.对整列数两两交换一次//最小的数在最左边,每次都能得一个在剩下的数中的最小 的数//“冒”出来的数组成一个有序区 ...
- 微软的 Sysinternals 系统管理工具包,例如可找出自动启动的流氓软件
作者:Kenny链接:https://www.zhihu.com/question/52157612/answer/153886419来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- Redis持久化存储(三)
redis高级特性-发布订阅消息服务功能 Pub/Sub 订阅,取消订阅和发布实现了发布/订阅消息范式(引自wikipedia),发送者(发布者)不是计划发送消息给特定的接收者(订阅者).而是发布的消 ...
- (转)SQLite数据库的加密
1.创建空的SQLite数据库. //数据库名的后缀你可以直接指定,甚至没有后缀都可以 //方法一:创建一个空sqlite数据库,用IO的方式 FileStream fs = File.Create( ...
- Linux网络服务第二章DHCP原理与配置
1.笔记 服务端端口:67 客户端端口:68 dhcliemt -r:释放IP地址 dhcliemt -d:重新获取IP地址 :.,$ s/190.168.200 / 192.168.100 /g 从 ...
- 多线程并行请求问题及SplashActivity预加载问题解决方案
1. 问题描述(一): 现有3个线程thread1, thread2, thread3.这3个线程是并发执行的,当着3个线程都执行完成以后,需要执行一个finish()事件. 1.1 实现方法: /* ...
- JavaScript实现折半查找(二分查找)
一.问题描述: 在一个升序数组中,使用折半查找得到要查询的值的索引位置.如: var a=[1,2,3,4,5,6,7,8,9]; search(a,3);//返回2 search(a,1);//左边 ...
- TensorRT入门
本文转载于:子棐之GPGPU 的 TensorRT系列入门篇 学习一下加深印象 Why TensorRT 训练对于深度学习来说是为了获得一个性能优异的模型,其主要的关注点在与模型的准确度.精度等指标. ...
- csp-j2019游记
我一pj蒟蒻这点水平还来写游记? 算了,毕竟是第一次,记录一下吧 noip->csp 话说我跟竞赛是不是天生八字不合啊...... 小学的时候学小奥,等我开始报名比赛,当时似乎所有竞赛都被叫停了 ...
- CF1324D Pair of Topics
好像题解里都是树状数组(起码我翻到的是 说一种cdq分治的(这应该算是cdq分治了 用cdq比较简单,所以可以作为一个练手题 cdq分治其实是一种模糊的思想,处理\([l,r]\)区间内,有多少\(( ...