Java基础知识面试题及答案-整理
1.String类可以被继承吗?
不能。String类在声明中使用final关键字修饰符。使用final关键字修饰的类无法被继承。
Java语言的开发者为什么要将String类定义为final类呢?
•因为当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多的堆空间,因为不懂的字符串变量都指向池中的同一个字符串。如果字符串是可变的,那么字符串的驻留将不可能实现,因为这样的话,
如果变量改变了它的值,那么其他指向这个值的变量也会一起改变。如果字符串是可变的那边会引起很严重的安全问题。
•因为字符串是不可变的,所以是多线程安全的。同一个字符串实例可以可以被多个线程共享。这样便不用因为线程安全问题而使用同步。
•因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串中的处理速度要快于其他的键对象。这就是HashMap中的键往往都使用字符串。
2.final修饰符在Java中有什么用?
•final修饰的变量叫做常量,常量必须初始化,初始化后的值不能被修改。
•final修饰的方法不能被重载也不能被重写。
•final修饰的类叫最终类,该类不能被继承。
3.JDK和JRE有什么区别?
JDK:Java Development Kit的简称,Java开发工具包,包含Java开发环境和运行环境。
JRE:Java Runtime Enviroment的简称,Java运行环境,为Java的运行提供了所需的环境。
4.==和equals的区别是什么?
•==对于基本数据类型和引用类型的作用效果是不同,对于基本数据类型比较的值是否相等,对于引用类型比较的应用是否相等。
•equals默认情况先比较的引用是否相等,只是很多类重写了Object类的equals方法,比如String,Integer把equals方法变成了比较的值是否相等,所以一般情况下equals比较的是值是否相等。
5.&和&&的区别?
&和&&在程序中最终的运算结果是一致的,区别在于:
•&运算符是:逻辑与,&不管左边表达式的结果是true还是false,右边的表达式都一定会执行;&运算符还可以使用在二进制位运算上。
•&&运算符是:短路与,&&运算符当左边的表达式结果是false时,右边的表达式不执行,存在短路现象。
6.重载(overload)和重写(override)的区别?
方法的重载和重写都是实现多态的方式,区别在于:
•重载实现的是编译时的多态性;重载发生在一个类中,同名的方法如果有不同的参数列表(参数个数,参数类型,顺序不同)则视为重载。
•重载实现的是运行时的多态性;重写发生在子类与父类之间,重写要求子类重写父类的方法后与父类重写的方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。
方法重写的规则:
•参数列表、方法名、返回值类型必须完全一致;
•构造方法不能被重写;
•声明为 final 的方法不能被重写;
•声明为 static 的方法不存在重写(重写和多态联合才有意义);
•访问权限不能比父类更低;
•重写之后的方法不能抛出更宽泛的异常;
7.为什么方法不能根据返回类型来区分重载?
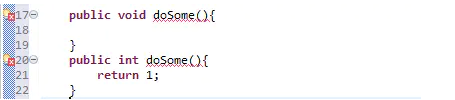
String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的 String 对象,再将指针指向新的 String 对象,而 StringBuffer 、 StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
StringBuffer 和 StringBuilder 最大的区别在于,StringBuffer 是线程安全的,而 StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于 StringBuffer,所以在单线程环境下推荐使用 StringBuilder,多线程环境下推荐使用 StringBuffer。
14.Java中IO流分为几种?
按功能来分:输入流(input),输出流(outpu)。
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
16.普通类和抽象类有什么区别?
•普通类不能包含抽象方法,抽象类可以包含抽象方法。
•普通类可以直接实例化,而抽象类不能被直接实例化。
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。下个问题可能是关于HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?” 从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?” 面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历链表直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:“你了解重新调整HashMap大小存在什么问题吗?”你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?:)
热心的读者贡献了更多的关于HashMap的问题:
1.为什么String, Interger这样的wrapper类适合作为键? String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
2.我们可以使用自定义的对象作为键吗? 这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
3.我们可以使用CocurrentHashMap来代替Hashtable吗?这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
25.http和https的区别?
•https协议需要到CA (Certificate Authority,证书颁发机构)申请证书,一般免费证书较少,因而需要一定费用。(原来网易官网是http,而网易邮箱是https。)
•http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
•http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
•http的连接很简单,是无状态的。Https协议是由SSL+Http协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。(无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。)。
算法的性能分析是算法设计中非常重要的方面,要想编写出能高效运行的程序,我们就需要考虑到算法的效率。
算法的效率主要由以下两个复杂度来评估:
时间复杂度:评估执行程序所需的时间。可以估算出程序对处理器的使用程度。算法的时间复杂度一般是问题规模的函数,通常用T=T(n)表示,其中,n表示问题的规模,即算法所处理的数据量。T表示算法所用时间。
算法的执行时间=该算法所有语句执行次数(包括重复执行次数)* 执行每条语句所花费时间总和。由于每条语句的执行时间是cpu速度决定的,对计算机而言是常数,因此可以忽略不计,只考虑语句的执行次数(频率或频度)。为了进一步简化计算,可以只用算法中某条重要语句(执行时间最长的语句)的执行频度。换句话说就是时间复杂度是主要语句频度的倍数。
备注:一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
空间复杂度:评估执行程序所需的存储空间。可以估算出程序对计算机内存的使用程度。不包括算法程序代码和所处理的数据本身所占空间部分。通常用所使用额外空间的字节数表示。其算法比较简单,记为S=S(n),其中,n表示问题规模。
设计算法时,一般是要先考虑系统环境,然后权衡时间复杂度和空间复杂度,选取一个平衡点。不过,时间复杂度要比空间复杂度更容易产生问题,因此算法研究的主要也是时间复杂度,不特别说明的情况下,复杂度就是指时间复杂度。
评价算法时间复杂度大小需要考虑的因素:
1,计算机硬件系统的运行速度。
2,所使用的软件环境。
3,算法本身的策略,采用不同的存储结构和不同的算法过程,是影响时间复杂度的本质原因之一。
4,所处理的数据量多少。
算法性能的评价方法:
1,事后统计法。
2,预先计算估算法。
1>精确计算法
2>近似估算法
这里我介绍数据结构最常用的方法,也就是第二种的第二类。
T(n)=O(f(n));S(n)=O(g(n))
其中,f(n)和g(n)是一个已知的函数,作为计较的尺度。
通常的比较尺度有:
O(1)称为常量级,算法的时间复杂度是一个常数。
O(n)称为线性级,时间复杂度是数据量n的线性函数。
O(n²)称为平方级,与数据量n的二次多项式函数属于同一数量级。
O(n³)称为立方级,是n的三次多项式函数。
O(logn)称为对数级,是n的对数函数。
O(nlogn)称为介于线性级和平方级之间的一种数量级
O(2ⁿ)称为指数级,与数据量n的指数函数是一个数量级。
O(n!)称为阶乘级,与数据量n的阶乘是一个数量级。
它们之间的关系是: O(1)<O(logn)<O(n)<O(nlogn)<O(n²)<O(n³)<O(2ⁿ)<O(n!)
如果觉得对你有帮助的话,可以下面扫一扫支持一下哦!

Java基础知识面试题及答案-整理的更多相关文章
- 最新Java基础面试题及答案整理
最近在备战面试的过程中,整理一下面试题.大多数题目都是自己手敲的,网上也有很多这样的总结.自己感觉总是很乱,所以花了很久把自己觉得重要的东西总结了一下. 面向对象和面向过程的区别 面向过程: 优 ...
- java基础知识面试题(41-95)
41.日期和时间:- 如何取得年月日.小时分钟秒?- 如何取得从1970年1月1日0时0分0秒到现在的毫秒数?- 如何取得某月的最后一天?- 如何格式化日期?答:问题1:创建java.util.Cal ...
- Java 基础知识面试题(2020 最新版)
Java面试总结汇总,整理了包括Java基础知识,集合容器,并发编程,JVM,常用开源框架Spring,MyBatis,数据库,中间件等,包含了作为一个Java工程师在面试中需要用到或者可能用到的绝大 ...
- Java基础面试题及答案(一)
Java 基础部分 1. JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境. JRE:Java ...
- Java基础知识面试题(最详细版)
刚刚经历过秋招,看了大量的面经,顺便将常见的Java常考知识点总结了一下,并根据被问到的频率大致做了一个标注.一颗星表示知识点需要了解,被问到的频率不高,面试时起码能说个差不多.两颗星表示被问到的频率 ...
- java基础知识面试题(1-40)
1.面向对象的特征有哪些方面?答:面向对象的特征主要有以下几个方面:- 抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面.抽象只关注对象有哪些属性和行为,并不关注这些 ...
- Java基础面试题及答案(六)
异常 74. throw 和 throws 的区别? throws是用来声明一个方法可能抛出的所有异常信息,throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理.而throw则是 ...
- Java基础知识面试题详解(2019年)
文章目录 1. 面向对象和面向过程的区别 2. Java 语言有哪些特点? 3. 关于 JVM JDK 和 JRE 最详细通俗的解答 JVM JDK 和 JRE 4. Oracle JDK 和 Ope ...
- Java基础面试题及答案(四)
反射 57. 什么是反射? 反射主要是指程序可以访问.检测和修改它本身状态或行为的一种能力 Java反射: 在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能 ...
随机推荐
- OpenCV学习(4)——动态结构
学习一个新知识,无外乎学习它本身和它的工具.OpenCV提供许多内置的结构及处理函数,非常值得学习. 内存存储 在OpenCV中,内存存储器是一个可以用来存储序列.数组和图像的动态增长的数据结构.它由 ...
- 2018 ICPC Pacific Northwest Regional Contest I-Inversions 题解
题目链接: 2018 ICPC Pacific Northwest Regional Contest - I-Inversions 题意 给出一个长度为\(n\)的序列,其中的数字介于0-k之间,为0 ...
- java中for循环和while循环,哪个更快?--一道面试题
for的 while的
- 题目分享D 二代目
题意:给定一个T条边的无向图,求S到E恰好经过N条边的最短路径 T≤100 N≤1000000 分析:(据说好像假期学长讲过) 首先很容易想到的是dp[i][j][k]表示从i到j经过k条边的最短路径 ...
- 支付宝小程序云开发(Serverless)
支付宝小程序云开发(Serverless) 博客说明 文章所涉及的资料来自互联网整理和个人总结,意在于个人学习和经验汇总,如有什么地方侵权,请联系本人删除,谢谢! 一.在支付宝账号里面开通小程序云服务 ...
- POJ3169(差分约束:转载)
转载自mengxiang000000传送门 Layout Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10278 Ac ...
- javaScript 添加和移除class类名的几种方法
添加类属性: // 一次只能设置一个类值,如果当前属性本身存在类值,会被替换 element.className = '类名'; /* * .setAttribute 用来设置自定义属性和值的 * 自 ...
- Mysql常用sql语句(八)- where 条件查询
测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html 前言 ...
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- 实现简单网页rtmp直播:nginx+ckplayer+linux
一.安装nginx 安装带有rtmp模块的nginx服务器(其它支持rtmp协议的流媒体服务器像easydarwin.srs等+Apache等web服务器也可以),此处使用nginx服务器,简单方便. ...