一文讲透Java序列化
本文目录
- 一、序列化是什么
- 二、为什么需要序列化
- 三、序列化怎么用
- 四、序列化深度探秘
- 4.1 为什么必须实现Serializable接口
- 4.2 被序列化对象的字段是引用时该怎么办
- 4.3 同一个对象会被序列化多次吗
- 4.4 只想序列化对象的部分字段该怎么办
- 4.5 被序列化对象具有继承关系该怎么办
- 五、serialVersionUID的作用及自动生成
- 六、序列化的缺点
- 七、参考文献
前言
Oracle 公司计划废除 Java 中的古董:序列化技术,因为它带来了许多严重的安全问题(如序列化存储安全、反序列化安全、传输安全等),据统计,至少有3分之1的漏洞是序列化带来的,这也是 1997 年诞生序列化技术的一个巨大错误。但是,序列化技术现在在 Java 应用中无处不在,特别是现在的持久化框架和分布式技术中,都需要利用序列化来传输对象,如:Hibernate、Mybatis、Java RMI、Dubbo等,即对象要存储或者传输都不可避免要用到序列化技术,所以删除序列化技术将是一个长期的计划。
你在实际工作中可能会很难有机会真正用到Java自带的序列化技术了,工业界一般也会选择一些更安全的对象编解码方案例如Google的Protobuf等。所以,对于Java序列化,我们不必再投入过多的精力学习,你花20分钟读完本文所掌握的知识,对于应付日常源码阅读中遇到的遗留的Java序列化技术应该是足够了。
一、序列化是什么
序列化机制允许将实现序列化的Java对象转换成字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以备以后重新恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
- 序列化:将一个Java对象写入IO流中
- 反序列化:从IO流中恢复该Java对象
本文中用序列化来简称整个序列化和反序列化机制。
二、为什么需要序列化
所有可能在网络上传输的对象的类都应该是可序列化的,否则程序将会出现异常,比如RMI(Remote Method Invoke,即远程方法调用,是JavaEE的基础)过程中的参数和返回值;所有需要保存到磁盘里的对象的类都必须可序列化,比如Web应用中需要保存到HttpSession或ServletContext属性的Java对象。
因为序列化是RMI过程的参数和返回值都必须实现的机制,而RMI又是Java EE技术的基础——所有的分布式应用常常需要跨平台、跨网络,所以要求所有传递的参数、返回值必须实现序列化。因此序列化机制是Java EE平台的基础。通常建议:程序创建的每个JavaBean类都实现Serializable。
三、序列化怎么用
如果一个类的对象需要序列化,那么在Java语法层面,这个类需要:
- 实现Serializable接口
- 使用ObjectOutputStream将对象输出到流,实现对象的序列化;使用ObjectInputStream从流中读取对象,实现对象的反序列化
下面我们通过代码示例来看看序列化最基本的用法。我们创建了Person类,其拥有两个基本类型的属性,并实现了Serializable接口。testSerialize方法用来测试序列化,testDeserialize方法用来测试反序列化。
import org.junit.Test;
import java.io.*;
public class SerializableTest {
@Test
public void testSerialize() {
Person one = new Person(12, 148.2);
Person two = new Person(35, 177.8);
try (ObjectOutputStream output =
new ObjectOutputStream(new FileOutputStream("Person.txt"))) {
output.writeObject(one);
output.writeObject(two);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDeserialize() {
try (ObjectInputStream input =
new ObjectInputStream(new FileInputStream("Person.txt"))) {
Person one = (Person) input.readObject();
Person two = (Person) input.readObject();
System.out.println(one);
System.out.println(two);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable {
int age;
double height;
public Person(int age, double height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
四、序列化深度探秘
4.1 为什么必须实现Serializable接口
如果某个类需要支持序列化功能,那么它必须实现Serializable接口,否则会报 java.io.NotSerializableException。Serializable接口是一个标志性接口(Marker Interface),也就是说,该接口并不包含任何具体的方法,是一个空接口,仅仅用来判断该类是否能够序列化。JDK8中Serializable接口的源码如下:
package java.io;
public interface Serializable {
}
在 ObjectOutputStream.java 的 writeObject0 方法中,我们确实可以看到对对象是否实现了 Serializable接口进行了验证(第15行),否则会抛出 NotSerializableException 异常(第22行)。
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
...
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}
4.2 被序列化对象的字段是引用时该怎么办
在第三部分“序列化怎么用”部分的示例中,Person类的字段全都是基本类型,我们知道基本类型其地址中直接存放的就是它的值,那如果是引用类型呢?引用类型其地址中存放的是指向堆内存中的一个地址,难道序列化时就是将这个地址进行了保存吗?显然,这是说不通的,因为对象的内存地址是可变的,在同一系统的不同运行时刻或者是不同系统中,对象的地址肯定是不同的,因此,序列化内存地址没有意义。
如果被序列化对象的字段是引用,那么要求该引用的类型也是可序列化实现了Serializable接口的,否则无法序列化。当对某个对象进行序列化时,系统会自动把该对象的所有Field依次进行序列化,如果某个Field引用到另一个对象,则被引用的对象也会被序列化;如果被引用的对象的Field也引用了其他对象,则被引用的对象也会被序列化,这种情况被称为递归序列化。
4.3 同一个对象会被序列化多次吗
如果对象A和对象B同时引用了对象C,那么,当序列化对象A和对象B时,对象C会被序列化两次吗?答案显然是不会。
要解释这个问题,就不得不说一下Java序列化的基本算法了:
- 所有序列化到二进制流的对象都有一个序列化编号
- 当程序试图序列化一个对象时,程序将先检查该对象是否已经被序列化过,只有该对象从未(在本次虚拟机中)被序列化过,系统才会将该对象转换成字节序列并赋予一个唯一的编号
- 如果某个对象已经序列化过,程序将只是直接输出其序列化编号,而不是再次重新序列化该对象
4.4 只想序列化对象的部分字段该怎么办
在一些特殊的场景下,如果一个类里包含的某些Field值是敏感信息,例如银行账户信息等,这时不希望系统将该Field值进行序列化;或者某个Field的类型是不可序列化的,因此不希望对该Field进行递归序列化,以避免引发java.io.NotSerializableException异常。
此时,我们就需要自定义序列化了。自定义序列化的常用方式有两种:
- 使用transient关键字
- 重写writeObject与readObject方法
我们先看第一种方式,使用transient关键字。transient关键字只能用于修饰Field,不可修饰Java程序中的其他成分。使用transient修饰的属性,java序列化时,会忽略掉此字段,所以反序列化出的对象,被transient修饰的属性是默认值。对于引用类型,值是null;基本类型,值是0;boolean类型,值是false。
下列代码中,我们把People的height字段设置为transient,在反序列化时,可观察到输出为默认值0.0。
import org.junit.Test;
import java.io.*;
public class SerializableTest {
@Test
public void testSerialize() {
Person one = new Person(12, 156.6);
Person two = new Person(16, 177.7);
try (ObjectOutputStream output =
new ObjectOutputStream(new FileOutputStream("Person.txt"))) {
output.writeObject(one);
output.writeObject(two);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDeserialize() {
try (ObjectInputStream input =
new ObjectInputStream(new FileInputStream("Person.txt"))) {
Person one = (Person) input.readObject();
Person two = (Person) input.readObject();
System.out.println(one);
System.out.println(two);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable{
protected int age;
protected transient double height;
public Person() {
}
public Person(int age, double height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
程序输出:
Person{age=12, height=0.0}
Person{age=16, height=0.0}
Process finished with exit code 0
使用transient关键字修饰Field虽然简单、方便,但被transient修饰的Field将被完全隔离在序列化机制之外,这样导致在反序列化恢复Java对象时无法取得该Field值。Java还提供了一种自定义序列化机制,通过这种自定义序列化机制可以让程序控制如何序列化各Field,甚至完全不序列化某些Field(与使用transient关键字的效果相同)。在序列化和反序列化过程中需要特殊处理的类应该提供如下特殊签名的方法,这些特殊的方法用以实现自定义序列化。
private void writeObject(java.io.ObjectOutputStream out)
throws IOException
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException;
private void readObjectNoData()
throws ObjectStreamException;
- writeObject()方法负责写入特定类的实例状态,以便相应的readObject()方法可以恢复它。通过重写该方法,程序员可以完全获得对序列化机制的控制,可以自主决定哪些Field需要序列化,需要怎样序列化。在默认情况下,该方法会调用out.defaultWriteObject来保存Java对象的各Field,从而可以实现序列化Java对象状态的目的。
- readObject()方法负责从流中读取并恢复对象Field,通过重写该方法,程序员可以完全获得对反序列化机制的控制,可以自主决定需要反序列化哪些Field,以及如何进行反序列化。在默认情况下,该方法会调用in.defaultReadObject来恢复Java对象的非静态和非瞬态Field。在通常情况下,readObject()方法与writeObject()方法对应,如果writeObject()方法中对Java对象的Field进行了一些处理,则应该在readObject()方法中对其Field进行相应的反处理,以便正确恢复该对象。
- 当序列化流不完整时,readObjectNoData()方法可以用来正确地初始化反序列化的对象。例如,接收方使用的反序列化类的版本不同于发送方,或者接收方版本扩展的类不是发送方版本扩展的类,或者序列化流被篡改时,系统都会调用readObjectNoData()方法来初始化反序列化的对象。
下面的示例代码中,我们在writeObject方法中对Person的字段进行了简单的加密处理,在readObject方法中对其进行了相应的解密。
import org.junit.Test;
import java.io.*;
public class SerializableTest {
@Test
public void testSerialize() {
Person one = new Person(12, 156.6);
Person two = new Person(16, 177.7);
try (ObjectOutputStream output =
new ObjectOutputStream(new FileOutputStream("Person.txt"))) {
output.writeObject(one);
output.writeObject(two);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDeserialize() {
try (ObjectInputStream input =
new ObjectInputStream(new FileInputStream("Person.txt"))) {
Person one = (Person) input.readObject();
Person two = (Person) input.readObject();
System.out.println(one);
System.out.println(two);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable{
protected int age;
protected double height;
public Person() {
}
public Person(int age, double height) {
this.age = age;
this.height = height;
}
private void writeObject(java.io.ObjectOutputStream out)
throws IOException {
System.out.println("Encryption!");
out.writeInt(age + 1);
out.writeDouble(height - 1);
}
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException {
System.out.println("Decryption!");
this.age = in.readInt() - 1;
this.height = in.readDouble() + 1;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
4.5 被序列化对象具有继承关系该怎么办
被序列化对象具有继承关系时无非就两种情况,第一,该类具有子类,第二,该类具有父类。
当该类实现了Serializable接口且具有子类时,根据官方文档中的说明,其子类天然具有可被序列化的属性,不需要显式实现Serializable接口;。
All subtypes of a serializable class are themselves serializable.
当该类实现了Serializable接口且具有父类时,,该类的父类需要实现Serializable接口吗?在JDK8中Serializable接口的官方文档中有这样一段话:
/**
* ......
*
* To allow subtypes of non-serializable classes to be serialized, the
* subtype may assume responsibility for saving and restoring the
* state of the supertype's public, protected, and (if accessible)
* package fields. The subtype may assume this responsibility only if
* the class it extends has an accessible no-arg constructor to
* initialize the class's state. It is an error to declare a class
* Serializable if this is not the case. The error will be detected at
* runtime.
*
* During deserialization, the fields of non-serializable classes will
* be initialized using the public or protected no-arg constructor of
* the class. A no-arg constructor must be accessible to the subclass
* that is serializable. The fields of serializable subclasses will
* be restored from the stream.
*/
阅读文档我们得知,为了使得不可序列化类的子类能够序列化,其子类必须担负起保存和恢复其超类的public、protected 和 package(if accessible)实例域的责任,且要求其父类必须有一个可访问的无参构造函数以使得在反序列化时能够初始化实例域。
我们写代码验证一下,如果父类中没有可访问的无参构造函数会发生什么,注意Person类中没有无参构造函数。
import org.junit.Test;
import java.io.*;
public class SerializableTest {
@Test
public void testSerialize() {
Student one = new Student(12, 156.6, "1234");
Student two = new Student(16, 177.7, "5678");
try (ObjectOutputStream output =
new ObjectOutputStream(new FileOutputStream("Student.txt"))) {
output.writeObject(one);
output.writeObject(two);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDeserialize() {
try (ObjectInputStream input =
new ObjectInputStream(new FileInputStream("Student.txt"))) {
Student one = (Student) input.readObject();
Student two = (Student) input.readObject();
System.out.println(one);
System.out.println(two);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person{
protected int age;
protected double height;
public Person(int age, double height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
class Student extends Person implements Serializable{
private String id;
public Student(int age, double height, String id) {
super(age, height);
this.id = id;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", height=" + height +
", id='" + id + '\'' +
'}';
}
}
程序输出产生异常:
java.io.InvalidClassException: Student; no valid constructor
at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:150)
at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:768)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1775)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:371)
at SerializableTest.testDeserialize(SerializableTest.java:26)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
... Process finished with exit code 0
当我们为Person类添加默认构造函数时:
class Person{
protected int age;
protected double height;
public Person() {
}
public Person(int age, double height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
程序输出如下,我们可观察到,父类中的字段都是默认值,只有子类中的字段得到了正确的序列化。出现这种情况的原因是子类并没有担负起序列化父类中字段的责任。
Student{age=0, height=0.0, id='1234'}
Student{age=0, height=0.0, id='5678'}
Process finished with exit code 0
为了解决上述问题,我们需要借助上一节中学到的知识,使用自定义的序列化方法writeObject和readObject来主动将父类中的字段进行序列化。
import org.junit.Test;
import java.io.*;
public class SerializableTest {
@Test
public void testSerialize() {
Student one = new Student(12, 156.6, "1234");
Student two = new Student(16, 177.7, "5678");
try (ObjectOutputStream output =
new ObjectOutputStream(new FileOutputStream("Studnet.txt"))) {
output.writeObject(one);
output.writeObject(two);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDeserialize() {
try (ObjectInputStream input =
new ObjectInputStream(new FileInputStream("Studnet.txt"))) {
Student one = (Student) input.readObject();
Student two = (Student) input.readObject();
System.out.println(one);
System.out.println(two);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person{
protected int age;
protected double height;
public Person() {
}
public Person(int age, double height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
class Student extends Person implements Serializable{
private String id;
public Student(int age, double height, String id) {
super(age, height);
this.id = id;
}
private void writeObject(java.io.ObjectOutputStream out)
throws IOException {
out.defaultWriteObject();
out.writeInt(age);
out.writeDouble(height);
}
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException {
in.defaultReadObject();
this.age = in.readInt();
this.height = in.readDouble();
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", height=" + height +
", id='" + id + '\'' +
'}';
}
}
程序输出如下,可以看到完全正确。
Student{age=12, height=156.6, id='1234'}
Student{age=16, height=177.7, id='5678'}
Process finished with exit code 0
五、serialVersionUID的作用及自动生成
我们知道,反序列化必须拥有class文件,但随着项目的升级,class文件也会升级,序列化怎么保证升级前后的兼容性呢?
java序列化提供了一个private static final long serialVersionUID 的序列化版本号,只有版本号相同,即使更改了序列化属性,对象也可以正确被反序列化回来。如果反序列化使用的class的版本号与序列化时使用的不一致,反序列化会报InvalidClassException异常。下面是JDK 8中ArrayList的源码中的serialVersionUID。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L; /**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
...
}
序列化版本号可自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,这样随着class的升级,就无法正确反序列化;不指定版本号另一个明显隐患是,不利于jvm间的移植,可能class文件没有更改,但不同jvm可能计算的规则不一样,这样也会导致无法反序列化。
什么情况下需要修改serialVersionUID呢?分三种情况。
- 如果只是修改了方法,反序列化不容影响,则无需修改版本号
- 如果只是修改了静态Field或瞬态Field,则反序列化不受任何影响
- 如果修改类时修改了非静态Field、非瞬态Field,则可能导致序列化版本不兼容。如果对象流中的对象和新类中包含同名的Field,而Field类型不同,则反序列化失败,类定义应该更新serialVersionUID Field值。如果只是新增了实例变量,则反序列化回来新增的是默认值;如果减少了实例变量,反序列化时会忽略掉减少的实例变量。
我们在日常编程实践中,一般会选择使用IDE来自动生成serialVersionUID,这样可以最大化地减少重复的可能性。对于IntelliJ IDEA,自动生成serialVersionUID有三步:
- 修改IDEA配置:File->Setting->Editor->Inspections->Serialization issues->Serializable class without ’serialVersionUID’
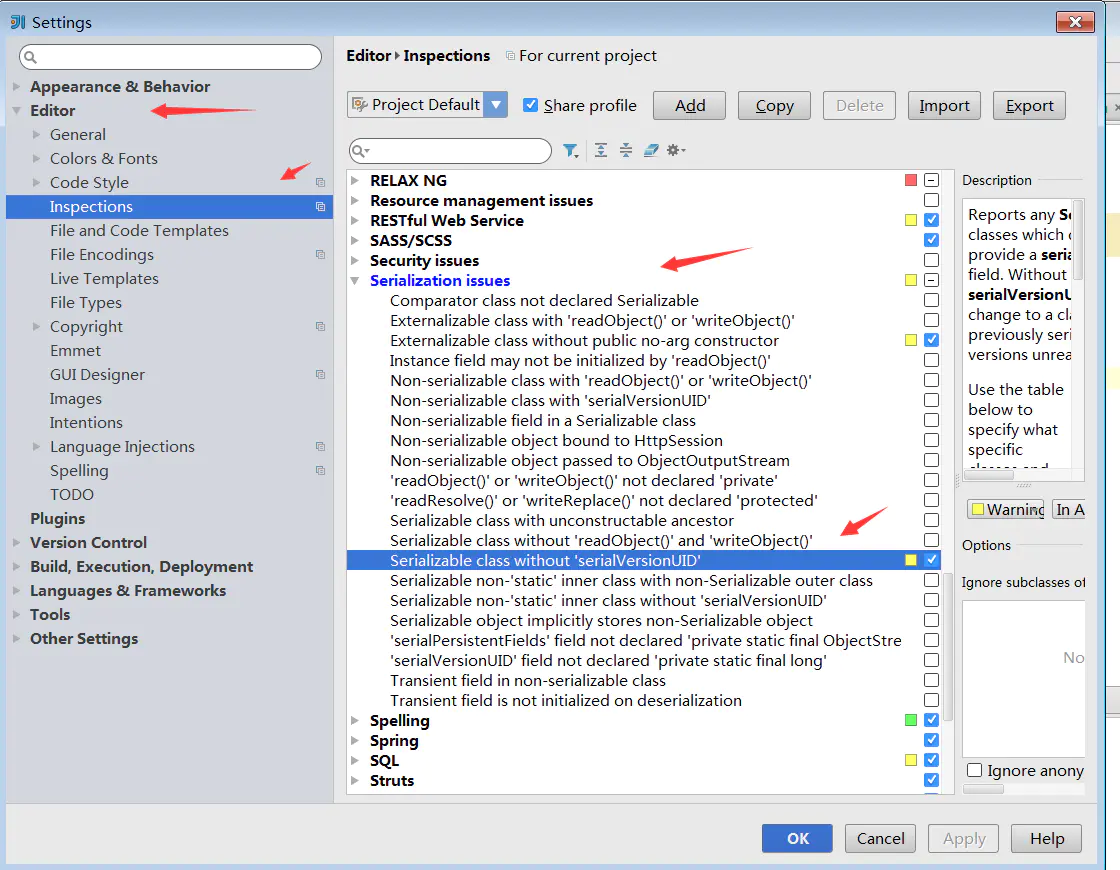
- 类实现Serializable接口
- 在类名上执行Alt+Enter,然后选择生成serialVersionUID即可
六、序列化的缺点
Java序列化存在四个致命缺点,导致其不适用于网络传输:
- 无法跨语言:在网络传输中,经常会有异构语言的进程的交互,但Java序列化技术是Java语言内部的私有协议,其他语言无法进行反序列化。目前所有流行的RPC框架都没有使用Java序列化作为编解码框架。
- 潜在风险高:不可信流的反序列化可能导致远程代码执行(RCE)、拒绝服务(DoS)和一系列其他攻击。
- 序列化后的码流太大
- 序列化的性能较低
在真正的生产环境中,一般会选择其它编解码框架,领先的跨平台结构化数据表示是 JSON 和 Protocol Buffers,也称为 protobuf。JSON 由 Douglas Crockford 设计用于浏览器与服务器通信,Protocol Buffers 由谷歌设计用于在其服务器之间存储和交换结构化数据。JSON 和 protobuf 之间最显著的区别是 JSON 是基于文本的,并且是人类可读的,而 protobuf 是二进制的,但效率更高。
七、参考文献
- 《疯狂Java讲义》第2版,李刚著,电子工业出版社
- 《Java核心技术》第10版,霍斯特曼等著,机械工业出版本
- 《Netty权威指南》第2版,李林锋著,电子工业出版社
- 《Effective Java》第2版,Joshua Bloch著,机械工业出版社
一文讲透Java序列化的更多相关文章
- 一文看懂Java序列化
一文看懂Java序列化 简介 Java实现 Serializable 最基本情况 类的成员为引用 同一对象多次序列化 子父类引用序列化 可自定义的可序列化 Externalizable:强制自定义序列 ...
- 一文看懂Java序列化之serialVersionUID
serialVersionUID适用于Java的序列化机制.简单来说,Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的.在进行反序列化时,JVM会把传来的字节流中的 ...
- 夯实Java基础系列22:一文读懂Java序列化和反序列化
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- 一文讲透Dubbo负载均衡之最小活跃数算法
本文是对于Dubbo负载均衡策略之一的最小活跃数算法的详细分析.文中所示源码,没有特别标注的地方均为2.6.0版本. 为什么没有用截止目前的最新的版本号2.7.4.1呢?因为2.6.0这个版本里面有两 ...
- 从零入门 Serverless | 一文讲透 Serverless Kubernetes 容器服务
作者 | 张维(贤维) 阿里云函数计算开发工程师 导读:Serverless Kubernetes 是以容器和 kubernetes 为基础的 Serverless 服务,它提供了一种简单易用.极致弹 ...
- 讲透JAVA Stream的collect用法与原理,远比你想象的更强大
大家好,又见面了. 在我前面的文章<吃透JAVA的Stream流操作,多年实践总结>中呢,对Stream的整体情况进行了细致全面的讲解,也大概介绍了下结果收集器Collectors的常见用 ...
- 一文讲透静电放电(ESD)保护(转发)
一直想给大家讲讲ESD的理论,很经典.但是由于理论性太强,任何理论都是一环套一环的,如果你不会画鸡蛋,注定了你就不会画大卫. 先来谈静电放电(ESD: Electrostatic Discharge) ...
- 一文讲透Cluster API的前世、今生与未来
作者:Luke Addison 原文链接:https://blog.jetstack.io/blog/cluster-api-past-present-and-future/ Cluster API是 ...
- 一文讲透为Power Automate for Desktop (PAD) 实现自定义模块 - 附完整代码
概述 Power Automate for Desktop (以下简称PAD)是微软推出的一款针对Windows桌面端的免费RPA(机器人流程自动化)工具,它目前默认会随着Windows 11安装,但 ...
随机推荐
- 相机测试camera报告的问题
AE问题 整体偏亮 整体偏暗 高光过爆 暗处过暗 对比度低/高 亮度: 关注暗处过暗 高光过爆 对比度: 关注头发,衣服 对比度低照片会有好像一层薄薄的,发蒙 关注植物,会有灰色的 AWB问题 偏 ...
- 树莓派ssh总掉线
之前入手了一个树莓派,但是远程ssh连接经常掉线,开始以为是电源不行,导致机器重启,后面加了一个显示器,观察了一段时间,发现机器并没有重启,应该是WiFi掉线了,在网上发现,树莓派如果一段网络没有流量 ...
- React:form
表单控件: input 文档在介绍控件之前,先提到了react组件自身的一个特点:状态由state掌控,改变组件状态只能用setState方法. 而在html的表单里,input.radio.chec ...
- Spring + Struts + Hibernate + Bootstrap-table 实现分页和增删改查
1.bootstrap界面效果图: 2.Teacher实体类 public class Teacher { private int id; private String name; private S ...
- Java 代码精简
Java 代码精简 利用语法 利用三元表达式 普通 String title; if (isMember(phone)) { title = "会员"; } else { titl ...
- 存储层技术:JDBC、Hibernate、Mybatis三者之间的比较学习
JDBC Hibernate Mybatis (Java DataBase Connnection) 是通过JAVA访问数据库 对JDBC的轻量封装 像操作对象操作数据库 对SQL的轻 ...
- java,netcore和nodejs api性能测试
一. 前言 作为有点经验的码农,现在退休在家带孩子.闲来无事,想对使用过的框架(如果写语言容易引战,php是世界上最好的语言)做一个性能测试. 二. 背景 由于毕业后刚开始接触的编程语言是C#, 从a ...
- 使用盒子定位布局时margin和padding使用
首先说的是区别: 如图所示,黄色padding,绿色margin,中间的content是内容,margin和padding的值是不计算在内容高宽的.这里补充的是在实际情况中边框宽度也是不计算在内的.这 ...
- PHP 连接数据库基础操作
<?phpheader('Content-type:text/html;charset=utf-8');//1建立 或者 关闭mysql服务器 @符号用于屏蔽错误信息$link=@mysql ...
- MySQL知识-MySQL不同版本多实例
一.不同版本多实例 0.软连接不同版本软件,修改环境变量 [root@db01 database]# ln -s mysql-5.6.46-linux-glibc2.12-x86_64 mysql ...