机器学习3- 一元线性回归+Python实现
1. 线性模型
给定 \(d\) 个属性描述的示例 \(\boldsymbol{x} = (x_1; x_2; ...; x_d)\),其中 \(x_i\) 为 \(\boldsymbol{x}\) 在第 \(i\) 个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即:
\]
使用向量形式为:
\]
其中 \(\boldsymbol{w} = (w_1;w_2;...;w_d)\),表达了各属性在预测中的重要性。
2. 线性回归
给定数据集 \(D = \lbrace(\boldsymbol{x}_1,{y}_1), (\boldsymbol{x}_2,{y}_2), ..., (\boldsymbol{x}_m,{y}_m)\rbrace\),其中 \(\boldsymbol{x}_i = (x_{i1}; x_{i2}; ...; x_{id})\),\(y_i \in \mathbb{R}\)。线性回归(linear regression)试图学得一个能尽可能准确地预测真实输出标记的线性模型,即:
\]
2.1 一元线性回归
先只考虑输入属性只有一个的情况,\(D = \lbrace({x}_1,{y}_1), ({x}_2,{y}_2), ..., ({x}_m,{y}_m)\rbrace\),\(x_i \in \mathbb{R}\)。对离散属性,若属性值存在序(order)关系,可通过连续化将其转化为连续值。
如”高度“属性的取值“高”、“中”、“低”,可转化为\(\{1.0, 0.5, 0.0\}\)。
若不存在序关系,则假定有 \(k\) 种可能的属性值,将其转化为 \(k\) 维向量。
如“瓜类”属性的取值有“冬瓜”、“西瓜”、“南瓜”,可转化为 \((0,0,1),(0,1,0),(1,0,0)\)。
线性回归试图学得:
\]
为使 \(f(x_i)\simeq y_i\),即:使 \(f(x)\) 与 \(y\) 之间的差别最小化。
考虑回归问题的常用性能度量——均方误差(亦称平方损失(square loss)),即让均方误差最小化:
(w^*,b^*) = \underset{(w,b)}{arg\ min}\sum_{i=1}^m(f(x_i)-y_i)^2 \\
= \underset{(w,b)}{arg\ min}\sum_{i=1}^m(y_i-wx_i-b)^2
\end{aligned}
\tag{2.3}
\]
\(w^*,b^*\) 表示 \(w\) 和 \(b\) 的解。
均方误差对应了欧几里得距离,简称欧氏距离(Euclidean distance)。
基于均方误差最小化来进行模型求解的方法称为最小二乘法(least square method)。在线性回归中,就是试图找到一条直线,使得所有样本到直线上的欧氏距离之和最小。
下面需要求解 \(w\) 和 \(b\) 使得 \(E_{(w,b)} = \sum\limits_{i=1}^m(y_i-wx_i-b)^2\) 最小化,该求解过程称为线性回归模型的最小二乘参数估计(parameter estimation)。
\(E_{(w,b)}\) 为关于 \(w\) 和 \(b\) 的凸函数,当它关于 \(w\) 和 \(b\) 的导数均为 \(0\) 时,得到 \(w\) 和 \(b\) 的最优解。将 \(E_{(w,b)}\) 分别对 \(w\) 和 \(b\) 求导数得:
\]
\]
令式子 (2.4) 和 (2.5) 为 \(0\) 得到 \(w\) 和 \(b\) 的最优解的闭式(closed-form)解:
\]
\]
其中 \(\overline{x} = \frac{1}{m}\sum\limits_{i=1}^m x_i\) 为 \(x\) 的均值。
其他解法:
\[方差\ var(x) = \frac{\sum\limits_{i=1}^m(x_i-\bar{x})^2}{m-1}
\]\[协方差\ cov(x,y) = \frac{\sum_\limits{i=1}^m (x_i-\overline{x})(y_i-\overline{y})}{n-1}
\]\[w = \frac{cov(x,y)}{var(x)} = \frac{\sum_\limits{i=1}^m (x_i-\overline{x})(y_i-\overline{y})}{\sum\limits_{i=1}^m (x_i-\overline{x})^2}
\]\[b = \bar{y} - w\bar{x}
\]
3. 一元线性回归的Python实现
现有如下训练数据,我们希望通过分析披萨的直径与价格的线性关系,来预测任一直径的披萨的价格。
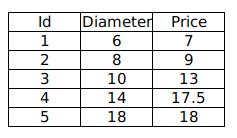
其中 Diameter 为披萨直径,单位为“英寸”;Price 为披萨价格,单位为“美元”。
3.1 使用 stikit-learn
3.1.1 导入必要模块
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
3.1.2 使用 Pandas 加载数据
pizza = pd.read_csv("pizza.csv", index_col='Id')
pizza.head() # 查看数据集的前5行

3.1.3 快速查看数据
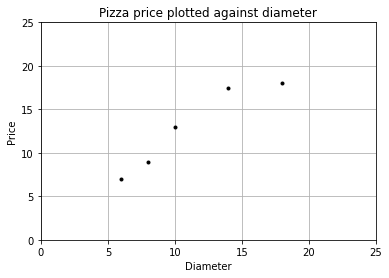
我们可以使用 matplotlib 画出数据的散点图,x 轴表示披萨直径,y 轴表示披萨价格。
def runplt():
plt.figure()
plt.title("Pizza price plotted against diameter")
plt.xlabel('Diameter')
plt.ylabel('Price')
plt.grid(True)
plt.xlim(0, 25)
plt.ylim(0, 25)
return plt
dia = pizza.loc[:,'Diameter'].values
price = pizza.loc[:,'Price'].values
print(dia)
print(price)
plt = runplt()
plt.plot(dia, price, 'k.')
plt.show()
[ 6 8 10 14 18]
[ 7. 9. 13. 17.5 18. ]
3.1.4 使用 stlearn 创建模型
model = LinearRegression() # 创建模型
X = dia.reshape((-1,1))
y = price
model.fit(X, y) # 拟合
X2 = [[0], [25]] # 取两个预测值
y2 = model.predict(X2) # 进行预测
print(y2) # 查看预测值
plt = runplt()
plt.plot(dia, price, 'k.')
plt.plot(X2, y2, 'g-') # 画出拟合曲线
plt.show()
[ 1.96551724 26.37284483]
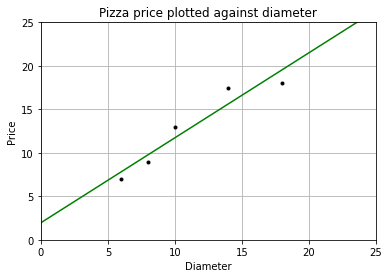
这里 fit()方法学得了一元线性回归模型 \(f(x) = wx+b\),这里 \(x\) 指披萨的直径,\(f(x)\) 为预测的披萨的价格。
fit() 的第一个参数 X 为 shape(样本个数,属性个数) 的数组或矩阵类型的参数,代表输入空间;
第二个参数 y 为 shape(样本个数,) 的数组类型的参数,代表输出空间。
3.1.5 模型评估
成本函数(cost function)也叫损失函数(lost function),用来定义模型与观测值的误差。
模型预测的价格和训练集数据的差异称为训练误差(training error)也称残差(residuals)。
plt = runplt()
plt.plot(dia, price, 'k.')
plt.plot(X2, y2, 'g-')
# 画出残差
yr = model.predict(X)
for index, x in enumerate(X):
plt.plot([x, x], [y[index], yr[index]], 'r-')
plt.show()
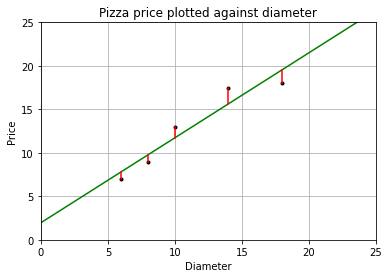
根据最小二乘法,要得到更高的性能,就是让均方误差最小化,而均方误差就是残差平方和的平均值。
print("均方误差为: %.2f" % np.mean((model.predict(X)-y) ** 2))
均方误差为: 1.75
3.2 手动实现
3.2.1 计算 w 和 b
\(w\) 和 \(b\) 的最优解的闭式(closed-form)解为:
\]
\]
其中 \(\overline{x} = \frac{1}{m}\sum\limits_{i=1}^m x_i\) 为 \(x\) 的均值。
或
\]
\]
\]
\]
下面使用 Python 计算 \(w\) 和 \(b\) 的值:
# 法一:
# w = np.sum(price * (dia - np.mean(dia))) / (np.sum(dia**2) - (1/dia.size) * (np.sum(dia))**2)
# b = (1 / dia.size) * np.sum(price - w * dia)
#法二:
variance = np.var(dia, ddof=1) # 计算方差,doff为贝塞尔(无偏估计)校正系数
covariance = np.cov(dia, price)[0][1] # 计算协方差
w = covariance / variance
b = np.mean(price) - w * np.mean(dia)
print("w = %f\nb = %f" % (w, b))
y_pred = w * dia + b
plt = runplt()
plt.plot(dia, price, 'k.') # 样本点
plt.plot(dia, y_pred, 'b-') # 手动求出的线性回归模型
plt.plot(X2, y2, 'g-.') # 使用LinearRegression.fit()求出的模型
plt.show()
w = 0.976293
b = 1.965517
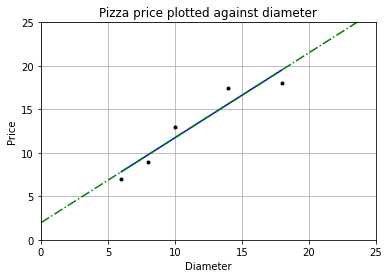
可以看到两条直线重合,我们求出的回归模型与使用库求出的回归模型相同。
3.2.2 功能封装
将上述代码封装成类:
class LinearRegression:
"""
拟合一元线性回归模型
Parameters
----------
x : shape 为(样本个数,)的 numpy.array
只有一个属性的数据集
y : shape 为(样本个数,)的 numpy.array
标记空间
Returns
-------
self : 返回 self 的实例.
"""
def __init__(self):
self.w = None
self.b = None
def fit(self, x, y):
variance = np.var(x, ddof=1) # 计算方差,doff为贝塞尔(无偏估计)校正系数
covariance = np.cov(x, y)[0][1] # 计算协方差
self.w = covariance / variance
self.b = np.mean(y) - w * np.mean(x)
# self.w = np.sum(y * (x - np.mean(x))) / (np.sum(x**2) - (1/x.size) * (np.sum(x))**2)
# self.b = (1 / x.size) * np.sum(y - self.w * x)
return self
def predict(self, x):
"""
使用该线性模型进行预测
Parameters
----------
x : 数值 或 shape 为(样本个数,)的 numpy.array
属性值
Returns
-------
C : 返回预测值
"""
return self.w * x + self.b
使用:
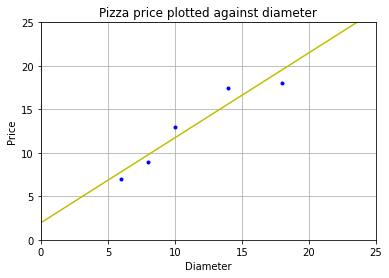
# 创建并拟合模型
model = LinearRegression()
model.fit(dia, price)
x2 = np.array([0, 25]) # 取两个预测值
y2 = model.predict(x2) # 进行预测
print(y2) # 查看预测值
runplt()
plt.plot(dia, price, 'b.')
plt.plot(x2, y2, 'y-') # 画出拟合
plt.show()
[ 1.96551724 26.37284483]
此文原创禁止转载,转载文章请联系博主并注明来源和出处,谢谢!
作者: Raina_RLN https://www.cnblogs.com/raina/
机器学习3- 一元线性回归+Python实现的更多相关文章
- Python实现——一元线性回归(梯度下降法)
2019/3/25 一元线性回归--梯度下降/最小二乘法_又名:一两位小数点的悲剧_ 感觉这个才是真正的重头戏,毕竟前两者都是更倾向于直接使用公式,而不是让计算机一步步去接近真相,而这个梯度下降就不一 ...
- 【机器学习】线性回归python实现
线性回归原理介绍 线性回归python实现 线性回归sklearn实现 这里使用python实现线性回归,没有使用sklearn等机器学习框架,目的是帮助理解算法的原理. 写了三个例子,分别是单变量的 ...
- 梯度下降法及一元线性回归的python实现
梯度下降法及一元线性回归的python实现 一.梯度下降法形象解释 设想我们处在一座山的半山腰的位置,现在我们需要找到一条最快的下山路径,请问应该怎么走?根据生活经验,我们会用一种十分贪心的策略,即在 ...
- 机器学习:单元线性回归(python简单实现)
文章简介 使用python简单实现机器学习中单元线性回归算法. 算法目的 该算法核心目的是为了求出假设函数h中多个theta的值,使得代入数据集合中的每个x,求得的h(x)与每个数据集合中的y的差值的 ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- machine learning 之 导论 一元线性回归
整理自Andrew Ng 的 machine learnig 课程 week1. 目录: 什么是机器学习 监督学习 非监督学习 一元线性回归 模型表示 损失函数 梯度下降算法 1.什么是机器学习 Ar ...
- [机器学习Lesson4]多元线性回归
1. 多元线性回归定义 多元线性回归也被称为多元线性回归. 我们现在介绍方程的符号,我们可以有任意数量的输入变量. 这些多个特征的假设函数的多变量形式如下: hθ(x)=θ0+θ1x1+θ2x2+θ3 ...
- 干货 | 请收下这份2018学习清单:150个最好的机器学习,NLP和Python教程
机器学习的发展可以追溯到1959年,有着丰富的历史.这个领域也正在以前所未有的速度进化.在之前的一篇文章中,我们讨论过为什么通用人工智能领域即将要爆发.有兴趣入坑ML的小伙伴不要拖延了,时不我待! 在 ...
- 机器学习1—简介及Python机器学习环境搭建
简介 前置声明:本专栏的所有文章皆为本人学习时所做笔记而整理成篇,转载需授权且需注明文章来源,禁止商业用途,仅供学习交流.(欢迎大家提供宝贵的意见,共同进步) 正文: 机器学习,顾名思义,就是研究计算 ...
随机推荐
- 记一次手机与PC同步开发Android项目
目录 -1 前言 0.0 流程简介 1.0 AS创建项目并上传GitHub 2.0 AIDE克隆GitHub项目 能力不足时曲线救国 > 3.0 termux编译AIDE目录下的项目文件 3.1 ...
- python 读取 execl 文件 之 xlrd 模块
1. 安装 xlrd模块 pip install xlrd 2. 读取文件内容 #!/usr/bin/env python3 import xlrd name = r"E:\excel\yo ...
- MySQL之单表多表查询
#1.单表查询 #单表查询语法 select <字段1,字段2....> from <表名> where <表达式> group by field 分组 havin ...
- 基于python openOPC的监控页面一
笔者涉猎的工业领域项目遇到一个需求,需要把底层设备(表记)的状态和运行数据集中放到一个监控画面进行展示,数据需要在界面端实时进行刷新,类似网友的例子,如下图(侵删) 数据需要实时主动刷新,笔者基于多年 ...
- 使用 Hexo 创建项目文档网站
当我们发布一个开源项目的时候,最重要的事情之一就是要创建项目文档.对使用项目的用户来说,文档是非常有必要的,通常我们可以使用下面这些方式来创建文档: GitHub Wiki:在 Github 上我们可 ...
- 基础JavaScript练习(二)总结
任务目的 学习与实践JavaScript的基本语法.语言特性 练习使用JavaScript实现简单的排序算法 任务描述 基于上一任务 限制输入的数字在10-100 队列元素数量最多限制为60个,当超过 ...
- 基于springcloud搭建项目-Feign篇(四)
上一篇已经写过ribbon客户端负载均衡的用法了,这篇主要是介绍feign的用法,首先我们必须了解feign是什么?能干嘛?怎么用? 这里简单介绍一下,然后进行代码测试 1.概述 Feign是一个声明 ...
- Spring、SpringMVC、SpringBoot、SpringCloud的区别和联系
简介 Spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的容器框架.Spring能够让我们编写出更简洁.易于管理.更易于测试的代码. SpringMVC是Spring的一个模块,一个we ...
- mac笔记本编译go-ethereum报错CoreServices/CoreServices.h' file not found
查看xcode是否安装: $ xcode-select --install xcode-select: error: command line tools are already installed, ...
- 【猫狗数据集】使用top1和top5准确率衡量模型
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...