Python Sklearn.metrics 简介及应用示例
Python Sklearn.metrics 简介及应用示例
利用Python进行各种机器学习算法的实现时,经常会用到sklearn(scikit-learn)这个模块/库。
无论利用机器学习算法进行回归、分类或者聚类时,评价指标,即检验机器学习模型效果的定量指标,都是一个不可避免且十分重要的问题。因此,结合scikit-learn主页上的介绍,以及网上大神整理的一些资料,对常用的评价指标及其实现、应用进行简单介绍。
一、 scikit-learn安装
网上教程很多,此处不再赘述,具体可以参照:
https://www.cnblogs.com/zhangqunshi/p/6646987.html
此外,如果安装了Anoconda,可以直接从Anoconda Navigator——Environment里面搜索添加。
pip install -U scikit-learn
二、 scikit-learn.metrics导入与调用
有两种方式导入:
方式一:
from sklearn.metrics import 评价指标函数名称
例如:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
调用方式为:直接使用函数名调用
计算均方误差mean squared error
mse = mean_squared_error(y_test, y_pre)
计算回归的决定系数R2
R2 = r2_score(y_test,y_pre)
方式二:
from sklearn import metrics
调用方式为:metrics.评价指标函数名称(parameter)
例如:
计算均方误差mean squared error
mse = metrics.mean_squared_error(y_test, y_pre)
计算回归的决定系数R2
R2 = metrics.r2_score(y_test,y_pre)
三、 scikit-learn.metrics里各种指标简介
简单介绍参见:
https://www.cnblogs.com/mdevelopment/p/9456486.html
详细介绍参见:
https://www.cnblogs.com/harvey888/p/6964741.html
官网介绍:
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics
转自第一个链接的内容,简单介绍内容如下:
回归指标
explained_variance_score(y_true, y_pred, sample_weight=None, multioutput=‘uniform_average’):回归方差(反应自变量与因变量之间的相关程度)
mean_absolute_error(y_true,y_pred,sample_weight=None,
multioutput=‘uniform_average’):
平均绝对误差
mean_squared_error(y_true, y_pred, sample_weight=None, multioutput=‘uniform_average’):均方差
median_absolute_error(y_true, y_pred) 中值绝对误差
r2_score(y_true, y_pred,sample_weight=None,multioutput=‘uniform_average’) :R平方值
分类指标
accuracy_score(y_true,y_pre) : 精度
auc(x, y, reorder=False) : ROC曲线下的面积;较大的AUC代表了较好的performance。
average_precision_score(y_true, y_score, average=‘macro’, sample_weight=None):根据预测得分计算平均精度(AP)
brier_score_loss(y_true, y_prob, sample_weight=None, pos_label=None):The smaller the Brier score, the better.
confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):通过计算混淆矩阵来评估分类的准确性 返回混淆矩阵
f1_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None): F1值
F1 = 2 * (precision * recall) / (precision + recall) precision(查准率)=TP/(TP+FP) recall(查全率)=TP/(TP+FN)
log_loss(y_true, y_pred, eps=1e-15, normalize=True, sample_weight=None, labels=None):对数损耗,又称逻辑损耗或交叉熵损耗
precision_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’,) :查准率或者精度; precision(查准率)=TP/(TP+FP)
recall_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None):查全率 ;recall(查全率)=TP/(TP+FN)
roc_auc_score(y_true, y_score, average=‘macro’, sample_weight=None):计算ROC曲线下的面积就是AUC的值,the larger the better
roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True);计算ROC曲线的横纵坐标值,TPR,FPR
TPR = TP/(TP+FN) = recall(真正例率,敏感度) FPR = FP/(FP+TN)(假正例率,1-特异性)
四、 一个应用实例
结合官网的案例,利用自己的数据,实现的一个应用实例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import ensemble
from sklearn import metrics
##############################################################################
# Load data
data = pd.read_csv('Data for train_0.003D.csv')
y = data.iloc[:,0]
X = data.iloc[:,1:]
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
##############################################################################
# Fit regression model
params = {'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
clf.fit(X_train, y_train)
y_pre = clf.predict(X_test)
# Calculate metrics
mse = metrics.mean_squared_error(y_test, y_pre)
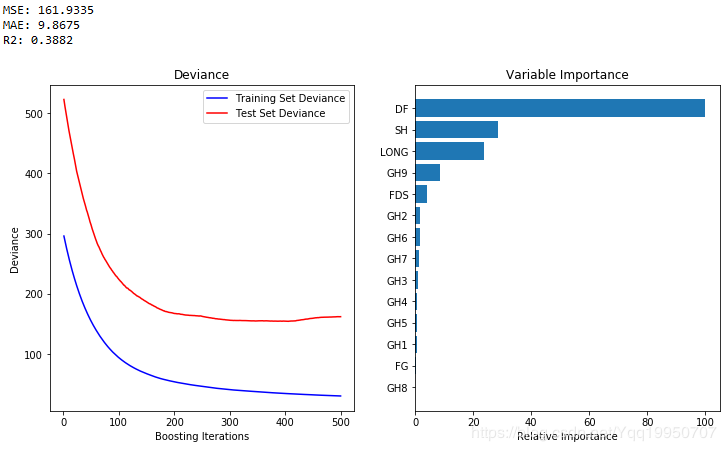
print("MSE: %.4f" % mse)
mae = metrics.mean_absolute_error(y_test, y_pre)
print("MAE: %.4f" % mae)
R2 = metrics.r2_score(y_test,y_pre)
print("R2: %.4f" % R2)
##############################################################################
# Plot training deviance
# compute test set deviance
test_score = np.zeros((params['n_estimators'],), dtype=np.float64)
for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, clf.train_score_, 'b-',
label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, test_score, 'r-',
label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
##############################################################################
# Plot feature importance
feature_importance = clf.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, X.columns[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()
Python Sklearn.metrics 简介及应用示例的更多相关文章
- 朴素贝叶斯算法源码分析及代码实战【python sklearn/spark ML】
一.简介 贝叶斯定理是关于随机事件A和事件B的条件概率的一个定理.通常在事件A发生的前提下事件B发生的概率,与在事件B发生的前提下事件A发生的概率是不一致的.然而,这两者之间有确定的关系,贝叶斯定理就 ...
- Python生态环境简介[转]
Python生态环境简介 作者: Mir Nazim 原文: Python Ecosystem - An Introduction 译者: dccrazyboy 原译: Python生态环境简介 当 ...
- (转)python生态环境简介
Python生态环境简介 作者: Mir Nazim 原文: Python Ecosystem - An Introduction 译者: dccrazyboy 原译: Python生态环境简介 当 ...
- python + sklearn ︱分类效果评估——acc、recall、F1、ROC、回归、距离
之前提到过聚类之后,聚类质量的评价: 聚类︱python实现 六大 分群质量评估指标(兰德系数.互信息.轮廓系数) R语言相关分类效果评估: R语言︱分类器的性能表现评价(混淆矩阵,准确率,召回率,F ...
- 『Python Kivy』官方乒乓球游戏示例解析
本篇文章用于对Kivy框架官方所给出的一个「乒乓球」小游戏的源码进行简单地解析.我会尽可能的将方方面面的内容都说清楚.在文章的最下方为官方所给出的这个小游戏的教程以及游戏源码. 由于篇幅所限,本文只简 ...
- Python 有序字典简介
Table of Contents 1. 有序字典-OrderedDict简介 1.1. 示例 1.2. 相等性 1.3. 注意 2. 参考资料 有序字典-OrderedDict简介 示例 有序字典和 ...
- 利用Python sklearn的SVM对AT&T人脸数据进行人脸识别
要求:使用10-fold交叉验证方法实现SVM的对人脸库识别,列出不同核函数参数对识别结果的影响,要求画对比曲线. 使用Python完成,主要参考文献[4],其中遇到不懂的功能函数一个一个的查官方文档 ...
- Python sklearn拆分训练集、测试集及预测导出评分 决策树
机器学习入门 (注:无基础可快速入门,想提高准确率还得多下功夫,文中各名词不做过多解释) Python语言.pandas包.sklearn包 建议在Jupyter环境操作 操作步骤 1.panda ...
- sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)
1 accuracy_score:分类准确率分数是指所有分类正确的百分比.分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型.常常误导初学 ...
随机推荐
- js图片轮换播放器
<!DOCTYPE html> <html> <head> <title></title> <meta charset="u ...
- vs2013设置不生成.sdf和ipch文件
转载:https://blog.csdn.net/sinat_23338865/article/details/53393760 使用VS2013建立解决方案时,会生成SolutionName.sdf ...
- 设计模式六大原则——开放封闭原则(OCP)
什么是开闭原则? 定义:是说软件实体(类.模块.函数等等)应该可以扩展,但是不可修改. 开闭原则主要体现在两个方面: 1.对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况. ...
- springBoot+MybatisPlus数据库字段使用驼峰命名法时报错
假如有个实体类: package com.jeff.entity; public class User { /** * 主键id */ private Integer id; /** * 登陆名 */ ...
- springBoot整合mybatis-plus关闭自动转换小驼峰命名规则
增加配置信息 mybatis-plus: configuration: map-underscore-to-camel-case: false
- hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, Hbase, Hive, ZooKeeper:
组件 节点 默认端口 配置 用途说明 HDFS DataNode 50010 dfs.datanode.address datanode服务端口,用于数据传输 HDFS DataNode 50075 ...
- PTA的Python练习题(六)
从 第3章-8 字符串逆序 开始 1. n = str(input()) n1=n[::-1] print(n1) 2. 不是很好做这道题,自己还是C语言的思维,网上几乎也找不到什么答案 s = in ...
- Node Sass does not yet support your current environment: Linux 64-bit with Unsupported runtime
环境: ubuntu18 webstorm vue项目 报错原因: 缺少相关依赖 解决方法: npm rebuild node-sass 还未解决: npm uninstall --save node ...
- 吴裕雄--天生自然TensorFlow2教程:全连接层
out = f(X@W + b) out = relut(X@W + b) import tensorflow as tf x = tf.random.normal([4, 784]) net = t ...
- CODE 大全网站整站源码分享(带数据库)
CODE 大全是一个偏向于 JavaEE.JavaWeb,WEB 前端,HTML5,数据库,系统运维,编程技术开发的纯个人学习.交流性质的技术博客,一个很不错的网站,现在我免费分享给大家.对 java ...