OpenMP Programming
一、OpenMP概述
1.OpenMP应用编程接口API是在共享存储体系结构上的一个编程模型
2.包含 编译制导(compiler directive)、运行库例程(runtime library)、环境变量(environment variables)
3.支持增量并行化
4.结合了两种并行编程的方式
——编译制导语句,在编译过程并行化代码
——运行时库函数,在运行时对并行环境支持
什么是OpenMP?
- 应用编程接口API
- 由三个基本API部分构成(运行时库、环境变量、编译命令)
-是c/c++和fortan等的应用编程接口
-已经被大多数计算机硬件和软件厂家所标准化
OpenMP不包含的性质
- 不是建立在分布式存储系统上的
- 不是在所有的环境下都是一样的
- 不是能保证让多数共享存储器均能有效的利用
二、OpenMP并行编程模型
· 基于线程的并行编程模型
·OpenMP使用Fork-Join并行执行
· 以线程为基础,通过编译制导语句来显示地制导并行化,为编程人员提供了对并行化的控制

通常由一个主线程fork多个子线程,在将子线程的结果汇总到一起
fork-join执行模式:
-在开始执行的时候,只有主线程的运行线程存在
-主线程在运行过程中,遇到需要并行计算的时候,派生线程来执行并行任务
-在并行执行的时候,主线程和派生线程共同工作
-在并行代码结束执行的时候,派生线程退出或者挂起,不再工作,控制流程回到单独的主线程中(join,即多线程的汇合)
三、编译制导
OpenMP的#pragma语句的格式为: #pragma omp directive_name ...
| #pragma omp | directive_name | [clause, ...] | newline |
| 制导指令前缀。对所有的OpenMP语句都需要这样的前缀 | OpenMP制导指令。在制导指令前缀和子句之间必须有一个正确的OpenMP制导指令。 | 子句。在没有其它约束条件下,子句可以无序,也可以任意的选择。这一部分也可以没有。 | 换行符。表明这条制导语句的终止。 |
编译制导语句
在编译器编译程序的时候,会识别特定的注释。这些注释包含着OpenMP程序的一些语义。
#pragma omp <directive> [clause,]
其中directive 部分包含了具体的编译制导语句,包括:
parallel
for
parallel for
section
sections
single
master
critical
flush
ordered
atomic
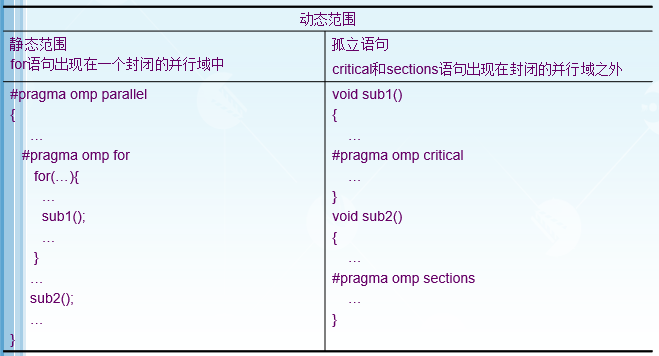
作用域
-静态扩展
·文本代码在一个编译制导语句之后,被封装到一个结构块中
-孤立语句
·一个OpenMP的编译制导语句不依赖于其他的语句
-动态扩展
·包括静态范围和孤立语句
并行域结构
·并行域中的代码被所有的线程执行
·具体格式
- #pragma omp parallel [clause[[,]clause]...] newline
- clause =
·if(scalar-expression)
·private(list)
·firstprivate(list)
·default(shared | none)
·shared(list)
·copyin(list)
·reduction(list)
·num_threads(integer-expression)
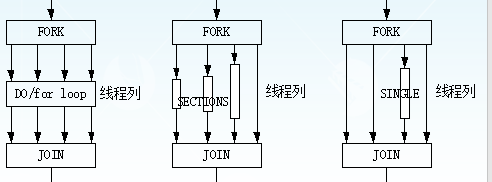
共享任务结构
· 共享任务结构将它所包含的代码划分给线程组的各成员来执行
-并行for循环
-并行sections
-串行执行
for编译制导语句
·for语句指定紧随它的循环语句必须由线程组并行执行;
·语句格式
#pragma omp for [clause[[,]clause]…] newline
[clause]=
Schedule(type [,chunk]): schedule子句描述如何将循环的迭代划分给线程组中的线程,如果没有指定chunk大小,迭代会尽可能的平均分配给每个线程,type为static,循环被分成大小为 chunk的块,静态分配给线程,type为dynamic,循环被动态划分为大小为chunk的块,动态分配给线程.
ordered:
private (list)
firstprivate (list)
lastprivate (list)
shared (list)
reduction (operator: list)
nowait
简单循环并行化
将两个向量相加,并将计算的结果保存到第三个向量中,向量的维数为n
for(int i=;i<n;i++)
z[i]=x[i]+y[i];
判读分量之间有无数据相关性:无
判断循环计算的过程有无循环依赖性 :无
程序改成:
#pragma omp parallel for
for(int i=;i<n;i++)
z[i]=x[i]+y[i];
循环并行化编译制导语句的子句
循环并行化子句可以包含一个或多个子句来控制循环并行化的执行
有多个类型的子句可以用来控制循环并行化编译
最主要的子句是数据作用域子句。
由于有多线程同时执行循环语句中的功能指令,这就涉及到数据的作用域问题
作用域用来控制某一个变量是否是在各个线程之间共享或者是某一个线程是私有的
数据的作用域子句用shared来表示一个变量是各个线程之间共享的
用private来表示一个变量是每一个线程私有的
默认的变量作用域是共享的
其他编译指导子句
用来控制线程的调度(schedule子句)
动态控制是否并行化(if子句)
进行同步的子句(ordered子句)
控制变量在串行部分与并行部分传递的子句(copyin子句)
循环嵌套(实例):
#include<stdio.h>
#include <omp.h> int main()
{
int i;
int j;
#pragma omp parallel for private(j)
for(i = ; i<; i++)
for (j = ; j < ; j++)
printf("i = %d j = %d\n", i, j);
getchar();
return ; }
在VS2013上运行的效果如下图所示:
第一次运行

第二次运行

在Linux上通过GCC编译:gcc -Os -fopenmp hello.c -o hello
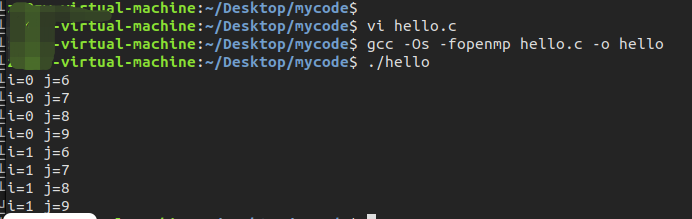
说明两个问题:
(1)不同编译器运行的效果不同
(2) 不同的操作系统对线程的时间分配也不同
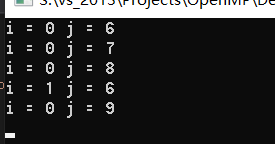
(3)在这个例子中,如果把j改成1000,在Linux下重新编译运行,可以看到明显的线程乱序效果,也就是说,哪个线程跑的快,就越先得到结果(当然这是废话)
注意,这里的j一定要设置成私有变量private,否则运行的的效果如下:
Sections编译制导语句
sections编译制导语句指定内部的代码被划分给线程组中的各线程,不同的section由不同的线程执行
Section语句格式:
#pragma omp sections [ clause[[,]clause]…] newline
{
[#pragma omp section newline]
…
[#pragma omp section newline]
…
}
clause=
private (list)
firstprivate (list)
lastprivate (list)
reduction (operator: list)
nowait
在sections语句结束处有一个隐含的路障,使用了nowait子句除外(一般的section后面都要用nowait)
#include <stdio.h>
#include <omp.h>
#define N 1000
int main(){
int i;
float a[N], b[N], c[N];
/* Some initializations */
for (i = ; i < N; i++)
a[i] = b[i] = i * 1.0;
#pragma omp parallel shared(a,b,c) private(i)
{
#pragma omp sections nowait
{
#pragma omp section
for (i = ; i < N / ; i++)
{
c[i] = a[i] + b[i];
printf("section 1 thread=%d\n", omp_get_thread_num());
} #pragma omp section
for (i = N / ; i < N; i++)
{
c[i] = a[i] + b[i];
printf("section 2 thread=%d\n", omp_get_thread_num());
}
} /* end of sections */
} /* end of parallel section */
getchar();
return ;
}
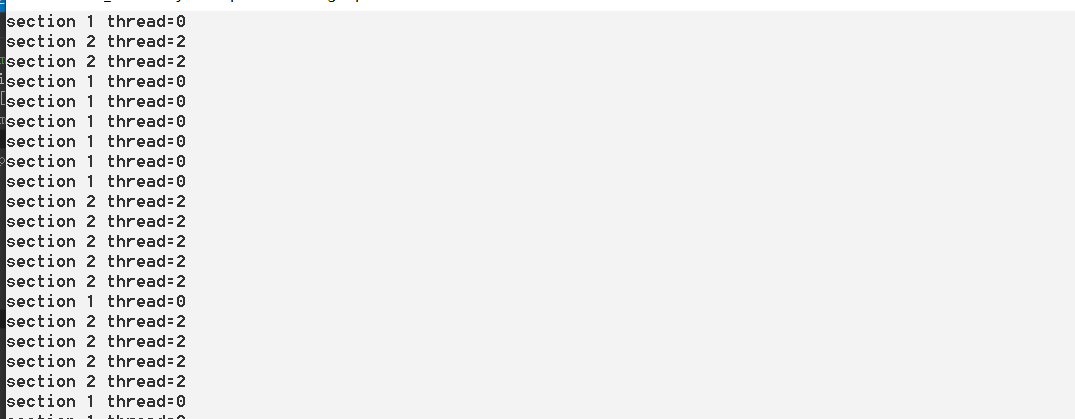
sections之间并行,每个sections里面的section是并行的,如果想让sections之间并行,只需要在sections后加上nowait指令即可。
具体讲解可参考博客:https://blog.csdn.net/scudz/article/details/43113133
single编译制导语句
single编译制导语句指定内部代码只有线程组中的一个线程执行。
线程组中没有执行single语句的线程会一直等待代码块的结束,使用nowait子句除外
语句格式:
#pragma omp single [clause[[,]clause]…] newline
clause=
private(list)
firstprivate(list)
nowait
同步结构
master 制导语句:制导语句指定代码段只有主线程执行
语句格式
#pragma omp master
critical制导语句:critical制导语句表明域中的代码一次只能执行一个线程 ,其他线程被阻塞在临界区
语句格式:
#pragma omp critical [name] newline
barrier制导语句:barrier制导语句用来同步一个线程组中所有的线程
先到达的线程在此阻塞,等待其他线程。barrier语句最小代码必须是一个结构化的块
语句格式
#pragma omp barrier
atomic制导语句:atomic制导语句指定特定的存储单元将被原子更新
语句格式
#pragma omp atomic newline

flush制导语句:flush制导语句用以标识一个同步点,用以确保所有的线程看到一致的存储器视图
语句格式
#pragma omp flush (list) newline
flush将在下面几种情形下隐含运行,nowait子句除外:

ordered制导语句:ordered制导语句指出其所包含循环的执行,只能出现在for或者parallel for语句的动态范围中
语句格式:
#pragma omp ordered
threadprivate编译制导语句:threadprivate语句使一个全局文件作用域的变量在并行域内变成每个线程私有
每个线程对该变量复制一份私有拷贝
语句格式:
#pragma omp threadprivate (list) newline
数据域属性子句
变量作用域范围
数据域属性子句
private子句:
private子句表示它列出的变量对于每个线程是局部的 。
语句格式
private(list)
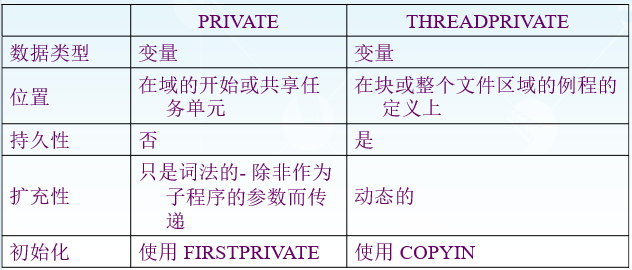
private和threadprivate区别:
shared子句
shared子句表示它所列出的变量被线程组中所有的线程共享
所有线程都能对它进行读写访问
语句格式
shared (list)
default子句
default子句让用户自行规定在一个并行域的静态范围中所定义的变量的缺省作用范围
语句格式
default (shared | none)
firstprivate子句
firstprivate子句是private子句的超集
对变量做原子初始化
语句格式:
firstprivate (list)
lastprivate子句
lastprivate子句是private子句的超集
将变量从最后的循环迭代或段复制给原始的变量
语句格式
lastprivate (list)
举个例子:
#include<omp.h> int main()
{
int val = ;
#pragma omp parallel for firstprivate(val) lastprivate(val)
for(int i = ; i<; i++){
printf("i=%d val=%d\n", i, val);
if(i == )
val = ;
printf("i=%d val=%d\n", i, val);
}
printf("val=%d\n", val); getchar();
return ;
}
结果是:
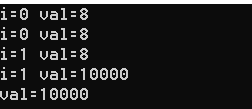
如果去掉lastprivate(val),结果是:

很明显,最后循环外的val值变了,lastprivate是将循环里面变量的值带到外面来。
copyin子句
copyin子句用来为线程组中所有线程的threadprivate变量赋相同的值
主线程该变量的值作为初始值
语句格式
copyin(list)
reduction子句
reduction子句使用指定的操作对其列表中出现的变量进行规约
初始时,每个线程都保留一份私有拷贝
在结构尾部根据指定的操作对线程中的相应变量进行规约,并更新该变量的全局值
语句格式
reduction (operator: list)
例子:
#include <iostream>
#include <omp.h> int main()
{
int sum = ;
std::cout << "Before: " << sum << std::endl; #pragma omp parallel for reduction(+:sum)
for(int i = ; i < ; ++i)
{
sum = sum + i;
std::cout << sum << std::endl;
} std::cout << "After: " << sum << std::endl;
return ;
}
其中sum是共享的,采用reduction之后,每个线程根据reduction(+:sum)的声明算出自己的sum,然后再将每个线程的sum加起来。
运行程序,发现第一个线程sum的值依次为0、1、3、6、10;第二个线程sum的值依次为5、11、18、26、35;最后10+35=45。
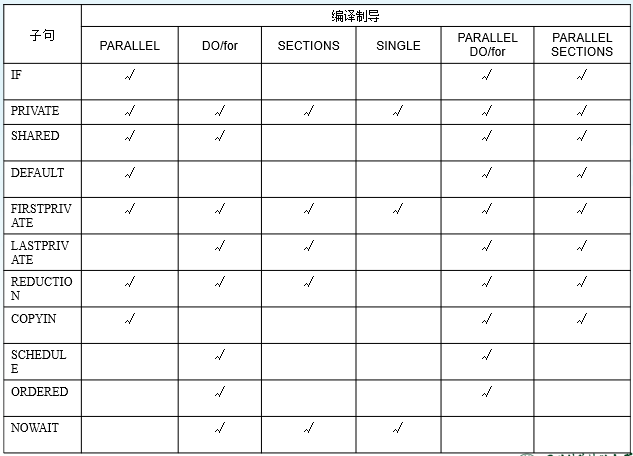
子句、编译制导语句总结
语句绑定和嵌套规则
语句DO/for、SECTIONS、SINGLE、MASTER和BARRIER绑定到动态的封装PARALLEL中,如果没有并行域执行,这些语句是无效的;
语句ORDERED指令绑定到动态DO/for封装中;
语句ATOMIC使得ATOMIC语句在所有的线程中独立存取,而并不只是当前的线程;
语句CRITICAL在所有线程有关CRITICAL指令中独立存取,而不是只对当前的线程;
在PARALLEL封装外,一个语句并不绑定到其它的语句中。
运行库例程与环境变量
·运行库例程
OpenMP标准定义了一个应用编程接口来调用库中的多种函数
对于C/C++,在程序开头需要引用文件“omp.h”
·环境变量
OMP_SCHEDULE:只能用到for,parallel for中。它的值就是处理器中循环的次数
OMP_NUM_THREADS:定义执行中最大的线程数
OMP_DYNAMIC:通过设定变量值TRUE或FALSE,来确定是否动态设定并行域执行的线程数
OMP_NESTED:确定是否可以并行嵌套
三、OpenMP计算实例
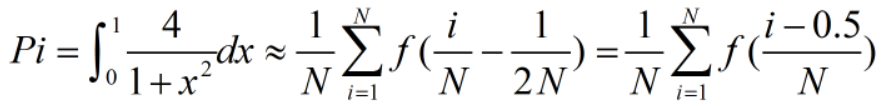

c语言写的串行程序:
/* Seriel Code */
static long num_steps = ;
double step;
void main ()
{ int i;
double x, pi, sum = 0.0;
step = 1.0/(double) num_steps;
for (i=;i< num_steps; i++){
x = (i+0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
pi = step * sum;
}
并行程序:
#include <omp.h>
#include <iostream>
static long num_steps = ;
double step;
#define NUM_THREADS 2
int main()
{
int i;
int id = omp_get_thread_num();
double x, pi, sum[NUM_THREADS];
printf("thread_id=%d \n", id);
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel private(i)
{
double x;
int id;
id = omp_get_thread_num();
printf("thread_id=%d \n", id);
for (i = id, sum[id] = 0.0; i< num_steps; i = i + NUM_THREADS){// x = (i + 0.5)*step;
sum[id] += 4.0 / (1.0 + x*x);
}
}
for (i = , pi = 0.0; i<NUM_THREADS; i++)
pi += sum[i] * step;
printf("%f", pi);
getchar();
return ; }
OpenMP Programming的更多相关文章
- 应用OpenMP的一个简单的设计模式
小喵的唠叨话:最近很久没写博客了,一是因为之前写的LSoftmax后馈一直没有成功,所以在等作者的源码.二是最近没什么想写的东西.前两天,在预处理图片的时候,发现处理200w张图片,跑了一晚上也才处理 ...
- OpenMP初步(英文)
Beginning OpenMP OpenMP provides a straight-forward interface to write software that can use multipl ...
- OpenMP并行编程
什么是OpenMP?“OpenMP (Open Multi-Processing) is an application programming interface (API) that support ...
- OpenMp 基本
OpenMp是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性的编译处理方案(Compiler Di ...
- High level GPU programming in C++
https://github.com/prem30488/C2CUDATranslator http://www.training.prace-ri.eu/uploads/tx_pracetmo/GP ...
- Introduction to Multi-Threaded, Multi-Core and Parallel Programming concepts
https://katyscode.wordpress.com/2013/05/17/introduction-to-multi-threaded-multi-core-and-parallel-pr ...
- OpenMP 并行程序设计入门
OpenMP 是一个编译器指令和库函数的集合,主要是为共享式存储计算机上的并行程序设计使用的. 0. 一段使用 OpenMP 的并行程序 #include <stdio.h> #inclu ...
- [CUDA] 00 - GPU Driver Installation & Concurrency Programming
前言 对,这是一个高大上的技术,终于要做老崔当年做过的事情了,生活很传奇. 一.主流 GPU 编程接口 1. CUDA 是英伟达公司推出的,专门针对 N 卡进行 GPU 编程的接口.文档资料很齐全,几 ...
- A Pattern Language for Parallel Programming
The pattern language is organized into four design spaces. Generally one starts at the top in the F ...
随机推荐
- RabbitMQ传输原理、五种模式
本文代码基于SpringBoot,文末有代码连接 .首先是一些在Spring Boot的一些配置和概念,然后跟随代码看下五种模式 MQ两种消息传输方式,点对点(代码中的简单传递模式),发布/订阅(代码 ...
- B 小雨的三角形
题目链接:https://ac.nowcoder.com/acm/contest/949/B 思路: 一个找规律题,找到规律就很简单,只剩下代码实现了.规律:第i行去头尾剩下的数的和等于第i-1行去头 ...
- eclipse 大括号改为C语言一样的代码块
如图:找到Windows->Preferences->Java->Code Style->Formatter: 然后,点击右边的Edit按钮: 按如下图完成
- Centos_7安装python-pip
使用yum -y install python-pip安装pip时,会报出”No package python-pip available.“. 使用命令: yum -y install epel-r ...
- 公式化学习requests(第二卷)
请求浏览器分为两种一种是不需要用户登录验证直接请求 另一种是需要用户登陆验证请求,现在说一下利用COOKIE实现,COOKIE在前端开发时有很多的作用,要熟练使用, 直接上代码了: 第一步:访问页面, ...
- LibreOJ β Round #2」贪心只能过样例
题目友链:https://loj.ac/problem/515 话说这题蛮简单,bitset暴力直接过. 话不多说,上代码! #include <bits/stdc++.h> using ...
- (转)假如没有OI By Vani
假如没有OI ...
- MyBatis 逆向工程介绍
1. 概念: 逆向工程就是根据数据库中对应的表在项目工程中生成相应的MyBatis代码(XXXMapper.java/XXXMapper.xml/Moudle(XXX)),逆向工程生成的代码可以进行简 ...
- Python中为什么可以通过bin(n & 0xffffffff)来获得负数的补码?
一开始我以为这不是个大问题,因为本来整型数在内存中就是以补码的形式存在的,输出自然也是按照补码输出的,例如C语言中 printf("%X\n",-3); //输出 //FFFFFF ...
- Mac下如何使用homebrew
Homebrew简称brew,是Mac OSX上的软件包管理工具,能在Mac中方便的安装软件或者卸载软件. 常用的命令: 搜索软件:brew search 软件名,如brew search wget ...