Python自定义模块
自定义模块
自定义模块(也就是私人订制),我们要自定义模块,首先就要知道什么是模块
一个函数封装一个功能,比如现在有一个软件,不可能将所有程序都写入一个文件,所以咱们应该分文件,组织结构要好,代码不冗余,所以要分文件,但是分文件,分了5个文件,每个文件里面可能都有相同的功能(函数),怎么办?所以将这些相同的功能封装到一个文件中.
模块就是文件,存放一堆函数,谁用谁拿。怎么拿?
模块是一系列常用功能的集合体,一个py文件就是一个模块
为什么要使用模块?
1、从文件级别组织程序,更方便管理
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
2、拿来主义,提升开发效率
同样的原理,我们也可以下载别人写好的模块然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子。
ps:
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python meet.py方式去执行,此时meet.py被称为脚本script。
'''
-*- coding: utf- -*-
@Author : Meet
@Software: PyCharm
@File : meet.py
'''
print('from the meet.py') name = 'guoboayuan' def read1():
print('meet模块:',name) def read2():
print('meet模块')
read1() def change():
global name
name = 'meet'
导入
import 翻译过来是一个导入的意思
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行
(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:
第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句),
如下
import spam #只在第一次导入时才执行meet.py内代码,此处的显式效果是只打印一次'from the meet.py',当然其他的顶级代码也都被执行了,
只不过没有显示效果.代码示例:
import meet
import meet
import meet
import meet
import meet 执行结果: 只打印一次
from the meet.py
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,
就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
示例:
当前是meet.py
import meet name = 'alex'
print(name)
print(meet.name)
'''
结果:
from the meet.py
alex
guoboayuan
'''
import meet
def read1():
print()
meet.read1()
'''
from the meet.py
meet模块: guoboayuan
'''
import meet
name = '日天'
meet.change()
print(name)
print(meet.name)
'''
from the meet.py
日天
宝元
'''
为模块起别名
别名其实就是一个绰号,好处可以将很长的模块名改成很短,方便使用.
import meet.py as t
t.read1()
有利于代码的扩展和优化
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse') #test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db db.sqlparse()
导入多个模块
import os,sys,json 这样写可以但是不推荐
推荐写法 import os
import sys
import json
多行导入:易于阅读 易于编辑 易于搜索 易于维护
from ... import ...
from...import...使用
from meet import name, read1
print(name)
read1()
'''
执行结果:
from the meet.py
guoboayuan
meet模块: guoboayuan
'''
from...import... 与import对比
唯一的区别就是:使用from...import...则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,
直接使用名字就可以了、无需加前缀:meet.
from...import...的方式有好处也有坏处
好处:使用起来方便了
坏处:容易与当前执行文件中的名字冲突
示例演示:
1.执行文件有与模块同名的变量或者函数名,会有覆盖效果。
name = 'oldboy'
from meet import name, read1, read2
print(name)
'''
执行结果:
from the meet.py
guoboayuan
'''
from meet import name, read1, read2
name = 'oldboy'
print(name) '''
执行结果:
oldboy '''
def read1():
print()
from meet import name, read1, read2
read1() '''
执行结果:
from the meet.py
meet模块: guoboayuan
'''
from meet import name, read1, read2
def read1():
print()
read1() '''
执行结果:
from the meet.py '''
2.当前位置直接使用read1和read2就好了,执行时,仍然以spam.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到meet.py中寻找全局变量name
#test.py
from meet import read1
name = 'alex'
read1()
'''
执行结果:
from the meet.py
meet--> read1 --> guobaoyuan
'''
#测试二:导入的函数read2,执行时需要调用read1(),仍然回到meet.py中找read1()
#test.py
from meet import read2
def read1():
print('==========')
read2() '''
执行结果:
from the meet.py
meet --> read2 --> 'meet模块' --> read1 -->'guobaoyuan'
'''
from导入的模式也支持as
from meet import read1 as read
read()
from导入的时候,一行导入多个内容
from meet import read1,read2,name
全部导入
from meet import *
#from spam import * 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置 #大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用__all__来控制*(用来发布新版本),在meet.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
模块循环导入问题
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
在我们的项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方
在程序出现了循环/嵌套导入后的异常分析、解决方法如下(了解,以后尽量避免)
示范文件内容如下
#创建一个m1.py
print('正在导入m1')
from m2 import y x='m1' #创建一个m2.py
print('正在导入m2')
from m1 import x y='m2' #创建一个run.py
import m1 #测试一
执行run.py会抛出异常
正在导入m1
正在导入m2
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/aa.py", line , in <module>
import m1
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line , in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line , in <module>
from m1 import x
ImportError: cannot import name 'x' #测试一结果分析
先执行run.py--->执行import m1,开始导入m1并运行其内部代码--->打印内容"正在导入m1"
--->执行from m2 import y 开始导入m2并运行其内部代码--->打印内容“正在导入m2”--->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错 #测试二:执行文件不等于导入文件,比如执行m1.py不等于导入了m1
直接执行m1.py抛出异常
正在导入m1
正在导入m2
正在导入m1
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line , in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line , in <module>
from m1 import x
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line , in <module>
from m2 import y
ImportError: cannot import name 'y' #测试二分析
执行m1.py,打印“正在导入m1”,执行from m2 import y ,导入m2进而执行m2.py内部代码--->打印"正在导入m2",执行from m1 import x,此时m1是第一次被导入,执行m1.py并不等于导入了m1,于是开始导入m1并执行其内部代码--->打印"正在导入m1",执行from m1 import y,由于m1已经被导入过了,所以无需继续导入而直接问m2要y,然而y此时并没有存在于m2中所以报错 # 解决方法:
方法一:导入语句放到最后
#m1.py
print('正在导入m1') x='m1' from m2 import y #m2.py
print('正在导入m2')
y='m2' from m1 import x 方法二:导入语句放到函数中
#m1.py
print('正在导入m1') def f1():
from m2 import y
print(x,y) x = 'm1' # f1() #m2.py
print('正在导入m2') def f2():
from m1 import x
print(x,y) y = 'm2' #run.py
import m1 m1.f1()
模块的重载(了解)
考虑到性能的原因,每个模块只被导入一次,放入字典sys.module中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块,
有的同学可能会想到直接从sys.module中删除一个模块不就可以卸载了吗,注意了,你删了sys.module中的模块对象仍然可能被其他程序的组件所引用,因而不会被清楚。
特别的对于我们引用了这个模块中的一个类,用这个类产生了很多对象,因而这些对象都有关于这个模块的引用。
py文件的两种功能
#编写好的一个python文件可以有两种用途:
一:脚本,一个文件就是整个程序,用来被执行
二:模块,文件中存放着一堆功能,用来被导入使用 #python为我们内置了全局变量__name__,
当文件被当做脚本执行时:__name__ 等于'__main__'
当文件被当做模块导入时:__name__等于模块名 #作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
if __name__ == '__main__':
print('from the meet.py') __all__ = ['name', 'read1', ] name = 'guobaoyuan' def read1():
print('meet模块:', name) def read2():
print('meet模块')
read1() def change():
global name
name = '宝元' if __name__ == '__main__':
# 在模块文件中测试read1()函数
# 此模块被导入时 __name__ 就变成了文件名,if条件不成立
# 所以read1不执行
read1()
模块的搜索路径
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
#模块的查找顺序
、在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看
、如果没有,解释器则会查找同名的内建模块
、如果还没有找到就从sys.path给出的目录列表中依次寻找spam.py文件。 #需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。 #在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
>>> import sys
>>> sys.path.append('/a/b/c/d')
>>> sys.path.insert(,'/x/y/z') #排在前的目录,优先被搜索
注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找. #windows下的路径不加r开头,会语法错误
sys.path.insert(,r'C:\Users\Administrator\PycharmProjects\a')
编译Python文件(了解)
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,spam.py模块会被缓存成__pycache__/spam.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的,不是用来加密的。
#提示:
.模块名区分大小写,foo.py与FOO.py代表的是两个模块
.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的
.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件.
time模块
time翻译过来就是时间,有我们其实在之前编程的时候有用到过.
#常用方法
.time.sleep(secs)
(线程)推迟指定的时间运行。单位为秒。
.time.time()
获取当前时间戳
在计算中时间共有三种方式:
1.时间戳: 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型
2.格式化字符串时间: 格式化的时间字符串(Format String): ‘1999-12-06’
python中时间日期格式化符号:
%y 两位数的年份表示(-)
%Y 四位数的年份表示(-)
%m 月份(-)
%d 月内中的一天(-)
%H 24小时制小时数(-)
%I 12小时制小时数(-)
%M 分钟数(=)
%S 秒(-)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(-)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(-)星期天为星期的开始
%w 星期(-),星期天为星期的开始
%W 一年中的星期数(-)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
3.结构化时间:元组(struct_time) struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
首先,我们先导入time模块,来认识一下python中表示时间的几种格式:
#导入时间模块
>>>import time #时间戳
>>>time.time()
1500875844.800804 #时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04' #时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=, tm_mon=, tm_mday=,
tm_hour=, tm_min=, tm_sec=,
tm_wday=, tm_yday=, tm_isdst=)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
时间格式转换:
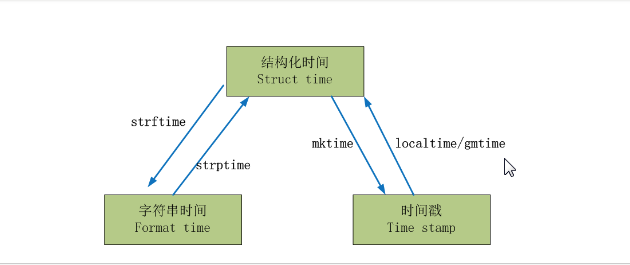
#时间戳-->结构化时间
#time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致
#time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
>>>time.gmtime()
time.struct_time(tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=)
>>>time.localtime()
time.struct_time(tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=) #结构化时间-->时间戳
#time.mktime(结构化时间)
>>>time_tuple = time.localtime()
>>>time.mktime(time_tuple)
1500000000.0 #结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime())
'2017-07-14' #字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=-)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=-)
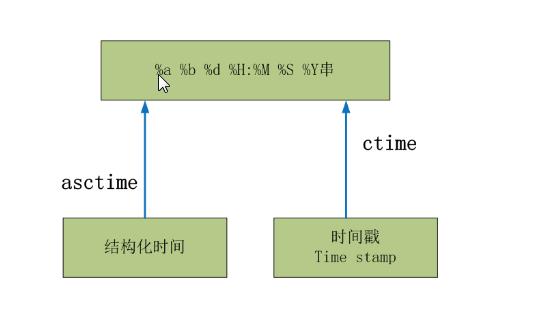
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime())
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017' #时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime()
'Fri Jul 14 10:40:00 2017'
我们看完了time在来看一个Python处理日期和时间的标准库
datetime
获取当前日期和时间
from datetime import datetime print(datetime.now()) '''
结果:-- ::48.734886
'''
注意:datetime是模块,datetime模块还包含一个datetime的类,通过from datetime import datetime导入的才是datetime这个类。
如果仅导入import datetime,则必须引用全名datetime.datetime。
datetime.now()返回当前日期和时间,其类型是datetime。
获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
from datetime import datetime dt = datetime(,,,,)
print(dt) '''
结果:-- ::
'''
datetime转换为timestamp(时间戳)
from datetime import datetime dt = datetime.now()
new_timestamp = dt.timestamp()
print(new_timestamp) '''
结果:1543931750.415896
'''
timestamp转换为datetime
import time
from datetime import datetime new_timestamp = time.time()
print(datetime.fromtimestamp(new_timestamp))
str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
from datetime import datetime
t = datetime.strptime('2018-4-1 00:00','%Y-%m-%d %H:%M')
print(t)
'''
结果: -- ::
'''
datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
from datetime import datetime
now = datetime.now()
print(now.strftime('%a, %b %d %H:%M'))
Mon, May :
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
from datetime import datetime, timedelta
now = datetime.now()
print(now)
now1 = now + timedelta(hours=)
print(now1)
now2 = now - timedelta(days=)
print(now2)
now3 = now + timedelta(days=, hours=)
print(now3)
可见,使用timedelta你可以很容易地算出前几天和后几天的时刻。
小结注意
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
Python自定义模块的更多相关文章
- python 自定义模块的发布和安装
[学习笔记] 自定义模块 使用的是pycharm 说白了就是.py文件都可以作为模块导入,像定义一个文件 名字为Mycode __all__ = ["add","sub& ...
- 万恶之源 - Python 自定义模块
自定义模块 我们今天来学习一下自定义模块(也就是私人订制),我们要自定义模块,首先就要知道什么是模块啊 一个函数封装一个功能,比如现在有一个软件,不可能将所有程序都写入一个文件,所以咱们应该分文件,组 ...
- 从入门到自闭之Python自定义模块
自定义模块 定义:一个文件就是一个模块(能被调用的文件,模块就是一个工具箱,工具就是函数) 作用: 将代码文家化管理,提高可读性,避免重复代码 拿来就用(避免重复造轮子),python中类库比较多,提 ...
- 17.python自定义模块的导入方式
1.直接用import导入 最后运行main.py可以看到命令行窗口输出了一句:你好,这样就完成了. 2.通过sys模块导入自定义模块的路径path 3.在环境变量中找到自定义模块 这个方法原理就是利 ...
- Python 自定义模块位置
1.需要找出Python解释器从哪里查找模块: 具体方法: >>> import sys,pprint>>> pprint.pprint(sys.path)['', ...
- 8. Python自定义模块humansize
我们在提取一个文件元信息的时候,经常会使用到获取元信息的size, 但是默认提取出来的是字节为单位计算的大小,我们需要转换成MB或者GB 或者TB的大小. 因此就需要使用到humansize这个模块, ...
- Python 自定义模块的打包和发布
写了一个Python模块,要求打包发布,供同事们使用,好吧,查了一下,网上大部分教程没有一个能把话说明白,不过最后还是解决了,特此记录一下, 以免下次遇到同样问题,也帮助其他有缘人,哈哈. 首先看一下 ...
- python自定义模块导入方法,文件夹,包的区别
python模块导入,网上介绍的资料很多,方法也众说纷纭.根据自己的实践,感觉这个方法最简单直接,而且可以与主流的python ide生成的工程是一样的. 规则只有三条 1. 严格区分包和文 ...
- linux-导入python自定义模块的使用方法
#!/usr/bin/python # -*- coding:utf -8 -*- import os import sys sys.path.append("/h/s/compare_f& ...
随机推荐
- mysql 优化一
从几个方面出发: ① 数据库设计② sql语句优化③ 数据库参数配置④ 恰当的硬件资源和操作系统 下面详细介绍: ① 数据库设计 通俗地理解三个范式,对于数据库设计大有好处.在数据库设计中,为了更好地 ...
- Redmine it!
redmine插件开发简介 最稳妥的学习应该是先看官方文档,官方还给了一个具体的插件开发教程,不过如果一步不差按照教程敲代码,其实会发现还是有些问题的,需要稍稍改动. 这里,我自己编写了一个简单的插件 ...
- MySQL 之全文索引
最近在复习数据库索引部分,看到了 fulltext,也即全文索引,虽然全文索引在平时的业务中用到的不多,但是感觉它有点儿意思,所以花了点时间研究一下,特此记录. 引入概念通过数值比较.范围过滤等就可以 ...
- OpenSSL之X509系列
OpenSSL之X509系列之1---引言和X509概述 [引言] X509是系列的函数在我们开发与PKI相关的应用的时候我们都会用到,但是OpenSSL中对X509的描述并不是很多,鉴于些,我 ...
- 植物基因组|注释版本问题|重测序vs泛基因组
生命组学: 细菌和其他物种比,容易发生基因漂移,duplication和重排. 泛基因组学研究的一般思路是通过comparison找到特殊基因区域orspecific gene,研究其调控机制(即通过 ...
- Cenos配置Android集成化环境, 最终Centos libc库版本过低放弃
To honour the JVM settings for this build a new JVM will be forked. Please consider using the daemon ...
- Ubuntu环境下的iptables的端口转发配置实例
打开转发开关要让iptables的端口转发生效,首先需要打开转发开关方法一:临时打开,重启后失效$sudo su#echo 1 >/proc/sys/net/ipv4/ip_forward 方法 ...
- Java线程知识
概念 线程生命周期 Java线程模型 线程方法 线程优先级 线程同步 线程在多任务处理应用程序中有着至关重要的作用 概念 基本概念 进程:在操作系统中每个独立运行的程序就是一个进程 线程:程序执行的一 ...
- R语言入门级实例——用igragh包分析社群
R语言入门级实例——用igragh包分析社群 引入—— 本文的主要目的是初步实现R的igraph包的基础功能,包括绘制关系网络图(social relationship).利用算法进行社群发现(com ...
- 华为的Java面试题,仅供参考。
IP地址的编码分为哪俩部分? IP地址由两部分组成,网络号和主机号.不过是要和“子网掩码”按位与上之后才能区分哪些是网络位哪些是主机位. 2.用户输入M,N值,从1至N开始顺序循环数数,每数到M输出该 ...