机器学习- Attention Model结构解释及其应用
- 概述
Attention Model 的出现,在sequence model的领域中算是一个跨时代的事件。在Many-to-Many的sequence model中,在decoder network中的每一个time step的输出应该跟encoder network中的不同的time step的值的联系度是不一样的;举个例子,如果咱们将一段中文翻译成英文,如果用传统的Many-to-Many的结构的sequence model来做的话,如果是句子的长度不长的话,咱们的结果准确度也不会很差,但是如果是一段较长的句子的话,咱们的LSTM 中的记忆的Hidden state不能记忆太多的信息,从而导致了咱们的结果可能很差,那么这个时候就很需要咱们的Attention Model啦, 具体的它是如何做到将decoder network中的输出跟encoder network中的每一个time step的值联系的,是咱们这节内容的重点,同时咱们这一节也会中代码实现这个attention model的过程。
- Attention Model的结构分析
Attention Model是由2层LSTM组成的,这2层LSTM layer并不是直接相连的,而是通过Attention简介的将2个LSTM layer连接在一起,这一步的分析咱们分成2个阶段:第一步先分析整体的Attention Model的结构;第二步再分析分析具体的Attention的内部结构。首先咱们先看一下Attention Model的整体结构,如下图所示
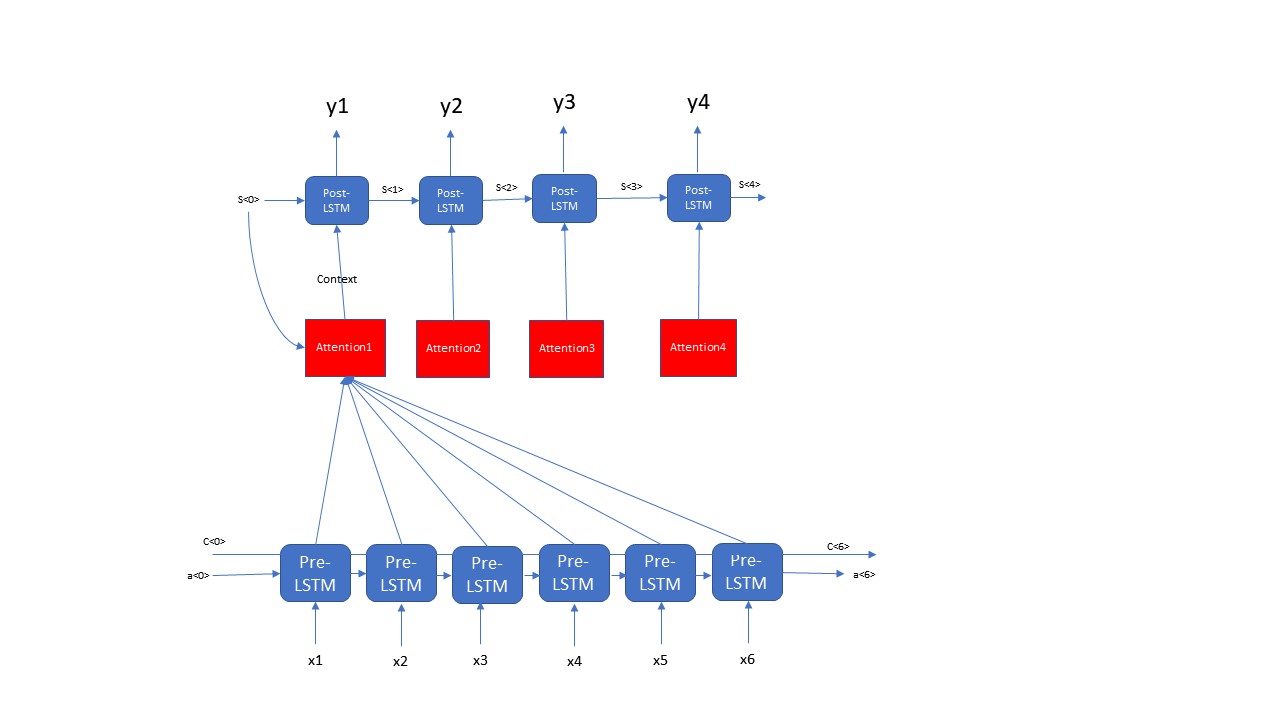
这一步咱们通过演示一个Attention的例子来展示一个Attention model的整体结构,咱们可以看出来Attention Model是由Pre-LSTM layer, Post-LSTM layer, Attention三个主要模块组成的,这里有个细节上图中画错了,大家注意一下,那就是Pre-LSTM layer是Bi-directional的而不是上图的画的那样forward feed的network。每一个time step的Post-LSTM都对应一个相应的Attention, 每一个Attention的输入都由以下两个部分组成:Post-LSTM 前一个time step的hidden state- s<t-1> 和 Pre-LSTM中所有time step的输出; 这两个部分共同决定了一个Attention Unit的输出Context,最终这个Context又会最为Post-LSTM的输入,从而最终影响着咱们Attention Model的输出。咱们从上面的分析可以很清楚的看出咱们的Attention Model的一个整体的结构,那么接下来咱们再来看一下每一个Attention里面的细节部分

从上图的Attention的结构咱们可以看出来,咱们需要先将t-1步的hidden state 通过repeator去复制Tx份,然后将这些repeator的结构和咱们的输入X 去拼接,生成一个(batch_size, Tx, n_a+n_s)维度的数据,并且将这些数据输入到2层Fully connected 的dense layer中,输出的结果是(batch_size, Tx, 1)的数据结构,最后将这些数据输入到一个softmax layer中,生成一个装有咱们对于每一个Pre-LSTM权重,这些权重之和是1,dimension是(batch_size, Tx); 最后咱们用相应的权重乘以相应的time step 的Pre-LSTM的hidden state,最终生成了咱们的Context,Context的dimension是(batch_size, n_a)。上面的两步共同决定了咱们Attention Model的结构,那么接下来的任务就是实现,用代码来构建上面的Attention Model的结构。
- Attention Model的代码实现
既然上面的结构分析以及展示了咱们Attention Model的细节结构,那么咱在实现上图中的结构也是要分成2部分,第一部分就是用代码构建一个Attention Unit的结构;第二部分就是用代码来构建咱们Attention Model的整体结构。接下来咱们先来看一下构建Attention Model的中的Attention的实现过程,代码如下:
def one_step_attention(a, s_pre):
"""
Performs one step of attention: Outputs a context vector computed as a dot product of the attention weights
"alphas" and the hidden states "a" of the Bi-LSTM.
Arguments:
a -- hidden state output of the Bi-LSTM, numpy-array of shape (m, Tx, 2*n_a)
s_prev -- previous hidden state of the (post-attention) LSTM, numpy-array of shape (m, n_s)
Returns:
context -- context vector, input of the next (post-attention) LSTM cell
"""
# Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a"
s_pre = repeator(s_pre)
# Use concatenator to concatenate a and s_prev on the last axis
# For grading purposes, please list 'a' first and 's_prev' second, in this order.
concat = concatenator([a,s_pre])
# Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e.
e = densor1(concat)
# Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies. (≈1 lines)
energies = densor2(e)
# Use "activator" on "energies" to compute the attention weights "alphas"
alphas = activator(energies)
# Use dotor together with "alphas" and "a" to compute the context vector to be given to the next (post-attention) LSTM-cell
context = dotor([alphas,a])
return context
注意上图中的repeator, concatenator, densor1, densor2, activator, dotor等等都是在上面函数体外面实例化好了的,他们都是Keras的layer,在这里因为篇幅的原因,我就没有写出来了,这里我主要展示的是Attention Model的结构的构建,而忽略了一些细节处理的部分。上面代码展示了一个attention unit如何将pre-LSTM的每一步的输出转化成post-LSTM的输入的;既然有了这个输入,那么咱们就来看一下咱们如何来实现这个整体的attention model的结构吧
def model(Tx, Ty, n_a, n_s):
X = tf.keras.layers.Input(shape=(Tx,vocab_dimension))
s0 = tf.keras.layers.Input(shape = (n_s,))
c0 = tf.keras.layers.Input(shape = (n_s,))
s = s0
c = c0
a = Bidirectional(LSTM(n_a, return_sequence = True))(X)
outputs = []
for i in range(Ty):
context = one_step_attention(a, s)
s,_,c = post_lstm_cell(context, initial_state = [s,c])
output = output_layer(s)
outputs.append(output)
model = Model(inputs = [X,s0,c0], outputs = outputs)
return model
机器学习- Attention Model结构解释及其应用的更多相关文章
- (zhuan) 自然语言处理中的Attention Model:是什么及为什么
自然语言处理中的Attention Model:是什么及为什么 2017-07-13 张俊林 待字闺中 要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model( ...
- [转]自然语言处理中的Attention Model:是什么及为什么
自然语言处理中的Attention Model:是什么及为什么 https://blog.csdn.net/malefactor/article/details/50550211 /* 版权声明:可以 ...
- 深度学习方法(九):自然语言处理中的Attention Model注意力模型
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.NET/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 上一篇博文深度学习方法(八):Enc ...
- 自然语言处理中的Attention Model:是什么及为什么
/* 版权声明:能够随意转载.转载时请标明文章原始出处和作者信息 .*/ author: 张俊林 要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model(后文有 ...
- (转载)自然语言处理中的Attention Model:是什么及为什么
转载说明来源:http://blog.csdn.net/malefactor/article/details/50550211 author: 张俊林 原文写得非常好! 原文: 要是关注深度学习在自然 ...
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
- <A Decomposable Attention Model for Natural Language Inference>(自然语言推理)
http://www.xue63.com/toutiaojy/20180327G0DXP000.html 本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mec ...
- Attention Model详解
要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model(后文有时会简称AM模型)这个词.AM模型应该说是过去一年来NLP领域中的重要进展之一,在很多场景被证明有 ...
随机推荐
- 吴裕雄--天生自然HTML学习笔记:HTML 脚本
JavaScript 使 HTML 页面具有更强的动态和交互性. <!DOCTYPE html> <html> <head> <meta charset=&q ...
- Trie图 模板
trie图实际上是优化的一种AC自动机. trie图是在trie树上加一些失配指针,实际上是类似KMP的一种字符串匹配算法. 失配指针类似KMP的nx数组,有效地利用了之前失配的信息,优化了时间复杂度 ...
- Linux上SVN安装
SVN,Subversion,是一个开源的版本控制系统. svn有两种运行方式:独立的服务器和借助apache运行,各有利弊.
- 吴裕雄--天生自然KITTEN编程:切换角色
- Linux 下的/usr/bin /usr/sbin /usr/local/bin /usr/local/sbin区别
一./usr/sbin与/usr/bin区别: 1./usr/sbin:root权限下的命令属于基本的系统命令,如shutdown,reboot,用于启动系统,修复系统: 2./usr/bin普通用户 ...
- 一致性 Hash 算法分析
当我们在做数据库分库分表或者是分布式缓存时,不可避免的都会遇到一个问题: 如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少. Hash 取模 随机放置就不说了,会带来很多问 ...
- GRE阅读
界面和托福差不多,就是反一反 GRE先读文章!因为出题顺序不一致.另外,不能跳读!!每一句都要读,即使不是观点. 考察能力: 1 三秒版本 边读边概括 解决前面的抗遗忘能力 2 句间关系 取同 取反 ...
- How to Write a README on GitHub
最近在寫 GitHub 上的 README,發現這個東西好像每個人的寫法都不太一樣,於是稍微整理了一下自己覺得大概要包含哪些內容. Motivation 顧名思義就是簡介一下為什麼會有這個專案,以及這 ...
- IP不是万能药 为何有蜘蛛侠等大片的索尼要放弃电影
为何有蜘蛛侠等大片的索尼要放弃电影"> 近年来,国内狂炒"IP"这一概念,比如动漫.网络文学.小说.游戏等,甚至围绕IP制造出内容矩阵.从一个IP延伸至多个领域 ...
- 亚马逊,谷歌,Facebook,IBM和微软:为了AI,是的,我们在一起了
美国时间9月28日,也就是几个小时前,亚马逊,谷歌,Facebook,IBM和微软宣布成立了一家非盈利组织:人工智能合作组织(Partnership on AI),目标是为人工智能的研究制定和提供范例 ...