Redis 【常识与进阶】
Redis 简介
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势&缺点
- 数据类型多,纯内存操作,单线程避免上下文切换,非阻塞IO多路复用机制
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
- Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis与其他key-value存储有什么不同?
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Redis 持久化方式
- redis持久化介绍
- 由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了
- redis提供两种方式进行持久化:
- 第一种:RDB (将Redis中数据定时dump到硬盘)
- 第二种:AOF (将Reids的操作日志以追加的方式写入文件)
- 二者原理
- RDB持久化原理
- RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘
- 实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储
- RDB持久化原理
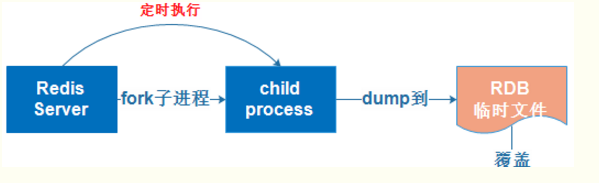
- AOF持久化原理
- AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
- AOF持久化原理

- RDB优缺点介绍(快照)
- RDB优点
- RDB优缺点介绍(快照)
1. 整个Redis数据库将只包含一个文件,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2. 性能最大化,它仅需要fork出子进程,由子进程完成持久化工作,极大的避免服务进程执行IO操作了。
3. 相比于AOF机制,如果数据集很大,RDB的启动效率会更高
- RDB缺点
1. RDB容易丢数据,因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失
2. RDB通过fork子进程来完成持久化的如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
AOF优缺点介绍(镜像)
- AOF优点
- 数据安全性高,Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容
- 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建
- AOF缺点
- 对于相同数量的数据集而言,AOF文件通常要大于RDB文件,RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- AOF在运行效率上往往会慢于RDB
在 /etc/redis.conf 中配置使用RDP
- RDP配置选项(这3个选项都屏蔽,则rdb禁用))
# save 900 1 // 900内,有1条写入,则产生快照
# save 300 1000 // 如果300秒内有1000次写入,则产生快照
# save 60 10000 // 如果60秒内有10000次写入,则产生快照
- RDP其他配置
# stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入? 主进程不停止 容易造成数据不一致
# rdbcompression yes // 导出的rdb文件是否压缩 如果rdb的大小很大的话建议这么做
# Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性 验证版本是不是一致
# dbfilename dump.rdb //导出来的rdb文件名
# dir ./ //rdb的放置路径
在 /etc/redis.conf 中配置使用AOF
# appendonly no // 是否打开aof日志功能 aof跟 rdb都打开的情况下
# appendfsync always // 每1个命令,都立即同步到aof. 安全,速度慢
# appendfsync everysec // 折衷方案,每秒写1次
# appendfsync no // 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快, # no-appendfsync-on-rewrite yes: // 正在导出rdb快照的过程中,要不要停止同步aof
# auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写 缺点 刚开始的时候重复重写多次
# auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写
测试使用: redis-benchmark -n 10000 表示 执行请求10000次,执行ls 发现出现 rdb 跟 aof文件。appendonly.aof dump.rdb
- 注意的事项
# 注: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
# 注: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里,以解决aof日志过大的问题.
# 问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof
# 问: 2种是否可以同时用?
答: 可以,而且推荐这么做 # 问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
Redis 数据类型
- redis中所有数据结构都以唯一的key字符串作为名称,然后通过这个唯一的key来获取对应的value
- 不同的数据类型数据结构差异就在于value的结构不一样
字符串(string)
- value的数据结构(数组)
- 字符串value数据结构类似于数组,采用与分配容易空间来减少内存频繁分配
- 当字符串长度小于1M时,扩容就是加倍现有空间
- 如果字符串长度操作1M时,扩容时最多扩容1M空间,字符串最大长度为 512M
- 编码:int 编码是用来保存整数值,raw编码是用来保存长字符串,而embstr是用来保存短字符串
- 字符串的使用场景(缓存)
- 字符串一个常见的用途是缓存用户信息,我们将用户信息使用JSON序列化成字符串
- 取用户信息时会经过一次反序列化的过程
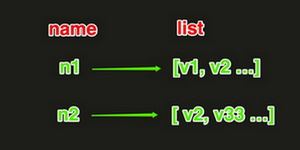
list(列表)
- value的数据结构(双向链表)
- 列表的数据结构是双向链表,这意味着插入和删除的时间复杂度是0(1),索引的时间复杂度位0(n)
- 它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表结构。
- 编码: 可以是 ziplist(压缩列表) 和 linkedlist(双端链表)
- 当列表弹出最后一个元素后,该数据结构会被自动删除,内存被回手
- 列表的使用场景(队列、栈)
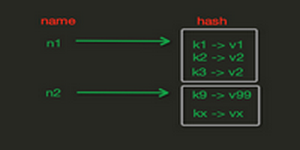
hash(字典)
- value的数据结构(HashMap)
- redis中的字典也是HashMap(数组+列表)的二维结构
- 不同的是redis的字典的值只能是字符串
- 编码:哈希对象的编码可以是 ziplist 或者 hashtable。
- hash的使用场景(缓存)
- hash结构也可以用来缓存用户信息,与字符串一次性全部序列化整个对象不同,hash可以对每个字段进行单独存储
- 这样可以部分获取用户信息,节约网络流量
- hash也有缺点,hash结构的存储消耗要高于单个字符串
set(集合)
- value的数据结构(字典)
- redis中的集合相当于一个特殊的字典,字典的所有value都位null
- 当集合中的最后一个元素被移除后,数据结构会被自动删除,内存被回收
- set使用场景
- set结构可以用来存储某个活动中中奖的用户ID,因为有去重功能,可以保证同一用户不会中间两次
zset(有序集合)
- value的数据结构(跳跃列表)
- zset一方面是一个set,保证了内部的唯一性
- 另一方面它可以给每一个value赋予一个score,代表这个value的权重
- zset内部实现用的是一种叫做“跳跃列表”的数据结构
- zset最后一个元素被移除后,数据结构就会被自动删除,内存也会被回收
- 编码:有序集合的编码可以是 ziplist 或者 skiplist。
- zset应用场景
- 粉丝列表:value(粉丝ID),score(关注时间),这样可以轻松按关注事件排序
- 学生成绩:value(学生ID),score(考试成绩),这样可以轻松对成绩排序
Redis 对五大数据类型的操作
Redis 对String操作
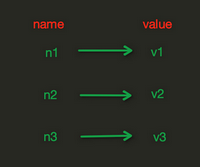
- redis中的String在内存存储样式
- 注:String操作,redis中的String在在内存中按照一个name对应一个value字典形式来存储
- set(name, value, ex=None, px=None, nx=False, xx=False)
- ex,过期时间(秒)
- px,过期时间(毫秒)
- nx,如果设置为True,则只有name不存在时,当前set操作才执行
- xx,如果设置为True,则只有name存在时,当前set操作才执行
import redis
r = redis.Redis(host='1.1.1.3', port=6379) #1、打印这个Redis缓存所有key以列表形式返回:[b'name222', b'foo']
print( r.keys() ) # keys * #2、清空redis
r.flushall() #3、设置存在时间: ex=1指这个变量只会存在1秒,1秒后就不存在了
r.set('name', 'Alex') # ssetex name Alex
r.set('name', 'Alex',ex=1) # ssetex name 1 Alex #4、获取对应key的value
print(r.get('name')) # get name #5、删除指定的key
r.delete('name') # del 'name' #6、避免覆盖已有的值: nx=True指只有当字典中没有name这个key才会执行
r.set('name', 'Tom',nx=True) # setnx name alex #7、重新赋值: xx=True只有当字典中已经有key值name才会执行
r.set('name', 'Fly',xx=True) # set name alex xx #8、psetex(name, time_ms, value) time_ms,过期时间(数字毫秒 或 timedelta对象)
r.psetex('name',10,'Tom') # psetex name 10000 alex #10、mset 批量设置值; mget 批量获取
r.mset(key1='value1', key2='value2') # mset k1 v1 k2 v2 k3 v3
print(r.mget({'key1', 'key2'})) # mget k1 k2 k3 #11、getset(name, value) 设置新值并获取原来的值
print(r.getset('age','')) # getset name tom #12、getrange(key, start, end) 下面例子就是获取name值abcdef切片的0-2间的字符(b'abc')
r.set('name','abcdef')
print(r.getrange('name',0,2)) #13、setbit(name, offset, value) #对name对应值的二进制表示的位进行操作
r.set('name','abcdef')
r.setbit('name',6,1) #将a(1100001)的第二位值改成1,就变成了c(1100011)
print(r.get('name')) #最后打印结果:b'cbcdef' #14、bitcount(key, start=None, end=None) 获取name对应的值的二进制表示中 1 的个数 #15、incr(self,name,amount=1) 自增 name对应的值,当name不存在时,则创建name=amount,否则自增 #16、derc 自动减1:利用incr和derc可以简单统计用户在线数量
#如果以前有count就在以前基础加1,没有就第一次就是1,以后每运行一次就自动加1
num = r.incr('count') #17、num = r.decr('count') #每运行一次就自动减1
#每运行一次incr('count')num值加1每运行一次decr后num值减1
print(num) #18、append(key, value) 在redis name对应的值后面追加内容
r.set('name','aaaa')
r.append('name','bbbb')
print(r.get('name')) #运行结果: b'aaaabbbb'
Redis对string操作
- 使用setbit()和bitcount()实现最高效的统计大数量用户在线
- 1. setbit()和bitcount()各自作用
- setbit()可以任意指定一个key的第多少位是1或者0(比如:setbit n 1 1 设置n的第一位是1)
- bitcount() 可以统计某个key中共有多少个1 (比如: bitcount n 就会返回n中二进制1的个数)
- 每个用户都会存储在数据库中,并且每个条目都会对应一个id值
- 2. 原理:(这里是在Redis命令行中做的测试)
- 根据上面三条特点可以高效统计用户在线数量以及确定某个用户是否在线
- 方法是当用户登录后就将其对应的id位设置成1
- 比如:tom用户在数据库中id=100,那么tom登录后就可以设置键的第一百位为1(setbit n 100 1)
- 统计在线数量: bitcount n (可以后取到key值n中以的数量)
- 确定某用户是否在线:比如用户在数据库中id=100getbit n 100
- 就可以返回n的第一百位是1就是在线,是0就是不在线
- 1. setbit()和bitcount()各自作用
import redis
r = redis.Redis(host='10.1.0.51', port=6379) r.setbit('n',10,1) #设置n的第十位是二进制的1
print(r.getbit('n',10)) #获取n的第十位是1还是0(id=10用户是否在线)
print(r.bitcount('n')) #统计那种共有多上个1(用户在线数量)
使用python的Redis模块实现统计用户在线情况
Redis 对 Hash操作
- redis中的Hash在内存存储样式
- 注: hash在内存中存储可以不像string中那样必须是字典,可以一个键对应一个字典
- Redis对Hash字典操作举例
import redis
pool = redis.ConnectionPool(host='1.1.1.3', port=6379) r = redis.Redis(connection_pool=pool)
#1 hset(name, key, value) name=字典名字,key=字典key,value=对应key的值
r.hset('info','name','tom') # hset info name tom
r.hset('info','age','')
print(r.hgetall('info')) # hgetall info {b'name': b'tom', b'age': b'100'}
print(r.hget('info','name')) # hget info name b'tom' print(r.hkeys('info')) #打印出”info”对应的字典中的所有key [b'name', b'age']
print(r.hvals('info')) #打印出”info”对应的字典中的所有value [b'tom', b'100'] #2 hmset(name, mapping) 在name对应的hash中批量设置键值对
r.hmset('info2', {'k1':'v1', 'k2': 'v2','k3':'v3'}) #一次性设置多个值
print(r.hgetall('info2')) #hgetall() 一次性打印出字典中所有内容
print(r.hget('info2','k1')) #打印出‘info2’对应字典中k1对应的value
print(r.hlen('info2')) # 获取name对应的hash中键值对的个数
print(r.hexists('info2','k1')) # 检查name对应的hash是否存在当前传入的key
r.hdel('info2','k1') # 将name对应的hash中指定key的键值对删除
print(r.hgetall('info2')) #3 hincrby(name, key, amount=1)自增name对应的hash中的指定key的值,不存在则创建key=amount
r.hincrby('info2','k1',amount=10) #第一次赋值k1=10以后每执行一次值都会自动增加10
print(r.hget('info2','k1')) #4 hscan(name, cursor=0, match=None, count=None)对于数据大的数据非常有用,hscan可以实现分片的获取数据
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
print(r.hscan('info2',cursor=0,match='k*')) #打印出所有key中以k开头的
print(r.hscan('info2',cursor=0,match='*2*')) #打印出所有key中包含2的 #5 hscan_iter(name, match=None, count=None)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
for item in r.hscan_iter('info2'):
print(item)
Redis对Hash字典操作
Redis 对List操作
- redis中的List在在内存中按照一个name对应一个List来存储
- redis对列表操作举例
import redis
pool = redis.ConnectionPool(host='10.1.0.51', port=6379) r = redis.Redis(connection_pool=pool) #1 lpush:反向存放 rpush正向存放数据
r.lpush('names','alex','tom','jack') # 从右向左放数据比如:3,2,1(反着放)
print(r.lrange('names',0,-1)) # 结果:[b'jack', b'tom']
r.rpush('names','zhangsan','lisi') #从左向右放数据如:1,2,3(正着放)
print(r.lrange('names',0,-1)) #结果:b'zhangsan', b'lisi'] #2.1 lpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表最左边
#2.2 rpushx(name, value) 表示从右向左操作 #3 llen(name) name对应的list元素的个数
print(r.llen('names')) #4 linsert(name, where, refvalue, value)) 在name对应的列表的某一个值前或后插入一个新值
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.rpush('name2','zhangsan','lisi') #先创建列表[zhangsan,lisi]
print(r.lrange('name2',0,-1))
r.linsert('name2','before','zhangsan','wangwu') #在张三前插入值wangwu
r.linsert('name2','after','zhangsan','zhaoliu') #在张三前插入值zhaoliu
print(r.lrange('name2',0,-1)) #5 r.lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值
r.rpush('name3','zhangsan','lisi') #先创建列表[zhangsan,lisi]
r.lset('name3',0,'ZHANGSAN') #将索引为0的位置值改成'ZHANGSAN'
print(r.lrange('name3',0,-1)) #最后结果:[b'ZHANGSAN', b'lisi'] #6 r.lrem(name, value, num) 在name对应的list中删除指定的值
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
r.rpush('name4','zhangsan','zhangsan','zhangsan','lisi')
r.lrem('name4','zhangsan',1)
print(r.lrange('name4',0,-1)) #7 lpop(name) 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
r.rpush('name5','zhangsan','lisi')
r.rpop('name5')
print(r.lrange('name5',0,-1)) #8 lindex(name, index) 在name对应的列表中根据索引获取列表元素
r.rpush('name6','zhangsan','lisi')
print(r.lindex('name6',1)) #9 lrange(name, start, end) 在name对应的列表分片获取数据
r.rpush('num',0,1,2,3,4,5,6)
print(r.lrange('num',1,3)) #10 ltrim(name, start, end) 在name对应的列表中移除没有在start-end索引之间的值
r.rpush('num1',0,1,2,3,4,5,6)
r.ltrim('num1',1,2)
print(r.lrange('num1',0,-1)) #11 rpoplpush(src, dst) 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
r.rpush('num2',0,1,2,3)
r.rpush('num3',100)
r.rpoplpush('num2','num3')
print(r.lrange('num3',0,-1)) #运行结果:[b'3', b'100'] #12 blpop(keys, timeout) 将多个列表排列,按照从左到右去pop对应列表的元素
#timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
r.rpush('num4',0,1,2,3)
r.blpop('num4',10)
print(r.lrange('num4',0,-1))
redis对列表操作举例
redis对Set集合操作,Set集合就是不允许重复的列表
import redis
r = redis.Redis(host='10.1.0.51', port=6379) #1 sadd(name,values) name对应的集合中添加元素
#2 scard(name) 获取name对应的集合中元素个数
r.sadd('name0','alex','tom','jack')
print(r.scard('name0')) #3 sdiff(keys, *args) 在第一个name对应的集合中且不在其他name对应的集合的元素集合
r.sadd('num6',1,2,3,4)
r.sadd('num7',3,4,5,6) #在num6中有且在num7中没有的元素
print(r.sdiff('num6','num7')) #运行结果:{b'1', b'2'} #4 sdiffstore(dest, keys, *args)
#获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
# 将在num7中不在num8中的元素添加到num9
r.sadd('num7',1,2,3,4)
r.sadd('num8',3,4,5,6)
r.sdiffstore('num9','num7','num8')
print(r.smembers('num9')) #运行结果: {b'1', b'2'} #5 sinter(keys, *args) 获取多一个name对应集合的交集
r.sadd('num10',4,5,6,7,8)
r.sadd('num11',1,2,3,4,5,6)
print(r.sinter('num10','num11')) #运行结果: {b'4', b'6', b'5'} #6 sinterstore(dest, keys, *args) 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
r.sadd('num12',1,2,3,4)
r.sadd('num13',3,4,5,6)
r.sdiffstore('num14','num12','num13')
print(r.smembers('num14')) #运行结果: {b'1', b'2'} #7 sismember(name, value) 检查value是否是name对应的集合的成员
r.sadd('name22','tom','jack')
print(r.sismember('name22','tom')) #8 smove(src, dst, value) 将某个成员从一个集合中移动到另外一个集合
r.sadd('num15',1,2,3,4)
r.sadd('num16',5,6)
r.smove('num15','num16',1)
print(r.smembers('num16')) #运行结果: {b'1', b'5', b'6'} #9 spop(name) 从集合的右侧(尾部)移除一个成员,并将其返回
r.sadd('num17',4,5,6)
print(r.spop('num17')) #10 srandmember(name, numbers) 从name对应的集合中随机获取 numbers 个元素
r.sadd('num18',4,5,6)
print(r.srandmember('num18',2)) #11 srem(name, values) 在name对应的集合中删除某些值
r.sadd('num19',4,5,6)
r.srem('num19',4)
print(r.smembers('num19')) #运行结果: {b'5', b'6'} #12 sunion(keys, *args) 获取多一个name对应的集合的并集
r.sadd('num20',3,4,5,6)
r.sadd('num21',5,6,7,8)
print(r.sunion('num20','num21')) #运行结果: {b'4', b'5', b'7', b'6', b'8', b'3'} #13 sunionstore(dest,keys, *args)
# 获取多个name对应的集合的并集,并将结果保存到dest对应的集合中
r.sunionstore('num22','num20','num21')
print(r.smembers('num22')) #运行结果: {b'5', b'7', b'3', b'8', b'6', b'4'} #14 sscan(name, cursor=0, match=None, count=None)
# sscan_iter(name, match=None, count=None)
#同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
redis对Set集合操作
redis对有序集合操作
- 对有序集合使用介绍
- 有序集合,在集合的基础上,为每元素排序
- 元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序
- redis操作有序集合举例
import redis
pool = redis.ConnectionPool(host='10.1.0.51', port=6379)
r = redis.Redis(connection_pool=pool) #1 zadd(name, *args, **kwargs) 在name对应的有序集合中添加元素
r.zadd('zz', n1=11, n2=22,n3=15)
print(r.zrange('zz',0,-1)) #[b'n1', b'n3', b'n2']
print(r.zrange('zz',0,-1,withscores=True)) #[(b'n1', 11.0), (b'n3', 15.0), (b'n2', 22.0)] #2 zcard(name) 获取name对应的有序集合元素的数量 #3 zcount(name, min, max) 获取name对应的有序集合中分数 在 [min,max] 之间的个数
r.zadd('name01', tom=11,jack=22,fly=15)
print(r.zcount('name01',1,20)) #4 zincrby(name, value, amount) 自增name对应的有序集合的 name 对应的分数 #5 zrank(name, value) 获取某个值在 name对应的有序集合中的排行(从 0 开始)
r.zadd('name02', tom=11,jack=22,fly=15)
print(r.zrank('name02','fly')) #6 zrem(name, values) 删除name对应的有序集合中值是values的成员
r.zadd('name03', tom=11,jack=22,fly=15)
r.zrem('name03','fly')
print(r.zrange('name03',0,-1)) # [b'tom', b'jack'] #7 zremrangebyrank(name, min, max)根据排行范围删除
r.zadd('name04', tom=11,jack=22,fly=15)
r.zremrangebyrank('name04',1,2)
print(r.zrange('name04',0,-1)) # [b'tom'] #8 zremrangebyscore(name, min, max) 根据分数范围删除
r.zadd('name05', tom=11,jack=22,fly=15)
r.zremrangebyscore('name05',1,20)
print(r.zrange('name05',0,-1)) #9 zremrangebylex(name, min, max) 根据值返回删除 #10 zscore(name, value) 获取name对应有序集合中 value 对应的分数 #11 zinterstore(dest, keys, aggregate=None) #11测试过代码报错,未解决
#获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
r.zadd('name09', tom=11,jack=22,fly=15)
r.zadd('name10', tom=12,jack=23,fly=15)
r.zinterstore('name11',2,'name09','name10')
print(r.zrange('name11',0,-1))
redis操作有序集合
# 127.0.0.1:6379> zadd name222 11 zhangsan 12 lisi
(integer) 2 # 127.0.0.1:6379> zrange name222 0 -1
1) "zhangsan"
2) "lisi" # 127.0.0.1:6379> zadd name333 11 zhangsan 12 lisi
(integer) 2 # 127.0.0.1:6379> zrange name333 0 -1
1) "zhangsan"
2) "lisi" # 127.0.0.1:6379> zinterstore name444 2 name222 name333
(integer) 2 # 127.0.0.1:6379> zrange name444 0 -1 withscores
1) "zhangsan"
2) ""
3) "lisi"
4) ""
redis操作有序集合在命令行测试
redis其他常用操作
- redis其它命令
import redis
pool = redis.ConnectionPool(host='1.1.1.3', port=6379)
r = redis.Redis(connection_pool=pool) #1 查看当前Redis所有key
print(r.keys('*')) #2 delete(*names) 删除Redis对应的key的值
r.delete('num16') #3 exists(name) 检测redis的name是否存在
print(r.exists('name09')) #4 keys(pattern='*') 根据模型获取redis的name
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
print(r.keys(pattern='name*')) #打印出Redis中所有以name开通的key #5 expire(name ,time) 为某个redis的某个name设置超时时间
r.expire('name09',1) # 1秒后就会删除这个key值name09 #6 rename(src, dst) 对redis的name重命名为
r.rename('num13','num13new')
redis其他命令
- redis中切换数据库操作
# redis 127.0.0.1:6379> SET db_number 0 # 默认使用 0 号数据库 # redis 127.0.0.1:6379> SELECT 1 # 使用 1 号数据库 # redis 127.0.0.1:6379[1]> GET db_number # 已经切换到 1 号数据库,注意 Redis 现在的命令提符多了个 [1] # redis 127.0.0.1:6379[1]> SET db_number 1 # 设置默认使用 1 号数据库 # redis 127.0.0.1:6379[1]> GET db_number # 获取当前默认使用的数据库号 #1 move(name, db)) 将redis的某个值移动到指定的db下(对方库中有就不移动)
127.0.0.1:6379> move name0 4 #2 type(name) 获取name对应值的类型
127.0.0.1:6379[4]> type name0
redis中切换数据库操作
redis的管道使用(通过管道向指定db传送数据)
- 管道作用
- redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作
- 如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令
- 通过管道向指定db传送数据
import redis,time
pool = redis.ConnectionPool(host='10.1.0.51', port=6379,db=5)
r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True) pipe.set('name', 'alex')
time.sleep(4)
pipe.set('role', 'sb') pipe.execute() #只有执行这里上面两条才会一起执行,才能到db5中看到这两个值 # 127.0.0.1:6379[5]> select 5
# OK
# 127.0.0.1:6379[5]> keys *
# 1) "name"
# 2) "role"
通过管道向指定db传送数据
发布订阅(一对多的广播)
- 作用图解
- 作用:发布订阅的作用就是在发布者(publish)中发送数据,可以在所有接收者(sub)中都可以接收到相同数据

- 发布订阅实例各文件讲解
- 这里的实例发布订阅包含以下三个文件:
- redisHelper.py : 定义了一个类,在类例规定了如何发布,如何订阅,和频道是多少
- RedisSub.py : Redis接收端,在这里直接导入redisHelper.py中定义的类,调用类中的接收数据的方法
- RedisPub.py : Redis发送端,在这里直接导入redisHelper.py中定义的类,调用类中的发送数据的方法
- 实验效果时,直接运行RedisSub.py,会卡在接收数据的地方,等待发送方发送数据
- 然后运行RedisPub.py进行发送数据,可以看到所有在运行的接收者RedisSub.py都可以接收到这个消息
- 这里的实例发布订阅包含以下三个文件:
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.1.0.51') #连接Redis服务器
self.chan_sub = 'fm104.5' #发布频道'fm104.5'
self.chan_pub = 'fm104.5' #接收频道也是'fm104.5'
#发消息
def public(self, msg):
self.__conn.publish(self.chan_pub, msg) #直接调用Redis的chan_pub方法发消息
print('pub')
return True
#收消息
def subscribe(self):
print('sub')
pub = self.__conn.pubsub() #开始订阅,仅仅相当于打开收音机
pub.subscribe(self.chan_sub) #调频道
pub.parse_response() #准备接收
return pub #再调用一次pub.parse_response()才会接收
1、redisHelper.py : 定义如何发布接收的类
from redisHelper import RedisHelper #这里的RedisHelper()就是redisHelper中定义的类
obj = RedisHelper() #实例化一个对象RedisHelper
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response() #如果Public发送有数据就打印,没有就卡住
print(msg)
2、RedisSub.py : Redis接收端
from redisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')
3、RedisPub.py : Redis发送端
Redis 主从同步
- CPA原理
- CPA原理是分布式存储理论的基石: C(一致性); A(可用性); P(分区容忍性);
- 当主从网络无法连通时,修改操作无法同步到节点,所以“一致性”无法满足
- 除非我们牺牲“可用性”,也就是暂停分布式节点服务,不再提供修改数据功能,知道网络恢复
- 一句话概括CAP: 当网络分区发生时,一致性 和 可用性 两难全
- redis主从同步介绍
- 和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。
- 为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构。
- Redis主从复制可以根据是否是全量分为全量同步和增量同步。
- 注:redis主节点Master挂掉时,运维让从节点Slave接管(redis主从默认无法自动切换,需要运维手动切换)
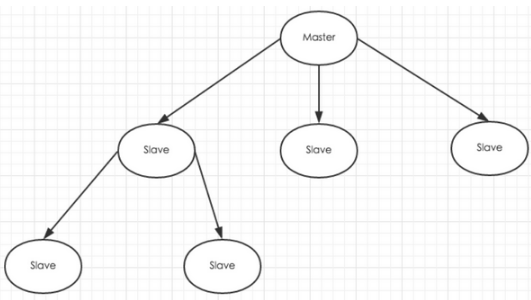
- 全量同步(快照同步)
- 注:Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
- 完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。

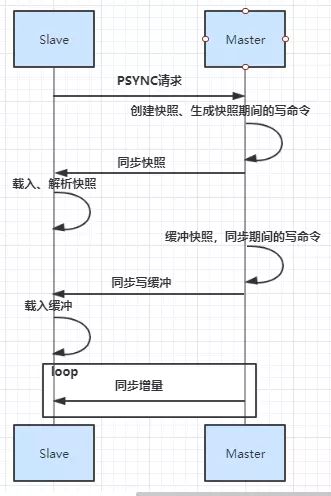
- 增量同步
- 主节点会将那些对自己状态产生修改性影响的指令记录在本地内存buffer中,然后异步将buffer中指令同步到从节点
- 从节点一边执行同步指令达到主节点状态,一边向主节点反馈自己同步到哪里(偏移量)
- 当网络状态不好时,从节点无法和主节点进行同步,当网络恢复时需要进行快照同步
- Redis主从同步策略
- 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
- 当然,如果有需要,slave 在任何时候都可以发起全量同步。
- redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
- 注意点
- 如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。
- 部分复制
- 当从节点正在复制主节点时,如果出现网络闪断和其他异常,从节点会让主节点补发丢失的命令数据,主节点只需要将复制缓冲区的数据发送到从节点就能够保证数据的一致性,相比较全量复制,成本小很多。
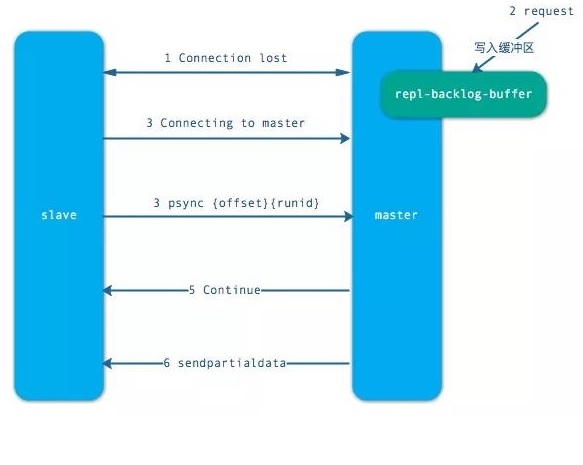
- 当从节点出现网络中断,超过了 repl-timeout 时间,主节点就会中断复制连接。
- 主节点会将请求的数据写入到“复制积压缓冲区”,默认 1MB。
- 当从节点恢复,重新连接上主节点,从节点会将 offset 和主节点 id 发送到主节点。
- 主节点校验后,如果偏移量的数后的数据在缓冲区中,就发送 cuntinue 响应 —— 表示可以进行部分复制。
- 主节点将缓冲区的数据发送到从节点,保证主从复制进行正常状态。
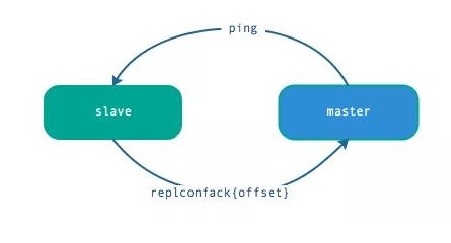
- 心跳
- 主从节点在建立复制后,他们之间维护着长连接并彼此发送心跳命令。
- 心跳的关键机制如下:
- 中从都有心跳检测机制,各自模拟成对方的客户端进行通信,通过 client list 命令查看复制相关客户端信息,主节点的连接状态为 flags = M,从节点的连接状态是 flags = S。
- 主节点默认每隔 10 秒对从节点发送 ping 命令,可修改配置 repl-ping-slave-period 控制发送频率。
- 从节点在主线程每隔一秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量。
- 主节点收到 replconf 信息后,判断从节点超时时间,如果超过 repl-timeout 60 秒,则判断节点下线。
- 注意:
- 为了降低主从延迟,一般把 redis 主从节点部署在相同的机房/同城机房,避免网络延迟带来的网络分区造成的心跳中断等情况。
- 注意:
异步复制
- 主节点不但负责数据读写,还负责把写命令同步给从节点,写命令的发送过程是异步完成,也就是说主节点处理完写命令后立即返回客户度,并不等待从节点复制完成。
- 异步复制的步骤很简单,如下:
- 主节点接受处理命令。
- 主节点处理完后返回响应结果 。
- 对于修改命令,异步发送给从节点,从节点在主线程中执行复制的命令。
Redis 哨兵(sentinel)模式
- 哨兵模式介绍
- Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态
- 在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用(HA)
- 其已经被集成在redis2.6+的版本中,Redis的哨兵模式到了2.8版本之后就稳定了下来
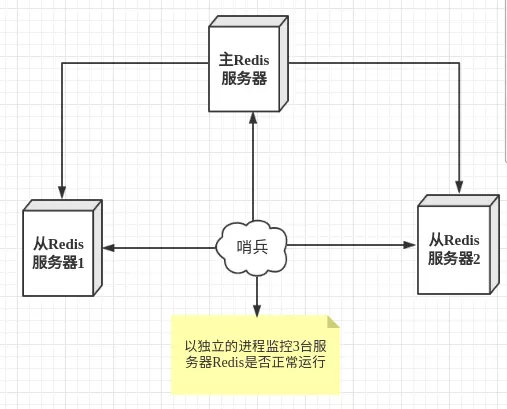
- sentinel作用
- 当用Redis做主从方案时,假如master宕机,Redis本身无法自动进行主备切换
- 而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
- 哨兵进程的作用
- 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
- 提醒(Notification):当被监控的某个Redis节点出现问题时哨兵(sentinel) 可以通过 API向管理员或者其他应用程序发送知。
- 自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作。
- 它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master;
- 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用现在的Master替换失效Master。
- Master和Slave服务器切换后,Master的redis.conf、Slave的redis.conf和sentinel.conf的配置文件的内容都会发生相应的改变,即,Master主服务器的redis.conf配置文件中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
- 哨兵进程的工作方式
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值,则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)。
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有
- Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
- 在一般情况下, 每个Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
- sentinel原理
- sentinel负责持续监控主节点的健康,当主节挂掉时,自动选择一个最优的从节点切换成主节点
- 从节点来连接集群时会首先连接sentinel,通过sentinel来查询主节点的地址
- 当主节点发生故障时,sentinel会将最新的主节点地址告诉客户端,可以实现无需重启自动切换redis
- Sentinel支持集群
- 只使用单个sentinel进程来监控redis集群是不可靠的,当sentinel进程宕掉后sentinel本身也有单点问题
- 如果有多个sentinel,redis的客户端可以随意地连接任意一个sentinel来获得关于redis集群中的信息。
- Sentinel版本
- Sentinel当前稳定版本称为Sentinel 2,Redis2.8和Redis3.0附带稳定的哨兵版本
- 安装完redis-3.2.8后,redis-3.2.8/src/redis-sentinel启动程序 redis-3.2.8/sentinel.conf是配置文件。
- 运行sentinel两种方式(效果相同)
- 法1:redis-sentinel /path/to/sentinel.conf
- 法2:redis-server /path/to/sentinel.conf --sentinel
- 以上两种方式,都必须指定一个sentinel的配置文件sentinel.conf,如果不指定,将无法启动sentinel。
- sentinel默认监听26379端口,所以运行前必须确定该端口没有被别的进程占用。
- sentinel.conf配置文件说明
- 配置文件只需要配置master的信息就好啦,不用配置slave的信息,因为slave能够被自动检测到
- 需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。
- 这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
# sentinel.conf 配置说明
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1 '''1、sentinel monitor mymaster 127.0.0.1 6379 2'''
#1)sentinel监控的master的名字叫做mymaster,地址为127.0.0.1:6379
#2)当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了 '''2、sentinel down-after-milliseconds mymaster 60000'''
#1)sentinel会向master发送心跳PING来确认master是否存活,如果master在60000毫秒内不回应PONG
#2)那么这个sentinel会单方面地认为这个master已经不可用了 '''3、sentinel failover-timeout mymaster 180000'''
#1)如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,
#2)这个等待的时间是通过failover-timeout配置项去配置的。
#3)从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,
#4)第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。 '''4、sentinel parallel-syncs mymaster 1'''
#1)在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步
#2)如果这个数字越大,就意味着越多的slave因为replication而不可用,这个数字越小,完成failover所需的时间就越长。
#3)可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
sentinel.conf配置文件注释
- 配置传播
- 一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
- 一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送
SLAVE OF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。 - 当将一个slave选举为master并发送
SLAVE OF NO ONE`后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的。 - 因为每一个配置都有一个版本号,所以以版本号最大的那个为标准:
- 假设有一个名为mymaster的地址为192.168.1.50:6379。
- 一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。
- 一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。
- 如果failover成功了,假设地址改为了192.168.1.50:9000,此时配置的版本号为2
- 进行failover的sentinel会将新配置广播给其他的sentinel,发现新配置的版本号为2时,版本号变大了,
- 说明配置更新了,于是就会采用最新的版本号为2的配置。
- 安装和部署
- 部署拓扑结构
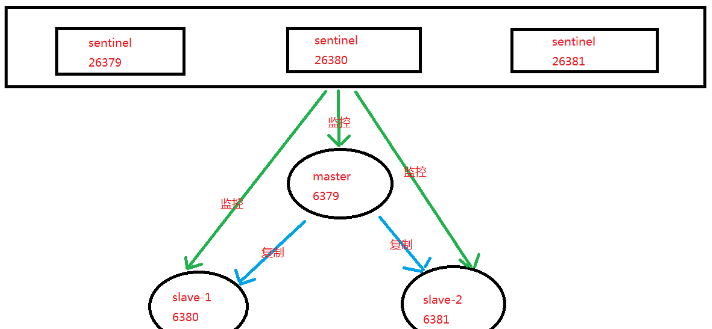
- 启动主节点
- 配置
# redis-6379.conf主要修改参数
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
- 启动
# ./redis-server redis-6379.conf
- 确认是否启动成功
#方式1:
# [root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379 ping
PONG # 方式2:
# [root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(empty list or set)
- 启动从节点
- 配置
# 从节点1 redis-6380.conf 主要修改参数
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 127.0.0.1 6379
# 从节点2 redis-6381.conf 主要修改参数
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 127.0.0.1 6379
- 启动
./redis-server redis-6380.conf
- 启动打印日志:
# ./redis-server redis-6381.conf
- 启动打印日志:
- 确认主从关系
# [root@localhost bin]# ./redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master #当前节点角色
connected_slaves:2 #从节点连接个数
slave0:ip=127.0.0.1,port=6380,state=online,offset=392,lag=1 #从节点连接信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=392,lag=2 #从节点连接信息
master_replid:6bc06103642acba6430e01ec78ef18ada4736649
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:392
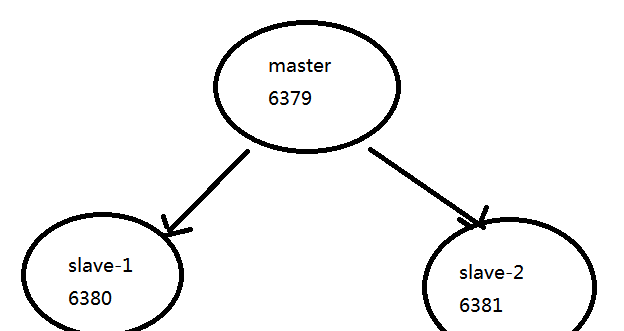
- 此时拓扑:
- 部署Sentinel节点
- 3个Sentinel节点的部署方法是完全一致的(端口不同)
- 配置
- 主要修改参数 修改端口 ,修改主节点连接信息,其他使用默认就行了,具体参数后面会介绍
# port 26379
# sentinel monitor mymaster 127.0.0.1 6379 1
- Sentinel节点的默认端口是26379
- 启动
# ./redis-sentinel sentinel-26379.conf # 方法二, 使用redis-server命令加–sentinel参数:
redis-server sentinel-26379.conf --sentinel
- 日志:
- 确认
- Sentinel节点本质上是一个特殊的Redis节点, 所以也可以通过info命令 来查询它的相关信息 。
# [root@localhost bin]# redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=1
- 其他两个配置是一样的
- 最终拓扑
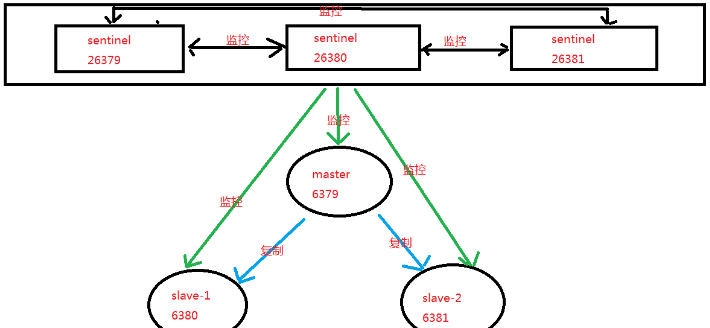
- 宕机测试
- 现在在master节点上执行,如下操作,演示通过redis sentinel 进行故障转移和新master的选出
# [root@localhost bin]# ./redis-cli shutdown
- 执行完上述操作后,三个哨兵打印的日志如下:
# 14549:X 24 Jul 15:44:44.568 # +vote-for-leader e31085285266ff86372eeeb4970c9a8de0471025 1
# 14549:X 24 Jul 15:44:44.604 # +sdown master mymaster 127.0.0.1 6379
# 14549:X 24 Jul 15:44:44.604 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
# 14549:X 24 Jul 15:44:44.604 # Next failover delay: I will not start a failover before Wed Jul 24 15:50:45 2019
# 14549:X 24 Jul 15:44:45.093 # +config-update-from sentinel e31085285266ff86372eeeb4970c9a8de0471025 127.0.0.1
26381 @ mymaster 127.0.0.1 6379
# 14549:X 24 Jul 15:44:45.093 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
# 14549:X 24 Jul 15:44:45.093 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
# 14549:X 24 Jul 15:44:45.093 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
# 14549:X 24 Jul 15:45:15.127 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
- 意思就是选择6381为新的master
- 如下日志是在,6379执行shutdown前后在6381节点上执行的操作:
127.0.0.1:6381> info replication
# Replication
role:slave ###6379节点正常是,6381为从节点
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:166451
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6bc06103642acba6430e01ec78ef18ada4736649
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:166451
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:253
repl_backlog_histlen:166199
127.0.0.1:6381> info replication
# Replication
role:master #执行shutdwon后成为新的master节点
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=217098,lag=1
master_replid:e39de2323e3ab0ff0eff1347ad1c65e2bd3fd917
master_replid2:6bc06103642acba6430e01ec78ef18ada4736649
master_repl_offset:217098
second_repl_offset:172878
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:253
repl_backlog_histlen:216846
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2 # 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000 # 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1 # 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了 # 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION #配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。 #通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
一个是事件的类型,
一个是事件的描述。
如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。 #通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh # 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。 # sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
Sentinel配置说明
codis
- 为什么会出现codis
- 在大数据高并发场景下,单个redis实例往往会无法应对
- 首先redis内存不易过大,内存太大会导致rdb文件过大,导致主从同步时间过长
- 其次在CPU利用率中上,单个redis实例只能利用单核,数据量太大,压力就会特别大
- 什么是codis
- codis是redis集群解决方案之一,codis是GO语言开发的代理中间件
- 当客户端向codis发送指令时,codis负责将指令转发给后面的redis实例来执行,并将返回结果转发给客户端
- codis部署方案
- 单个codis代理支撑的QPS比较有限,通过启动多个codis代理可以显著增加整体QPS
- 多codis还能起到容灾功能,挂掉一个codis代理还有很多codis代理可以继续服务
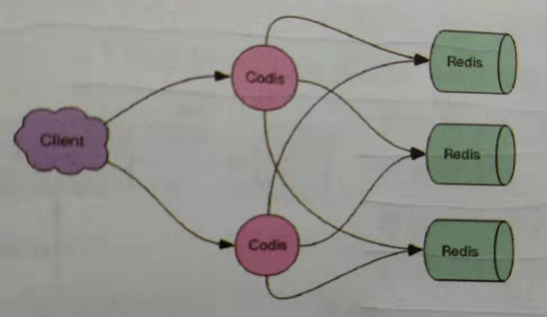
- codis分片的原理
- codis负责将特定key转发到特定redis实例,codis默认将所有key划分为1024个槽位
- 首先会对客户端传来的key进行crc32计算hash值,然后将hash后的整数值对1024进行取模,这个余数就是对应的key槽位
- 每个槽位都会唯一映射到后面的多个redis实例之一,codis会在内存中维护槽位和redis实例的映射关系
- 这样有了上面key对应的槽位,那么它应该转发到那个redis实例就很明确了
- 槽位数量默认是1024,如果集群中节点较多,建议将这个数值大一些,比如2048,4096
- 不同codis槽位如何同步
- 如果codis槽位值存在内存中,那么不同的codis实例间的槽位关系得不到同步
- 所以codis还需要一个分布式配置存储的数据库专门来持久化槽位关系
- codis将槽位关系存储在zookeeper中,并且提供一个dashboard可以来观察和修改槽位关系
布隆过滤器
- 布隆过滤器是什么?(判断某个key一定不存在)
- 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构
- 特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
- 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
- 使用:
- 布隆过滤器在NoSQL数据库领域中应用的非常广泛
- 当用户来查询某一个row时,可以先通过内存中的布隆过滤器过滤掉大量不存在的row请求,然后去再磁盘进行查询
- 布隆过滤器说某个值不存在时,那肯定就是不存在,可以显著降低数据库IO请求数量
- 应用场景
- 场景1(给用户推荐新闻)
- 当用户看过的新闻,肯定会被过滤掉,对于没有看多的新闻,可能会过滤极少的一部分(误判)。
- 这样可以完全保证推送给用户的新闻都是无重复的。
- 场景2(爬虫url去重)
- 在爬虫系统中,我们需要对url去重,已经爬取的页面不再爬取
- 当url高达几千万时,如果一个集合去装下这些URL地址非常浪费空间
- 使用布隆过滤器可以大幅降低去重存储消耗,只不过也会使爬虫系统错过少量页面
- 场景1(给用户推荐新闻)
- 布隆过滤器原理
- 每个布隆过滤器对应到Redis的数据结构是一个大型的数组和几个不一样的无偏hash函数
- 如下图:f、g、h就是这样的hash函数(无偏差指让hash映射到数组的位置比较随机)
添加:值到布隆过滤器
1)向布隆过滤器添加key,会使用 f、g、h hash函数对key算出一个整数索引,然后对长度取余
2)每个hash函数都会算出一个不同的位置,把算出的位置都设置成1就完成了布隆过滤器添加过程
查询:布隆过滤器值
1)当查询某个key时,先用hash函数算出一个整数索引,然后对长度取余
2)当你有一个不为1时肯定不存在这个key,当全部都为1时可能有这个key
3)这样内存中的布隆过滤器过滤掉大量不存在的row请求,然后去再磁盘进行查询,减少IO操作
删除:不支持
1)目前我们知道布隆过滤器可以支持 add 和 isExist 操作
2)如何解决这个问题,答案是计数删除,但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。
3)增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。

redis事物介绍
- redis事物是可以一次执行多个命令,本质是一组命令的集合。
- 一个事务中的所有命令都会序列化,按顺序串行化的执行而不会被其他命令插入
- 作用:一个队列中,一次性、顺序性、排他性的执行一系列命令
- redis事物基本使用
- 下面指令演示了一个完整的事物过程,所有指令在exec前不执行,而是缓存在服务器的一个事物队列中
- 服务器一旦收到exec指令才开始执行事物队列,执行完毕后一次性返回所有结果
- 因为redis是单线程的,所以不必担心自己在执行队列是被打断,可以保证这样的“原子性”
- 注:redis事物在遇到指令失败后,后面的指令会继续执行
- mysql的rollback与redis的discard的区别:
- mysql回滚为sql全部成功才执行,一条sql失败则全部失败,执行rollback后所有语句造成的影响消失
- redis的discard只是结束本次事务,正确命令造成的影响仍然还在.
# Multi 命令用于标记一个事务块的开始事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性( atomic )地执行
> multi(开始一个redis事物)
incr books
incr books
> exec (执行事物)
> discard (丢弃事物)
[root@redis ~]# redis-cli
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set test 123
QUEUED
127.0.0.1:6379> exec
1) OK
127.0.0.1:6379> get test
""
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set test 456
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get test
""
127.0.0.1:6379>
在命令行测试redis事物
#定义ip
host = 'localhost' #建立服务连接 r = redis.Redis(host=host)
pipe = r.pipeline() #开启事务
pipe.multi()
#存储子命令
pipe.set('key2', 4)
#执行事务
pipe.execute() print(r.get('key2'))
使用python测试redis事物
- Redis事务相关命令:
watch key1 key2 ... : 监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
multi : 标记一个事务块的开始( queued ) 事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性( atomic )地执行
exec : 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
discard : 取消事务,放弃事务块中的所有命令
unwatch : 取消watch对所有key的监控
- setnx:占坑
- watch指令
- 实质:WATCH 只会在数据被其他客户端抢先修改了的情况下通知执行命令的这个客户端(通过 WatchError 异常)但不会阻止其他客户端对数据的修改
- watch其实就是redis提供的一种乐观锁,可以解决并发修改问题
- watch会在事物开始前盯住一个或多个关键变量,当服务器收到exec指令要顺序执行缓存中的事物队列时
- redis会检查关键变量自watch后是否被修改(包括当前事物所在的客户端)
- 如果关键变量被人改动过,exec指令就会返回null回复告知客户端事物执行失败,这个时候客户端会选择重试
- 注:redis禁用在multi和exec之间执行watch指令,必须在multi之前盯住关键变量,否则会出错
Redis事务的三个阶段:
开始事务
Redis事务的开始是通过执行MULTI 命令来实现,它的作用是将执行该命令的客户端从非事务状态切换至事务状态
命令入队
当一个客户端出于事务状态时, 如果客户端发送的命令是 EXEC(执行所有事务块内的命令) 、DISCARD(取消事务,放弃执行事务块内的所有命令。) 、 WATCH(监视任意数量的key ,提一下,在事务中执行这个命令会报错:ERR WATCH inside MULTI is not allowed) 、 MULTI(标记一个事务块的开始) 四个命令以外的其他命令,那么服务器并不立即执行这个命令,而是将这个命令放入一个事务队列里面, 然后向客户端返回 QUEUED 回复。
执行事务
当一个处于事务状态的客户端向服务器发送 EXEC 命令时, 这个 EXEC 命令将立即被服务器执行: 服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。(这里需要说明的一点是,Redis在处理网络请求的是单线程的,所以队列中的命令在执行期间是不会被其他客户端命令插进来的。这一点对理解Redis事务很关键)
WATCH
用于事务开启之前对任意数量的Key进行监视,如果这个被监视的key被改动(这里提一下,这个改动,不管是删除、添加、修改,或者A -> B -> A改回原值,都会被认为发生了改动),那么相应事务就被取消,否则事务正常执行。所以我们可以认为 WATCH 是一个乐观锁。如果想让key取消被监控,可以用 UNWATCH 命令(这里又要提一下,UNWATCH 如果在事务中执行,也是会被放到队列里的)。
redis事物与分布式锁
- redis事物
- 严格意义来讲,Redis的事务和我们理解的传统数据库(如mysql)的事务是不一样的;
- Redis的事务实质上是命令的集合,在一个事务中要么所有命令都被执行,要么所有命令都不执行。
- 需要注意的是:
- Redis的事务没有关系数据库事务提供的回滚(rollback),所以开发者必须在事务执行失败后进行后续的处理;
- 如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
- 如果在一个事务中出现运行错误,那么正确的命令会被执行。
- 需要注意的是:
- redis原子操作
- 原子操作是指不会被线程调度机制打断的操作
- 这种操作一旦开始,就会一直运行到结束,中间不会切换任何进程
- 分布式锁
- 分布式锁本质是占一个坑,当别的进程也要来占坑时发现已经被占,就会放弃或者稍后重试
- 占坑一般使用 setnx(set if not exists)指令,只允许一个客户端占坑
- 先来先占,用完了在调用del指令释放坑
# > setnx lock:codehole true
# .... do something critical ....
# > del lock:codehole
- 但是这样有一个问题,如果逻辑执行到中间出现异常,可能导致del指令没有被调用,这样就会陷入死锁,锁永远无法释放
- 为了解决死锁问题,我们拿到锁时可以加上一个expire过期时间,这样即使出现异常,当到达过期时间也会自动释放锁
# > setnx lock:codehole true
# > expire lock:codehole 5
# .... do something critical ....
# > del lock:codehole
- 这样又有一个问题,setnx和expire是两条指令而不是原子指令,如果两条指令之间进程挂掉依然会出现死锁
- 为了治理上面乱象,在redis 2.8中加入了set指令的扩展参数,使setnx和expire指令可以一起执行
# > set lock:codehole true ex 5 nx
# ''' do something '''
# > del lock:codehole
分布式锁举例
分布式锁,是一种思想,它的实现方式有很多。比如,我们将沙滩当做分布式锁的组件,那么它看起来应该是这样的:
加锁
加锁实际上就是在redis中,给Key键设置一个值,为避免死锁,并给定一个过期
在沙滩上踩一脚,留下自己的脚印,就对应了加锁操作。其他进程或者线程,看到沙滩上已经有脚印,证明锁已被别人持有,则等待。
解锁
解锁的过程就是将Key键删除。但也不能乱删
把脚印从沙滩上抹去,就是解锁的过程。
锁超时
为了避免死锁,我们可以设置一阵风,在单位时间后刮起,将脚印自动抹去。
对于分布式锁,注意的
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行这把锁要是一把可重入锁(避免死锁)这把锁最好是一把阻塞锁有高可用的获取锁和释放锁功能获取锁和释放锁的性能要好
redis雪崩&穿透&击穿
- 把redis作为缓存使用已经是司空见惯但是使用redis后也可能会碰到一系列的问题,尤其是数据量很大的时候,经典的几个问题如下:
- 缓存和数据库间数据一致性问题
- 分布式环境下(单机就不用说了)非常容易出现缓存和数据库间的数据一致性问题,针对这一点的话,只能说,如果你的项目对缓存的要求是强一致性的,那么请不要使用缓存。我们只能采取合适的策略来降低缓存和数据库间数据不一致的概率,而无法保证两者间的强一致性。合适的策略包括 合适的缓存更新策略,更新数据库后要及时更新缓存、缓存失败时增加重试机制,例如MQ模式的消息队列。
- 缓存穿透
- 定义
- 缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,接着查询数据库也无法查询出结果,
- 虽然也不会写入到缓存中,但是这将会导致每个查询都会去请求数据库,造成缓存穿透;
- 解决方法 :布隆过滤
- 对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。可以给key设置一些格式规则,然后查询之前先过滤掉不符合规则的Key。
- 定义
- 缓存雪崩
- 定义
- 缓存雪崩是指,由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服务
- 于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
- 解决方法
- 保证缓存层服务高可用性:比如 Redis Sentinel 和 Redis Cluster 都实现了高可用
- 依赖隔离组件为后端限流并降级:比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 方案1、也是像解决缓存穿透一样加锁排队,实现同上;
- 方案2、建立备份缓存,缓存A和缓存B,A设置超时时间,B不设值超时时间,先从A读缓存,A没有读B,并且更新A缓存和B缓存;
- 方案3、设置缓存超时时间的时候加上一个随机的时间长度,比如这个缓存key的超时时间是固定的5分钟加上随机的2分钟,酱紫可从一定程度上避免雪崩问题;
- 定义
public String getByKey(String keyA,String keyB) {
String value = redisService.get(keyA);
if (StringUtil.isEmpty(value)) {
value = redisService.get(keyB);
String newValue = getFromDbById();
redisService.set(keyA,newValue,31, TimeUnit.DAYS);
redisService.set(keyB,newValue);
}
return value;
}
- 缓存击穿
- 定义:
- 缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况
- 当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
- 解决方法
- 解决方式也很简单,可以将热点数据设置为永远不过期;
- 或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
- 方案1、使用互斥锁排队
- 定义:
- 业界比价普遍的一种做法,即根据key获取value值为空时,锁上,从数据库中load数据后再释放锁。若其它线程获取锁失败,则等待一段时间后重试。这里要注意,分布式环境中要使用分布式锁,单机的话用普通的锁(synchronized、Lock)就够了。
public String getWithLock(String key, Jedis jedis, String lockKey, String uniqueId, long expireTime) {
// 通过key获取value
String value = redisService.get(key);
if (StringUtil.isEmpty(value)) {
// 分布式锁,详细可以参考https://blog.csdn.net/fanrenxiang/article/details/79803037
//封装的tryDistributedLock包括setnx和expire两个功能,在低版本的redis中不支持
try {
boolean locked = redisService.tryDistributedLock(jedis, lockKey, uniqueId, expireTime);
if (locked) {
value = userService.getById(key);
redisService.set(key, value);
redisService.del(lockKey);
return value;
} else {
// 其它线程进来了没获取到锁便等待50ms后重试
Thread.sleep(50);
getWithLock(key, jedis, lockKey, uniqueId, expireTime);
}
} catch (Exception e) {
log.error("getWithLock exception=" + e);
return value;
} finally {
redisService.releaseDistributedLock(jedis, lockKey, uniqueId);
}
}
return value;
}
- 这样做思路比较清晰,也从一定程度上减轻数据库压力,但是锁机制使得逻辑的复杂度增加,吞吐量也降低了,有点治标不治本。
- 方案2、接口限流与熔断、降级
- 重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
- 方案3、布隆过滤器
- bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,下面先来简单的实现下看看效果,我这里用guava实现的布隆过滤器:
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
</dependencies>
public class BloomFilterTest {
private static final int capacity = 1000000;
private static final int key = 999998;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
static {
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
}
public static void main(String[] args) {
/*返回计算机最精确的时间,单位微妙*/
long start = System.nanoTime();
if (bloomFilter.mightContain(key)) {
System.out.println("成功过滤到" + key);
}
long end = System.nanoTime();
System.out.println("布隆过滤器消耗时间:" + (end - start));
int sum = 0;
for (int i = capacity + 20000; i < capacity + 30000; i++) {
if (bloomFilter.mightContain(i)) {
sum = sum + 1;
}
}
System.out.println("错判率为:" + sum);
}
}
# 成功过滤到999998
# 布隆过滤器消耗时间:215518
# 错判率为:318
- 可以看到,100w个数据中只消耗了约0.2毫秒就匹配到了key,速度足够快。然后模拟了1w个不存在于布隆过滤器中的key,匹配错误率为318/10000,也就是说,出错率大概为3%,跟踪下BloomFilter的源码发现默认的容错率就是0.03:
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
# https://blog.csdn.net/fanrenxiang/article/details/80542580:详细操作
- 缓存并发
- 这里的并发指的是多个redis的client同时set key引起的并发问题。其实redis自身就是单线程操作,多个client并发操作,按照先到先执行的原则,先到的先执行,其余的阻塞。当然,另外的解决方案是把redis.set操作放在队列中使其串行化,必须的一个一个执行。
- 缓存预热
- 缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。
- 这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
- 解决思路:
- 1、直接写个缓存刷新页面,上线时手工操作下;
- 2、数据量不大,可以在项目启动的时候自动进行加载;
- 目的就是在系统上线前,将数据加载到缓存中。
Redis 项目缓存实现
- 关于redis为什么能作为缓存这个问题我们就不说了,直接来说一下redis缓存到底如何在项目中使用吧:
- 1.redis缓存如何在项目中配置?
- 1.1redis缓存单机版和集群版配置?(redis的客户端jedis常用)

<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.0.xsd">
<!-- 连接池配置 -->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大连接数 -->
<property name="maxTotal" value="30" />
<!-- 最大空闲连接数 -->
<property name="maxIdle" value="10" />
<!-- 每次释放连接的最大数目 -->
<property name="numTestsPerEvictionRun" value="1024" />
<!-- 释放连接的扫描间隔(毫秒) -->
<property name="timeBetweenEvictionRunsMillis" value="30000" />
<!-- 连接最小空闲时间 -->
<property name="minEvictableIdleTimeMillis" value="1800000" />
<!-- 连接空闲多久后释放, 当空闲时间>该值 且 空闲连接>最大空闲连接数 时直接释放 -->
<property name="softMinEvictableIdleTimeMillis" value="10000" />
<!-- 获取连接时的最大等待毫秒数,小于零:阻塞不确定的时间,默认-1 -->
<property name="maxWaitMillis" value="1500" />
<!-- 在获取连接的时候检查有效性, 默认false -->
<property name="testOnBorrow" value="true" />
<!-- 在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="true" />
<!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true -->
<property name="blockWhenExhausted" value="false" />
</bean>
<!-- jedis客户端单机版 -->
<bean id="redisClient" class="redis.clients.jedis.JedisPool">
<constructor-arg name="host" value="192.168.146.131"></constructor-arg>
<constructor-arg name="port" value="6379"></constructor-arg>
<constructor-arg name="poolConfig" ref="jedisPoolConfig"></constructor-arg>
</bean>
<bean id="jedisClient" class="com.taotao.rest.dao.impl.JedisClientSingle"/> <!-- jedis集群版配置 -->
<!-- <bean id="redisClient" class="redis.clients.jedis.JedisCluster">
<constructor-arg name="nodes">
<set>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7001"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7002"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7003"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7004"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7005"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.25.153"></constructor-arg>
<constructor-arg name="port" value="7006"></constructor-arg>
</bean>
</set>
</constructor-arg>
<constructor-arg name="poolConfig" ref="jedisPoolConfig"></constructor-arg>
</bean>
<bean id="jedisClientCluster" class="com.taotao.rest.dao.impl.JedisClientCluster"></bean> -->
</beans>
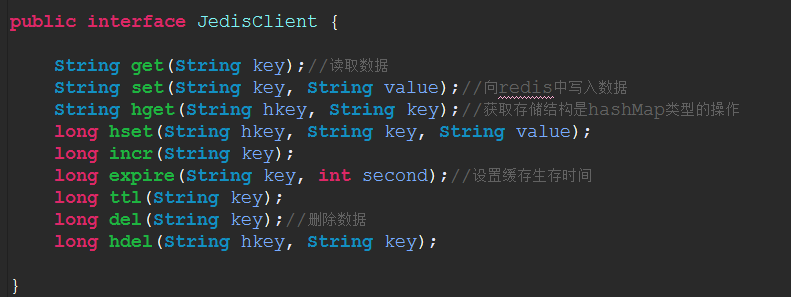
- 1.2redis的方法定义?
- 接口:
- 实现:分集群和单机版
- 单机版实现方法:
package com.taotao.rest.dao.impl; import org.springframework.beans.factory.annotation.Autowired; import com.taotao.rest.dao.JedisClient; import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool; public class JedisClientSingle implements JedisClient{ @Autowired
private JedisPool jedisPool; @Override
public String get(String key) {
Jedis jedis = jedisPool.getResource();
String string = jedis.get(key);
jedis.close();
return string;
} @Override
public String set(String key, String value) {
Jedis jedis = jedisPool.getResource();
String string = jedis.set(key, value);
jedis.close();
return string;
} @Override
public String hget(String hkey, String key) {
Jedis jedis = jedisPool.getResource();
String string = jedis.hget(hkey, key);
jedis.close();
return string;
} @Override
public long hset(String hkey, String key, String value) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.hset(hkey, key, value);
jedis.close();
return result;
} @Override
public long incr(String key) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.incr(key);
jedis.close();
return result;
} @Override
public long expire(String key, int second) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.expire(key, second);
jedis.close();
return result;
} @Override
public long ttl(String key) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.ttl(key);
jedis.close();
return result;
} @Override
public long del(String key) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.del(key);
jedis.close();
return result;
} @Override
public long hdel(String hkey, String key) {
Jedis jedis = jedisPool.getResource();
Long result = jedis.hdel(hkey, key);
jedis.close();
return result;
} }
- 集群版的实现方法:
package com.taotao.rest.dao.impl;
import org.springframework.beans.factory.annotation.Autowired;
import com.taotao.rest.dao.JedisClient;
import redis.clients.jedis.JedisCluster;
public class JedisClientCluster implements JedisClient {
@Autowired
private JedisCluster jedisCluster;
@Override
public String get(String key) {
return jedisCluster.get(key);
}
@Override
public String set(String key, String value) {
return jedisCluster.set(key, value);
}
@Override
public String hget(String hkey, String key) {
return jedisCluster.hget(hkey, key);
}
@Override
public long hset(String hkey, String key, String value) {
return jedisCluster.hset(hkey, key, value);
}
@Override
public long incr(String key) {
return jedisCluster.incr(key);
}
@Override
public long expire(String key, int second) {
return jedisCluster.expire(key, second);
}
@Override
public long ttl(String key) {
return jedisCluster.ttl(key);
}
@Override
public long del(String key) {
return jedisCluster.del(key);
}
@Override
public long hdel(String hkey, String key) {
return jedisCluster.hdel(hkey, key);
}
}
- 配置好后,如何添加到代码中呢?
- 2.redis缓存如何添加到业务逻辑代码中?
- redis作为缓存的作用就是减少对数据库的访问压力,当我们访问一个数据的时候,首先我们从redis中查看是否有该数据,如果没有,则从数据库中读取,将从数据库中读取的数据存放到缓存中,下次再访问同样的数据的是,还是先判断redis中是否存在该数据,如果有,则从缓存中读取,不访问数据库了。
- 举个例子:根据内容分类id访问内容:
package com.taotao.rest.service.impl; import java.util.ArrayList;
import java.util.List; import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service; import com.taotao.commonEntity.JsonUtils;
import com.taotao.commonEntity.TaotaoResult;
import com.taotao.mapper.TbContentMapper;
import com.taotao.pojo.TbContent;
import com.taotao.pojo.TbContentExample;
import com.taotao.pojo.TbContentExample.Criteria;
import com.taotao.rest.dao.JedisClient;
import com.taotao.rest.service.ContentService; import redis.clients.jedis.Jedis;
//首页大广告位的获取服务层信息
@Service
public class ContentServiceImpl implements ContentService { @Value("${CONTENTCATEGORYID}")
private String CONTENTCATEGORYID;
@Autowired
private TbContentMapper contentMapper;
@Autowired
private JedisClient jedisClient; @Override
public List<TbContent> getContentList(Long categoryId) {
/*一般第一次访问的时候先从数据库读取数据,然后将数据写入到缓存,再次访问同一内容的时候就从缓存中读取,如果缓存中没有则从数据库中读取
所以我们添加缓存逻辑的时候,从数据库中将内容读取出来之后,先set入缓存,然后再从缓存中添加读取行为,如果缓存为空则从数据库中进行读取
*/
//从缓存中获取值
String getData = jedisClient.hget(CONTENTCATEGORYID, categoryId+"");
if (!StringUtils.isBlank(getData)) {
List<TbContent> resultList= JsonUtils.jsonToList(getData, TbContent.class);
return resultList;
}
TbContentExample example=new TbContentExample();
Criteria criteria = example.createCriteria();
criteria.andCategoryIdEqualTo(categoryId);
List<TbContent> list = contentMapper.selectByExample(example);
//向缓存中放入值
String jsonData = JsonUtils.objectToJson(list);
jedisClient.hset(CONTENTCATEGORYID, categoryId+"",jsonData);
return list;
} }
- 所以这里就是写逻辑代码的时候,在业务功能处,从缓存中读取-----从db中读取----将数据写入缓存。
- 3.针对上面出现的问题:
- 当我们后台数据库中内容修改之后,因为缓存中的内容没有修改,我们访问的时候都是先访问缓存,所以即使数据库中的内容修改了,但是页面的显示还是不会改变的。因为缓存没有更新,所以这就涉及到缓存同步的问题:即数据库修改了内容与缓存中对应的内容同步。
- 缓存同步的原理:就是将redis中的key进行删除,下次访问的时候,redis中没有改数据,则从DB进行查询,再次更新到redis中。
- 我们可以写一个缓存同步的服务:
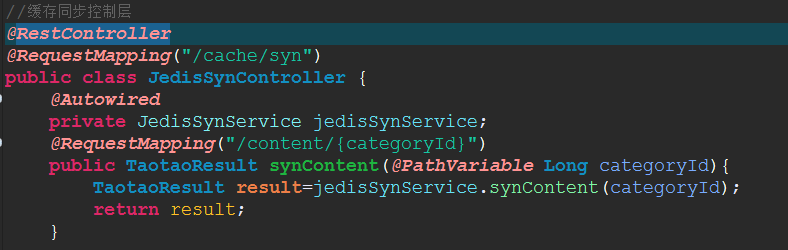

- 缓存同步除了查询是没有涉及到同步问题,增加删除修改都会涉及到同步问题。
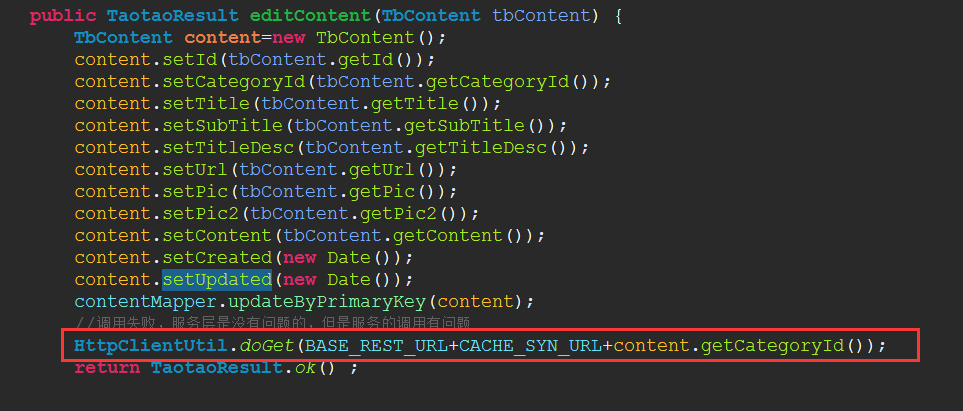
- 只需要在后台进行CRUD的地方添加调用该缓存同步的服务即可:
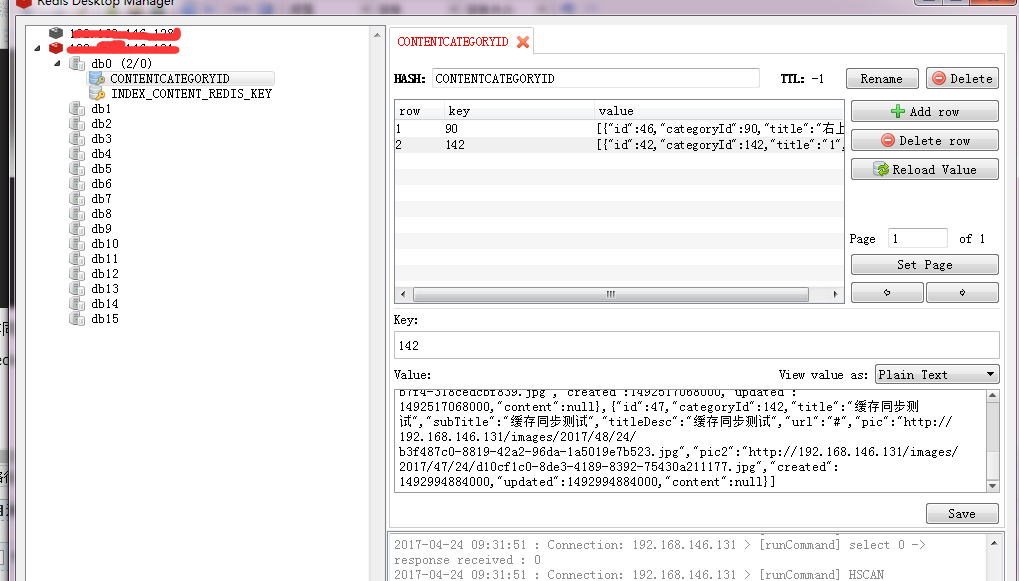
- 5.redis客户端jedis的使用:
 终于结束了,希望能帮助大家,多多支持,关注不迷路哦!!!
终于结束了,希望能帮助大家,多多支持,关注不迷路哦!!!
Redis 【常识与进阶】的更多相关文章
- Redis cluster学习 & Redis常识 & sort操作
Redis中的5种数据类型String.Hash.List.Set.Sorted Set. Redis源码总代码一万多行. 这篇文章有一些Redis "常识" http://www ...
- Redis学习笔记-进阶
Redis持久化方案 redis有rdb和aof两种持久化方案 1)rdb方式 当符合一定条件时会自动将内存中的所有数据执行快照操作并存储到硬盘上 默认存储在redis根目录的dump.rdb文件中, ...
- Redis集群进阶之路
Redis集群规范 本文档基于Redis 3.X或更高版本,讲解Redis集群算法以及设计原理.此官方文档长期更新且随着Redis新版本特性的变化变动,详细请留意官网. 官网地址:https://re ...
- MySQL 【常识与进阶】
MySQL 事物 InnoDB事务原理 事务(Transaction)是数据库区别于文件系统的重要特性之一,事务会把数据库从一种一致性状态转换为另一种一致性状态. 在数据库提交时,可以确保要么所有修改 ...
- 【9k字+】第二篇:进阶:掌握 Redis 的一些进阶操作(Linux环境)
九 Redis 常用配置文件详解 能够合理的查看,以及理解修改配置文件,能帮助我们更好的使用 Redis,下面按照 Redis 配置文件的顺序依次往下讲 1k 和 1kb,1m 和 1mb .1g 和 ...
- MySQL 【进阶查询】
数据类型介绍 整型 tinyint, # 占1字节,有符号:-128~127,无符号位:0~255 smallint, # 占2字节,有符号:-32768~32767,无符号位:0~65535 med ...
- 【1w字+干货】第一篇,基础:让你的 Redis 不再只是安装吃灰到卸载(Linux环境)
Redis 基础以及进阶的两篇已经全部更新好了,为了字数限制以及阅读方便,分成两篇发布. 本篇主要内容为:NoSQL 引入 Redis ,以及在 Linux7 环境下的安装,配置,以及总结了非常详细的 ...
- REST风格框架实战:从MVC到前后端分离(附完整Demo)
既然MVC模式这么好,难道它就没有不足的地方吗?我认为MVC至少有以下三点不足:(1)每次请求必须经过“控制器->模型->视图”这个流程,用户才能看到最终的展现的界面,这个过程似乎有些复杂 ...
- REST风格框架:从MVC到前后端分离***
摘要: 本人在前辈<从MVC到前后端分离(REST-个人也认为是目前比较流行和比较好的方式)>一文的基础上,实现了一个基于Spring的符合REST风格的完整Demo,具有MVC分层结构并 ...
随机推荐
- Jmeter之Beanshell---使用Java处理JSON块
原文出处:https://www.cnblogs.com/xpp142857/p/7374281.html [环境] ①Jmeter版本:3.1,JDK:1.7 ②前置条件:将json.jar包置于. ...
- NSURLSession与NSURLConnection区别
1. 使用现状 NSURLSession是NSURLConnection 的替代者,在2013年苹果全球开发者大会(WWDC2013)随ios7一起发布,是对NSURLConnection进 ...
- Java - 常见的算法
二分法查找 private static int binarySearch(int[] list,int target) { ; ; //直到low>high时还没找到关键字就结束查找,返回-1 ...
- 使用veloticy-ui生成文字动画
前言 最近要实现一个类似文字波浪线的效果,使用了velocity-ui这个动画库,第一个感觉就是使用简单,代码量少,性能优异,在此简单介绍一下使用方法,并实现一个看上去不错的动画.具体使用方法可以点击 ...
- htmlhint 规则详解
HTML 静态检查规则 HTMLHint 工具内置 23 条规则,可以对 HTML 代码文件进行静态代码检查,从而提高 HTML 代码编写的规范和质量.现在把 23 条规则翻译如下. 一.规则列表 标 ...
- LeetCode 33.Search in Rotated Sorted Array(M)
题目: Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. ( ...
- idea使用Tomcat部署war 和 war exploded的区别
war模式:将WEB工程一包的形式上传到服务器中.war exploded模式:将WEB工程以当前文件夹的位置关系上传到服务器.解析:war 模式这种可以称为是发布模式(完整的项目),将项目打成war ...
- 关于nw的简单应用
最近使用到了桌面开发应用nw.js.进行简单的介绍一下,基本用法 nwjs实际上是基于node js的,支持node js的所有api 中文官网https://nwjs.org.cn/ 第一步.在官网 ...
- 前端解决跨域问题的终极武器——Nginx反向代理
提到代理,分为:正向代理和反向代理. 正向代理:就是你访问不了Google,但是国外有个VPN可以访问Google,你访问VPN后叫它访问Google,然后把数据传给你. 正向代理隐藏了真实的客户端. ...
- JavaScript对象(二)
Part One:对象的三个特性 原型(prototype) 类(class) 可扩展性(extensible attribute) 1,b.isPrototypeOf(o) //判断b是不是o的 ...