Python爬虫---爬取抖音短视频
前言
最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经过几天的摸索我发现了一个很严重的问题......抖音实在是难爬!从一开始的网页分析中就有着很多的坑,但是这几天的摸索也不是一无所获,我鼓捣出来了一个问题版的抖音爬虫(操作较为复杂),所以我也想通过这篇博客来记录下我分析网页的过程,也想请教一下路过大佬们,欢迎各位大佬指出问题!(这篇文章的分析比较麻烦了,但是也可以当做分析其他网页的一个参考吧,想要爬抖音的朋友们可以看这一篇的代码改良版抖音爬虫)
抖音爬虫制作
选定网页
想要爬取抖音上面的视频,就要先找到可以刷小视频的地址,于是我就开始在网上寻找网页版的抖音。经过一番寻找,发现抖音根本就没有网页版的这个板块,打开的网页大多都是如下图所示提示你下载app的网页:

想要爬取小视频的内容,没有网页地址可不行。于是我又想到了另一种寻找网页的方法:
首先我打开了手机抖音,选定了一个喜欢的抖音号,使用复制链接的方法来尝试是否可以在网页中打开:
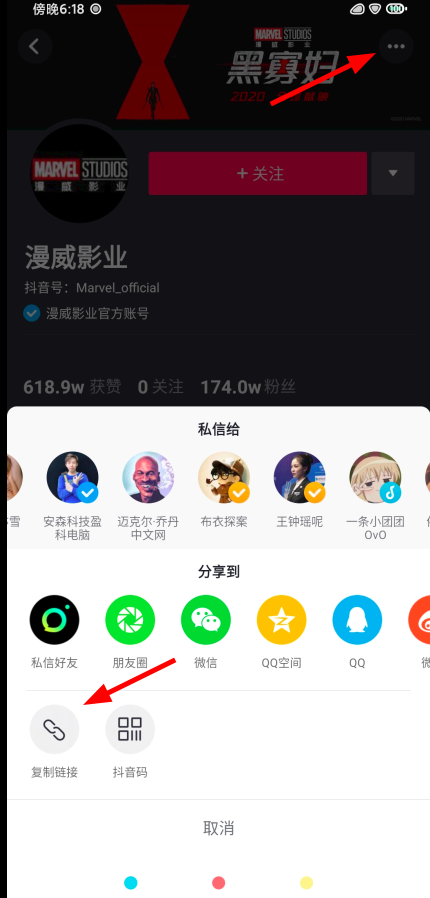
将链接粘贴到记事本中,发现它是长这个样子的
https://v.douyin.com/wGf4e1/
将这个网址在浏览器中打开,发现这个网址可以正常显示

向下滑动,也可以看到这个账号发布的视频
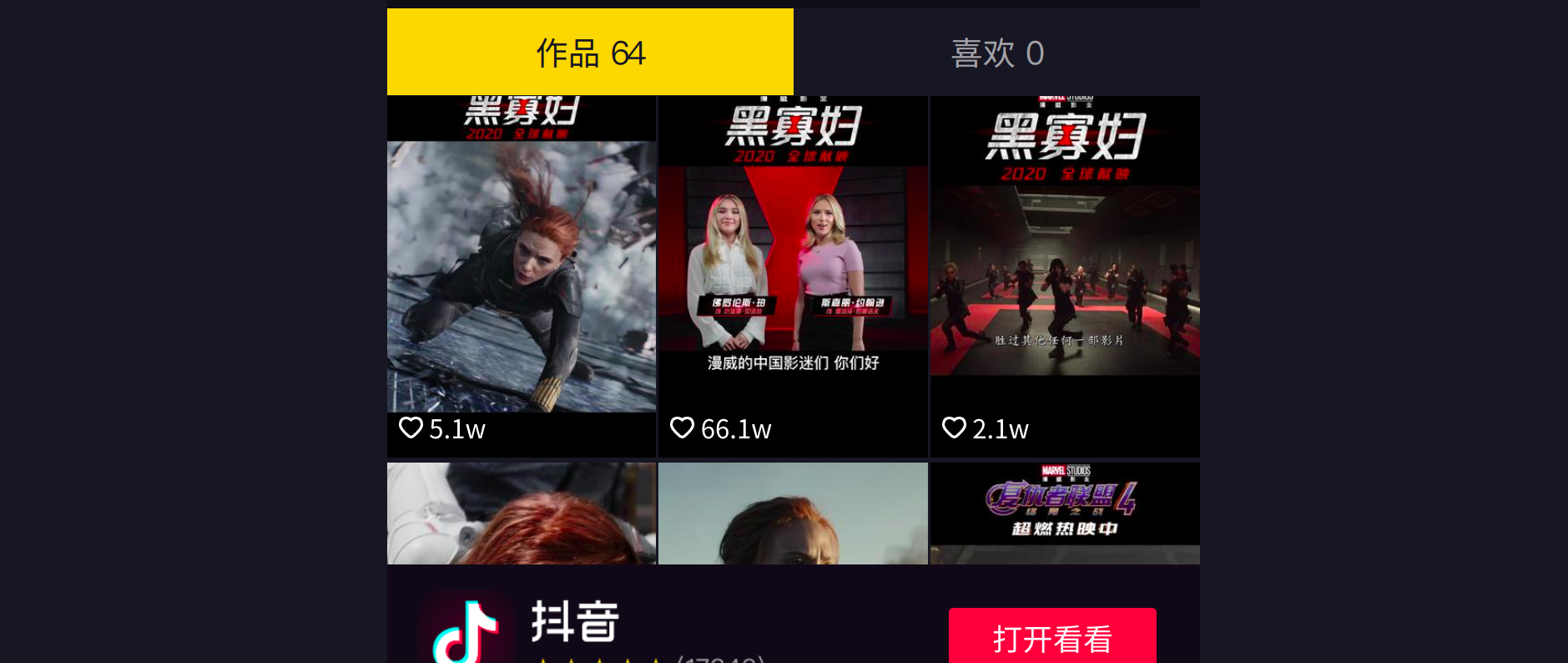
ok,到现在为止,我已经选定了将这个页面作为我获取数据的起始页面
选定起始页之后,我的下一步想法是要去获取这些小视频的单独的网页地址,于是我又点击了下面的这些小视频。这里恶心的地方出现了,无论我点击哪一个小视频,弹出来的都是强迫你下载app的界面
于是我又想尝试上面获取到网页的操作来获取视频的地址,再次打开手机上的抖音,在这个漫威的账号下随便打开一个视频,点击右下角的分享,复制它的链接:
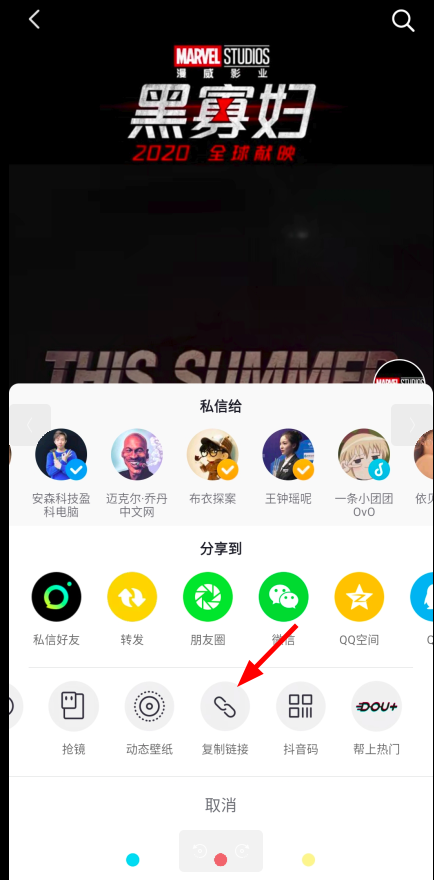
这个链接地址长这个样子:
#黑寡妇 北美终极预告!黑暗过往揭晓,2020即将强势开启漫威电影宇宙第四阶段!
https://v.douyin.com/wGqCNG/ 复制此链接,打开【抖音短视频】,直接观看视频!
我再把这段地址复制到浏览器中打开:
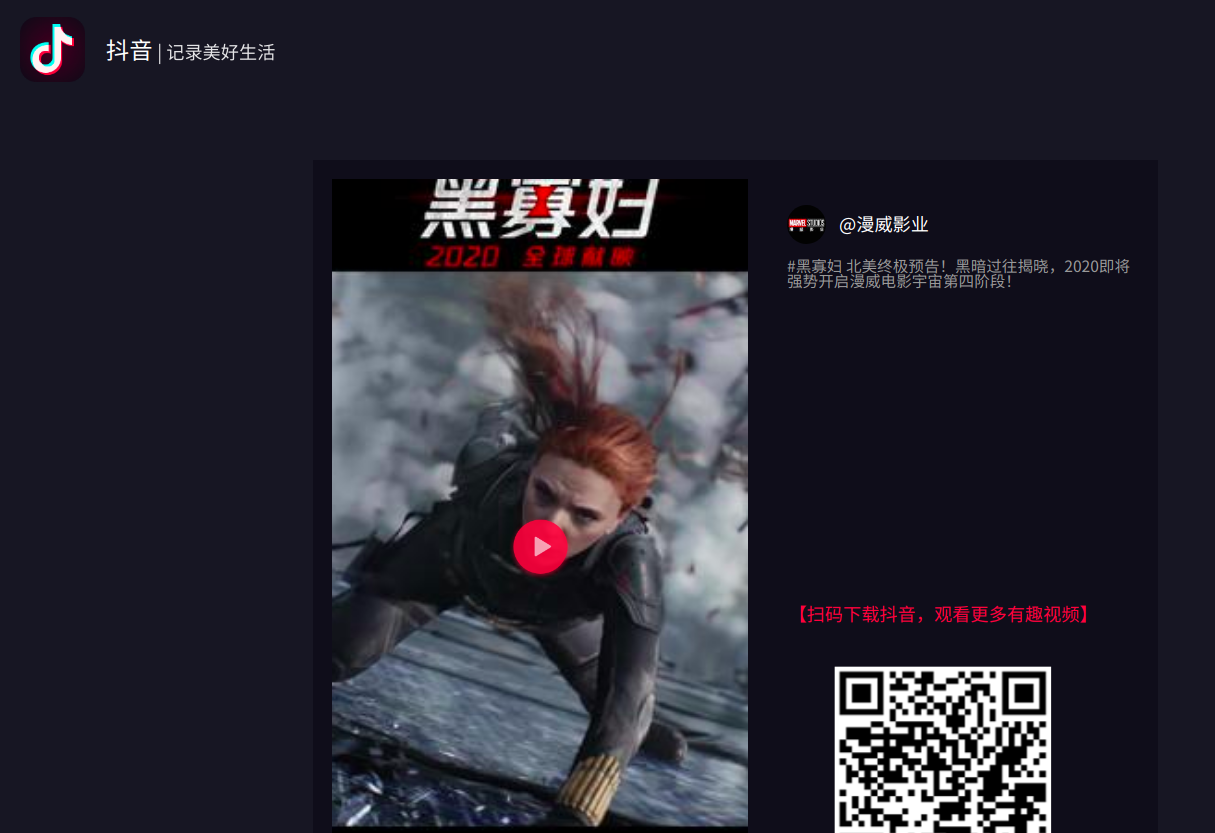
打开的确实是视频页,点击播放按钮也可以播放视频,所以这就是我们需要记住的第二个页面。
分析网页
现在又出现了一个比较麻烦的事情,在浏览器中输入网址过后,跳转到了视频的播放页,但是此时的播放页地址经过了重定向生成了非常长的一串地址,乍一看毫无规律可讲
这是重定向之后的网址:

正常来说请求第一种链接https://v.douyin.com/wGqCNG/和第二种重定向之后的链接都可以获取到信息,但是我发现第一种链接地址是找不到规律的,所以我猜测第二种网址的规律会更加的好找,先把链接地址复制到记事本中:
https://www.iesdouyin.com/share/video/6802189485015633160/?region=CN&mid=6802184753988471559&u_code=388k48lba520&titleType=title&utm_source=copy_link&utm_campaign=client_share&utm_medium=android
&app=aweme
看了这么长一串的链接,链接包含的内容也是非常多的,对分析规律有着很大的干扰,于是我试着精简一下这个链接(删掉链接里面的一些内容,看看是否还能找到页面)经过了一次又一次的尝试,我所得到的最简单的网址如下:
https://www.iesdouyin.com/share/video/6802189485015633160/?mid=6802184753988471559
这个网址依旧可以打开视频页,如果在删掉一点东西,出来的就是抖音的宣传页,所以这个网址就是我所需要的最简单网址
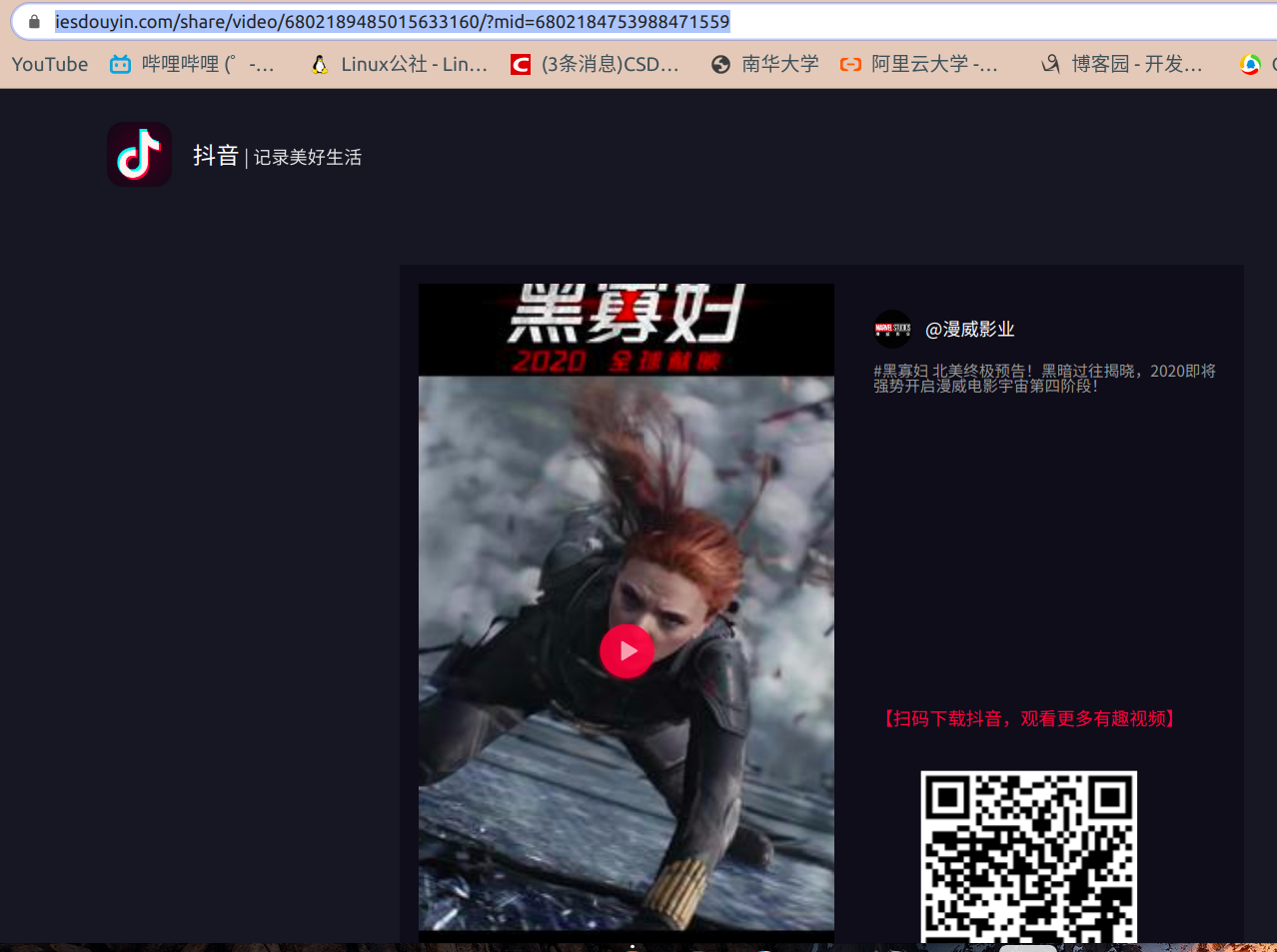
就一个网址当然是分析不出规律的,于是我又用同样的方法来得到两个新网址:
https://www.iesdouyin.com/share/video/6818885848784702728/?region=CN&mid=6818885858780203783&u_code=388k48lba520&titleType=title&utm_source=copy_link&utm_campaign=client_share
&utm_medium=android&app=aweme
https://www.iesdouyin.com/share/video/6820605884050181379/?region=CN&mid=6820605916115864328&u_code=388k48lba520&titleType=title&utm_source=copy_link&utm_campaign=client_share
&utm_medium=android&app=aweme
精简网址之后,将三个网址放在一起观察:
https://www.iesdouyin.com/share/video/6802189485015633160/?mid=6802184753988471559
https://www.iesdouyin.com/share/video/6818885848784702728/?mid=6818885858780203783
https://www.iesdouyin.com/share/video/6820605884050181379/?mid=6820605916115864328
不难发现,这三个网址的区别就在于数字的不同
接下来猜测:这串数字会不会是每个视频的Id值?
随后我打开漫威影业抖音号,右击检查,按下ctrl+f搜索内容,在搜索框内分别搜索https://www.iesdouyin.com/share/video/6802189485015633160/?mid=6802184753988471559链接中的6802189485015633160和6802189485015633160两个值
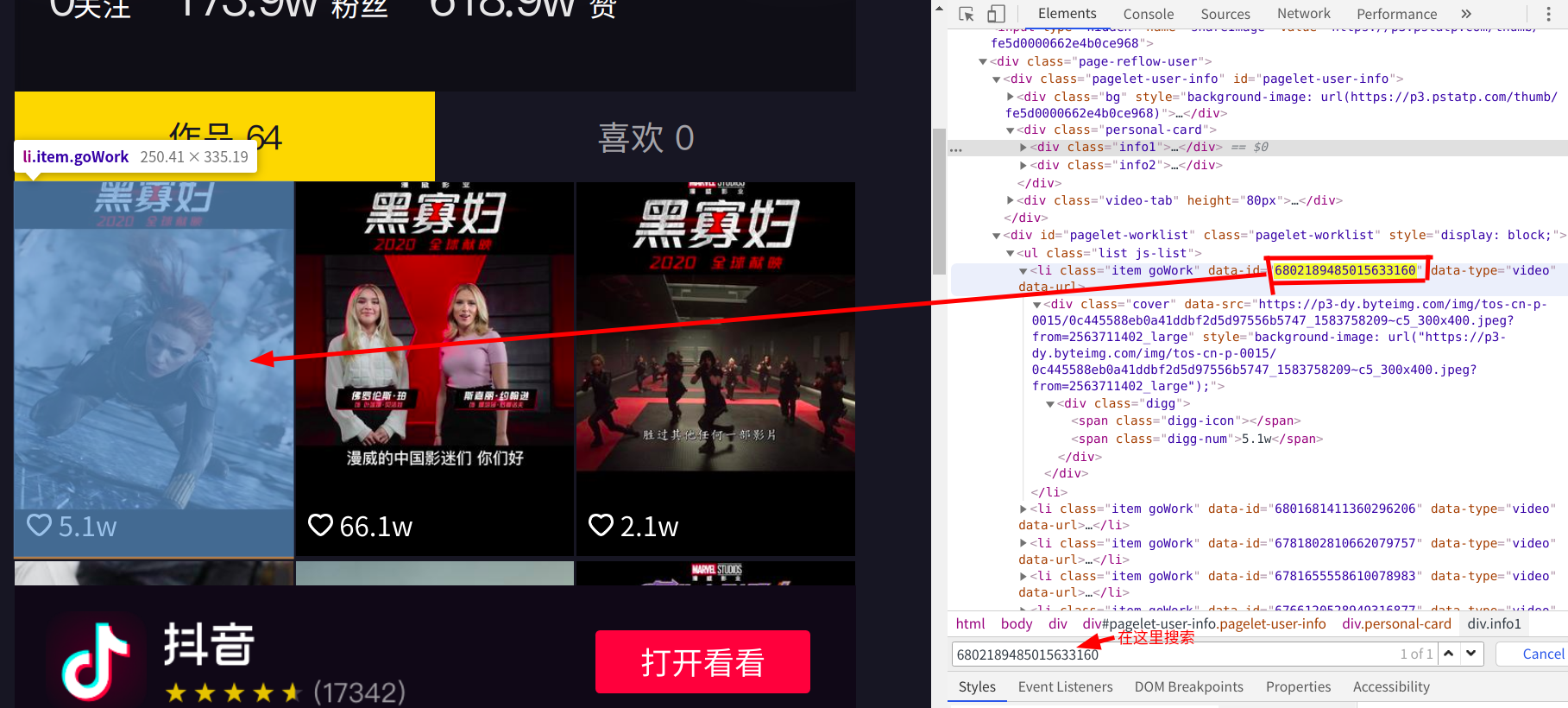
第一个值顺利找到,就是我们所猜测的id值,但是搜索第二个值却得不到任何的返回

这就叫我非常苦恼了,我开始想其他的办法来获取到这个值,我尝试了抓包和其他的一些方法,但是都没有找到这个值的相关信息。
我经过了一番思考,突然间冒出了一个想法:这个值是不是随机生成的?
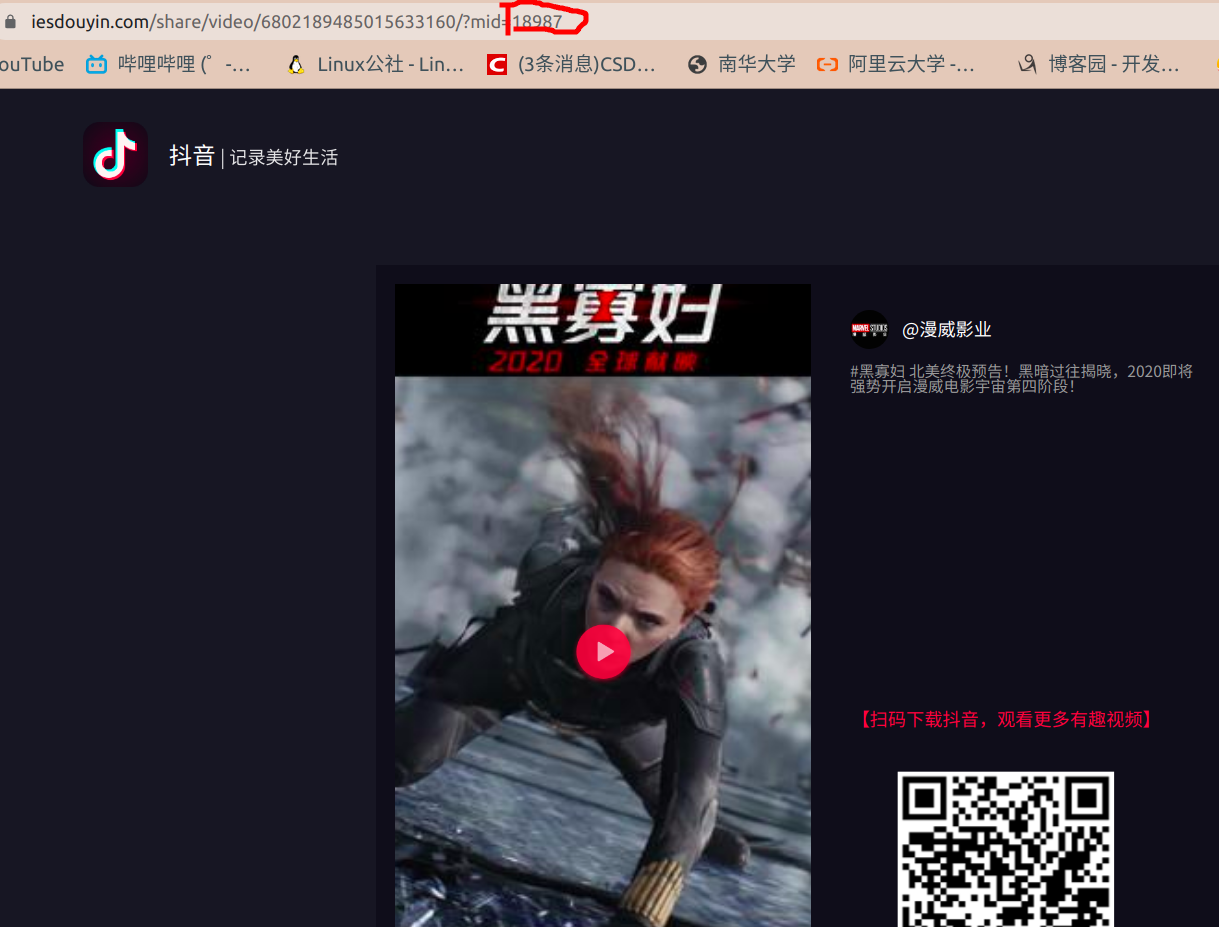
然后我做了一个小小的尝试,我将这个值改成了随便的一个数
https://www.iesdouyin.com/share/video/6802189485015633160/?mid=18987
然而神奇的是,这个网址请求出了数据(去掉这个mid键不出数据,将mid随机赋值却可以得到数据emmm)
提取id构造网址
经过刚刚的分析,我发现我们想要提取的数据就只有一个id值,然后再用Id值替换掉网址中的数字就可以得到相应的视频页面了
id是这段代码的最重要的部分,经过前面曲折又困难的网页分析之后,我认为提取id只需要从网页中用表达式提取数据就可以了,但是我没想到的是这一步也是比较困难的
我先是在主页右击了检查,然后仔细的观察了elements里面的元素,我发现id就储存在elements之中
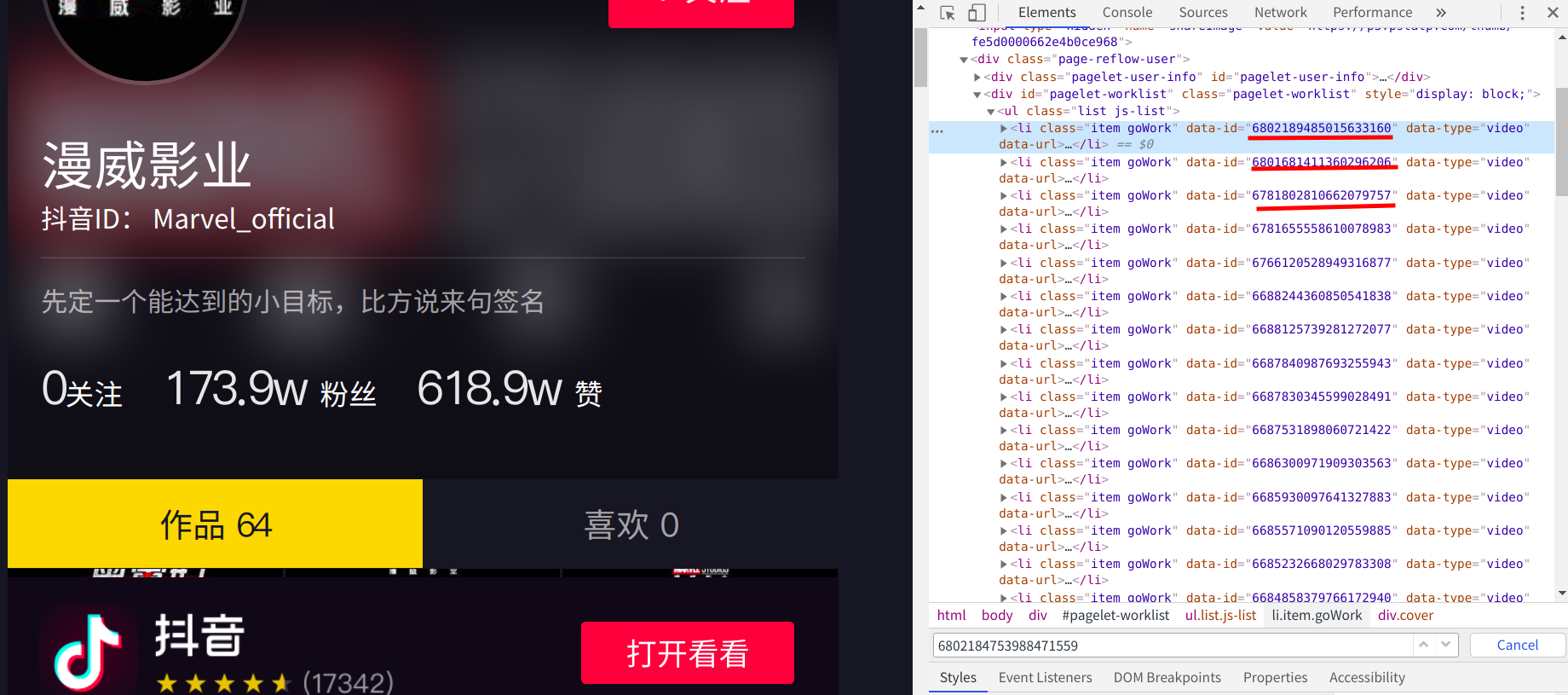
接着我就想办法获得这个页面中的id信息,我尝试了直接请求,发现输出的数据中没有Id信息; 我又加上了请求头,依旧没有id值输出(这个页面的元素是动态加载的,虽然不能一次获取全部Id,但是也不至于一个没有) ;然后我想到了selenium自动化测试模块,使用webdriver打开网址打印源码,可是输出还是没变
我查了百度的一些方法,也做了一些尝试,发现这个页面所做的反爬确实很难破解。于是我就只能换一条路去尝试
在谷歌开发者工具中,点击network选项卡,刷新界面 随着我刷新的操作,在XHR选项卡下出现了一个名字很奇怪的数据包
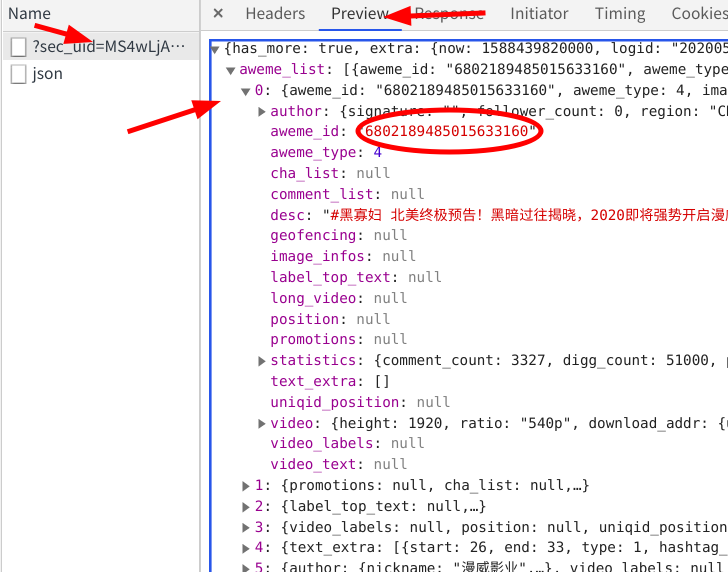
点击他的preview选项卡,点出他的下拉菜单,这里面存储的正是小视频的Id信息。但是需要注意的是,这个包里面只存储了0-20序列的共21条信息
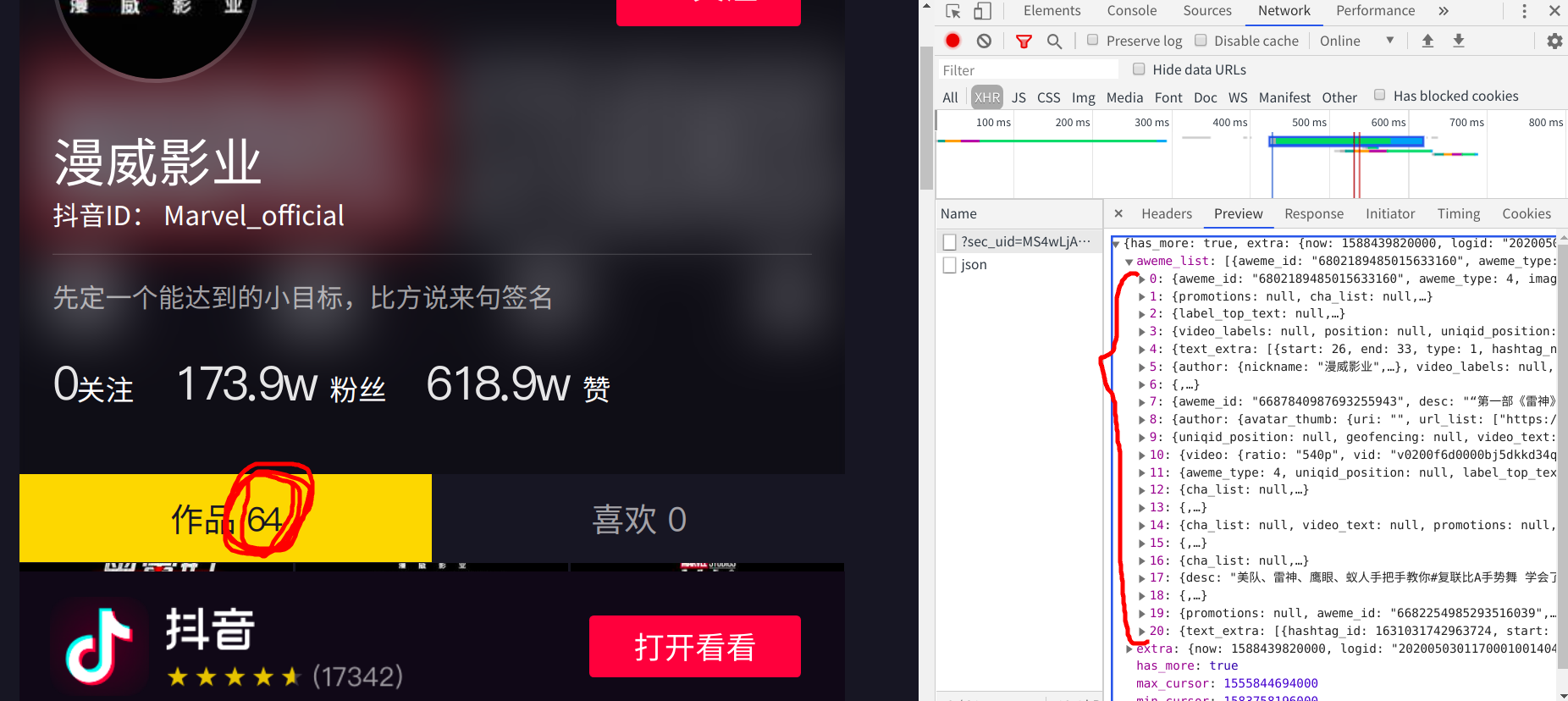
但是从这个主页中我可以知道,它一共发布了64个短视频,所以我推断他还有三个数据包没有加载出来 ---->我滚动下拉条,观察有没有数据包

滚动到最后,验证了我的猜想,这个页面有四个数据包且为动态加载
好了,我们已经分析出来了这个网页的构造,先不要管一共有几个数据包,先以一个数据包为例提取id信息:
复制网页链接作为他的请求网址
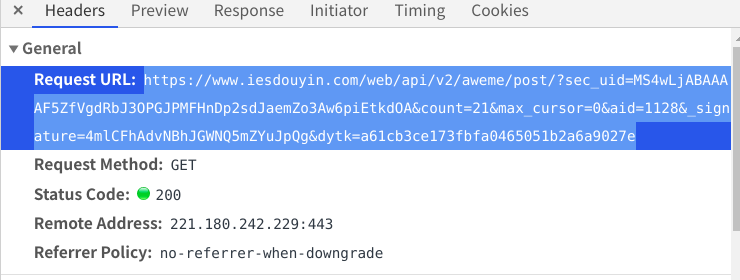
将user-agaent加到请求头中(这个网页必须要加请求头,不然获取不到数据)

请求得到数据:
import requests
import json
class Douyin:
def page_num(self,max_cursor):
#网址后面的随机参数(我实在分析不出规律)
random_field = 'RVb7WBAZG.rGG9zDDDoezEVW-0&dytk=a61cb3ce173fbfa0465051b2a6a9027e'
#网址的主体
url = 'https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAF5ZfVgdRbJ3OPGJPMFHnDp2sdJaemZo3Aw6piEtkdOA&count=21&max_cursor=0&aid=1128&_signature=' + random_field
#请求头
headers = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url,headers=headers).text
#转换成json数据
resp = json.loads(response)
#遍历
for data in resp["aweme_list"]:
# id值
video_id = data['aweme_id']
# 视频简介
video_title = data['desc']
# 构造视频网址
video_url = 'https://www.iesdouyin.com/share/video/{}/?mid=1'
# 填充内容
video_douyin = video_url.format(video_id)
print(video_id)
print(video_title)
print(video_douyin)
if __name__ == '__main__':
douyin = Douyin()
douyin.page_num()
print一下i相关信息:

当前乍一看好像这个代码没有问题,但是在执行四五次之后,会出现请求不到数据或返回False的情况,一开始我以为是ip被限制的原因,但是加上了ip池之后也是一样的结果,后来我才发现:请求不到数据是因为之前请求的url被禁用了,要在抖音详情页刷新一下,再把新的数据包的网址复制过来才能重新得到数据(我也不知道这是什么类型的反爬,希望知道的老哥可以告诉我一下)
*我之所以把这个网址分成两部分来写,是因为当网址请求不到数据的时候,改变的是末尾的_signature=random_field字段,在请求不到数据的时候只需重新复制一下这个字段就可以了,会简化一点点代码
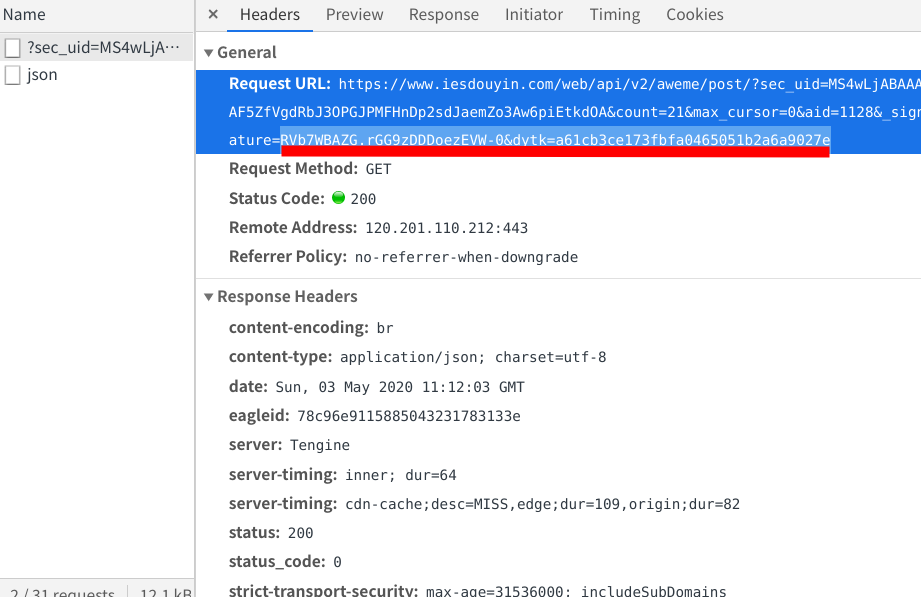
拼接数据包链接
上面提取Id的时候讲到,我们先拿一个数据包做例子,但是我们要爬的这个用户的全部视频,所以就要将它所有的数据包地址都访问一遍
想要得到这些数据包的地址,就需要分析他们的网址构造,我把这四个数据包的网址全部复制到记事本中,逐个分析他们构造规律

不难看出,这四个数据包的区别就在于max_cursor后面的值的不同,而这个值正好就包包含在它前一个数据包之中,这就说明我们可以从前一个数据包中提取到下一个数据包的max_curso值,从而构造出下一个数据包的链接地址

可是第四个数据包也包含着max_cursor的值,我们该在何时停止构造下一个数据包呢?
我把最后一个数据包的max_cursor值复制下来并替换到构造的数据包链接中,发现可以跳转到一个新的网址,这个网址中也有max_cursor的值,但是这个值为0

也可以多找几个网址测试,最后的结果指向都是0,所以我们可以通过if语句来判断这个值为0的时候就终止循环
构造网址代码:
import requests
import json
class Douyin:
def page_num(self,max_cursor):
#网址后面的随机参数(我实在分析不出规律)
random_field = 'pN099BAV-oInkBpv2D3.M6TdPe&dytk=a61cb3ce173fbfa0465051b2a6a9027e'
#网址的主体
url = 'https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAF5ZfVgdRbJ3OPGJPMFHnDp2sdJaemZo3Aw6piEtkdOA&count=21&max_cursor=' + str(max_cursor) + '&aid=1128&_signature=' + random_field
#请求头
headers = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url,headers=headers).text
#转换成json数据
resp = json.loads(response)
#提取到max_cursor
max_cursor = resp['max_cursor']
#判断停止构造网址的条件
if max_cursor==0:
return 1
else:
print(url)
douyin.page_num(max_cursor)
if __name__ == '__main__':
douyin = Douyin()
douyin.page_num(max_cursor=0)
输出构造后的网址:

获取视频地址
现在我们已经可以成功的进入获取到视频页面了,复杂的网页分析基本已经结束了,后续操作就变得简单了
先打开小视频的页面,右击检查,查看元素
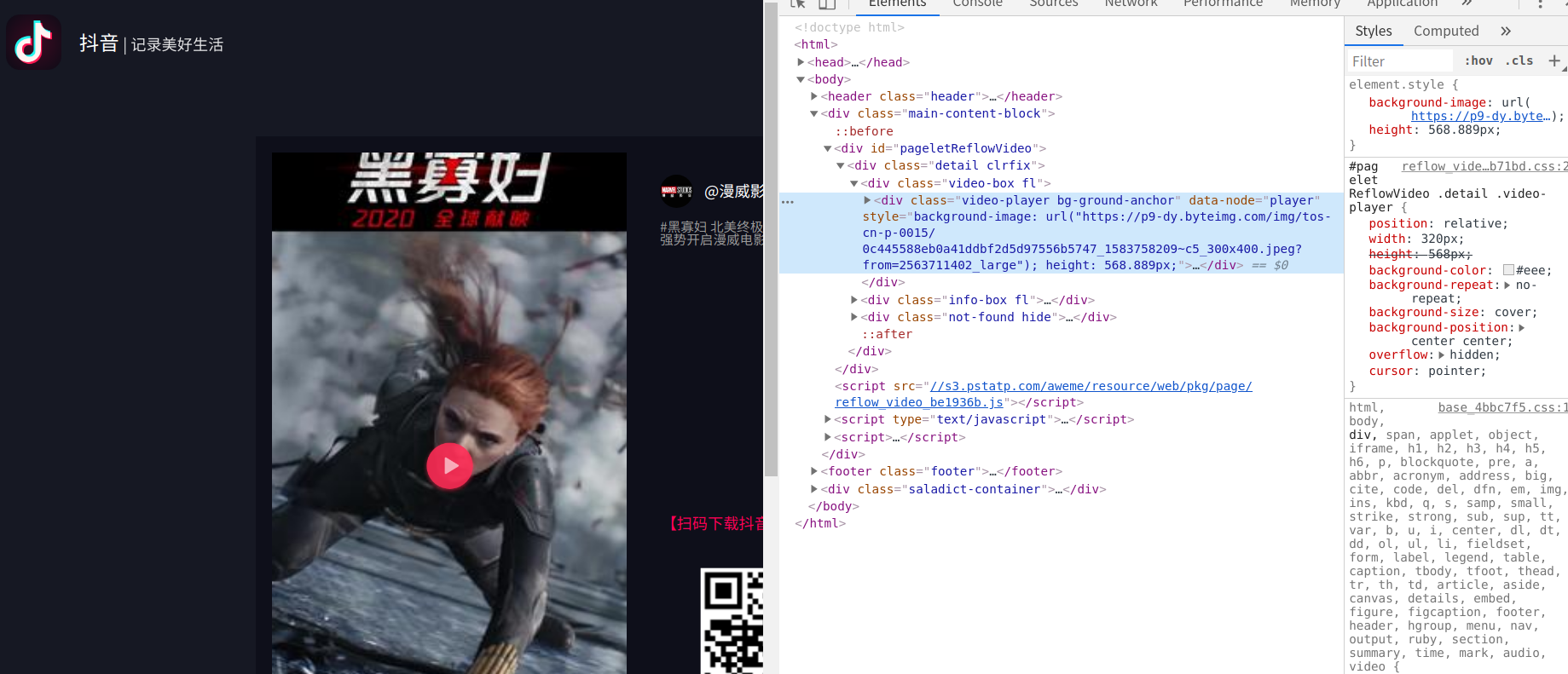
经过检查发现,这个源代码中并没有视频地址,点击了一下播放按键,视频的地址才会加载出来
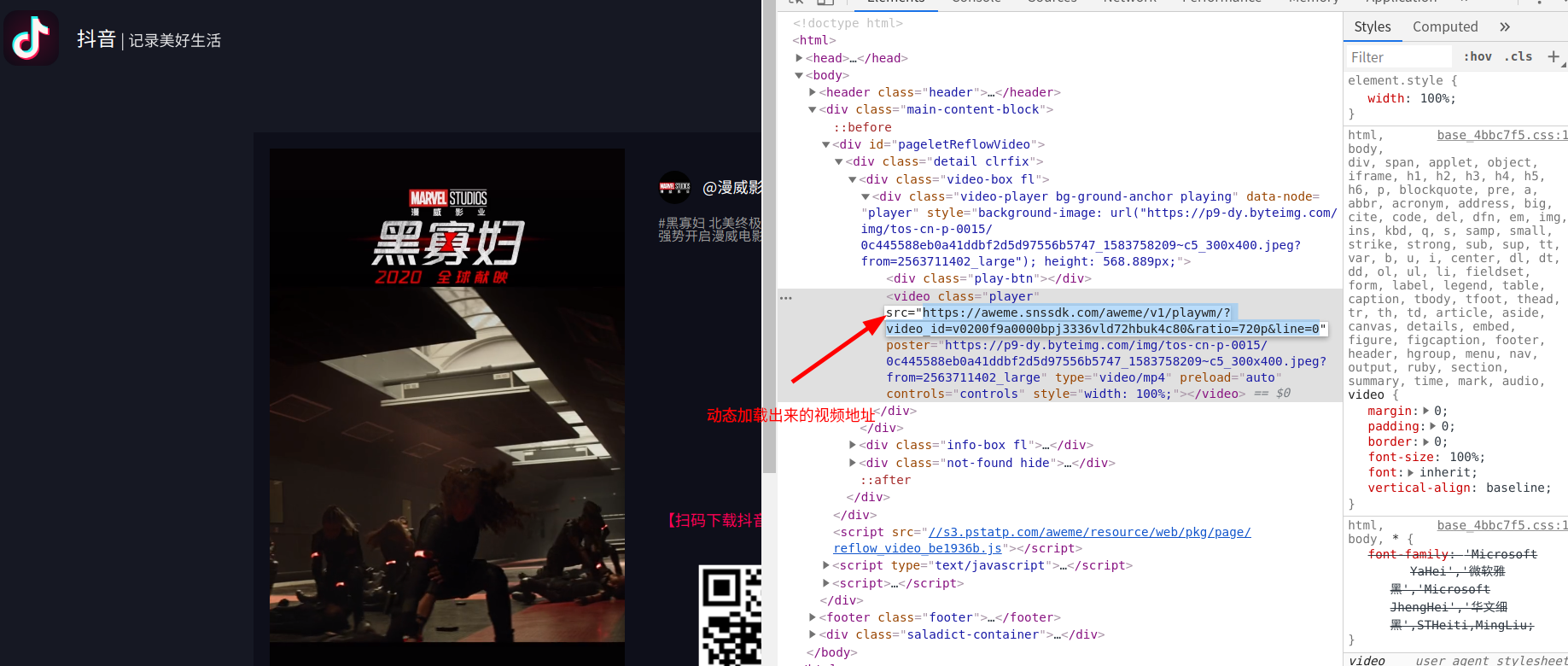
这个网址中只包含了一个小视频

看到这种动态加载的机制,我们首先就应该想到selenium自动化测试工具,步骤是先用selenium打开视频页面,再点击播放按钮,将此时已经刷新完的网页源代码保存,
再从中提取到视频的真正网址,最后再将调试好的webdriver设置为无界面模式
实现代码:
from selenium import webdriver
from lxml import etree
from selenium.webdriver.chrome.options import Options
import requests
import json
import time
class Douyin:
def page_num(self,max_cursor):
#网址后面的随机参数(我实在分析不出规律)
# 设置谷歌无界面浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# chromdriver地址
path = r'/home/jmhao/chromedriver'
#随机码
random_field = 'IU4uXRAbf-iiAwnGoS-puCFOLk&dytk=a61cb3ce173fbfa0465051b2a6a9027e'
#网址的主体
url = 'https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAF5ZfVgdRbJ3OPGJPMFHnDp2sdJaemZo3Aw6piEtkdOA&count=21&max_cursor=' + str(max_cursor) + '&aid=1128&_signature=' + random_field
#请求头
headers = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url,headers=headers).text
#转换成json数据
resp = json.loads(response)
#提取到max_cursor
max_cursor = resp['max_cursor']
#遍历
for data in resp["aweme_list"]:
# id值
video_id = data['aweme_id']
# 视频简介
video_title = data['desc']
# 构造视频网址
video_url = 'https://www.iesdouyin.com/share/video/{}/?mid=1'
# 填充内容
video_douyin = video_url.format(video_id)
driver = webdriver.Chrome(executable_path=path, options=chrome_options)
# 打开视频界面
driver.get(video_douyin)
# 点击播放按钮
driver.find_element_by_class_name('play-btn').click()
time.sleep(2)
# 将网页源码存放到变量中
information = driver.page_source
# 退出
driver.quit()
html = etree.HTML(information)
# 提取视频地址
video_adress = html.xpath("//video[@class='player']/@src")
print(video_adress)
#判断停止构造网址的条件
if max_cursor==0:
return 1
else:
#否则循环构造网址
douyin.page_num(max_cursor)
if __name__ == '__main__':
douyin = Douyin()
douyin.page_num(max_cursor=0)
打印一下视频的真实网址:

下载视频
视频的真实网址我们已经获得了,接下来只剩下最后一步的操作了---->下载视频
视频下载的操作就非常简单了:
for i in video_adress:
#请求视频
video = requests.get(i,headers=headers).content
with open('douyin/' + video_title,'wb') as f:
print('正在下载:',video_title)
f.write(video)
全部代码
from selenium import webdriver
from lxml import etree
from selenium.webdriver.chrome.options import Options
import requests
import json
import time
class Douyin:
def page_num(self,max_cursor):
#网址后面的随机参数(我实在分析不出规律)
# 设置谷歌无界面浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# chromdriver地址
path = r'/home/jmhao/chromedriver'
#随机码
random_field = 'yo91eRAflEhJwlLiO2coYsqPdW&dytk=4a01c95562f1f10264fb14086512f919'
#网址的主体
url = 'https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAU7Bwg8WznVaafqWLyLUwcVUf9LgrKGYmctJ3n5SwlOA&count=21&max_cursor=' + str(max_cursor) + '&aid=1128&_signature=' + random_field
#请求头
headers = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url,headers=headers).text
#转换成json数据
resp = json.loads(response)
#提取到max_cursor
max_cursor = resp['max_cursor']
#遍历
for data in resp["aweme_list"]:
# id值
video_id = data['aweme_id']
# 视频简介
video_title = data['desc']
# 构造视频网址
video_url = 'https://www.iesdouyin.com/share/video/{}/?mid=1'
# 填充内容
video_douyin = video_url.format(video_id)
driver = webdriver.Chrome(executable_path=path, options=chrome_options)
# 打开视频界面
driver.get(video_douyin)
# 点击播放按钮
driver.find_element_by_class_name('play-btn').click()
time.sleep(2)
# 将网页源码存放到变量中
information = driver.page_source
# 退出
driver.quit()
html = etree.HTML(information)
# 提取视频地址
video_adress = html.xpath("//video[@class='player']/@src")
for i in video_adress:
# 请求视频
video = requests.get(i, headers=headers).content
with open('douyin/' + video_title, 'wb') as f:
print('正在下载:', video_title)
f.write(video)
#判断停止构造网址的条件
if max_cursor==0:
return 1
else:
douyin.page_num(max_cursor)
return url
if __name__ == '__main__':
douyin = Douyin()
douyin.page_num(max_cursor=0)
实现结果
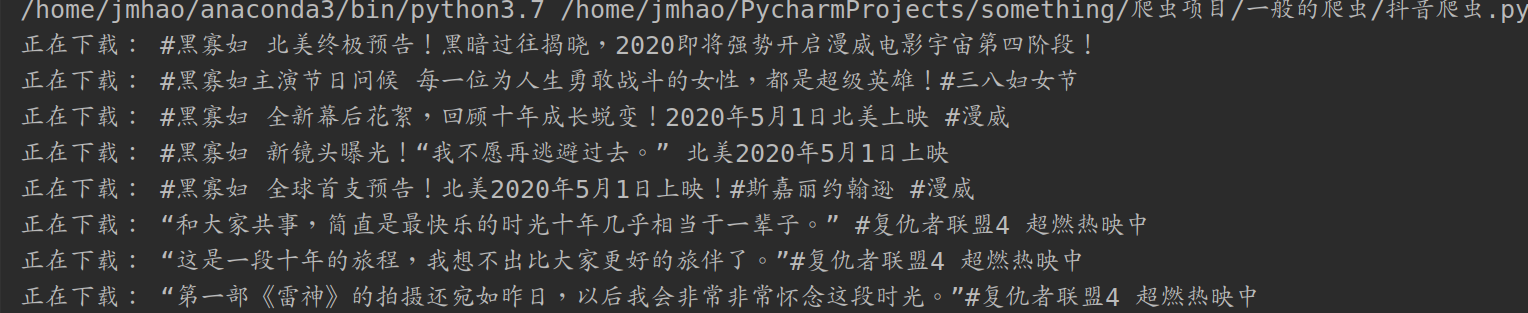
可以看到这些视频已经下载到本地了,我们在打开本地文件夹看一下
随便打开一个视频文件:
可以播放!至此我这个问题版的抖音爬虫就做完了
待解决的问题
- 如何获取主页中所有的id地址
- 为什么请求的url后缀会一直变化,该怎么破解
其实所有的问题都指向了一个地方:该怎么获取小视频的id
如果大佬们有更好的方法可以获取id值,希望大佬们可以提出建议让我把这个爬虫的功能再完善!感谢各位!
Python爬虫---爬取抖音短视频的更多相关文章
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- Python音视频开发:消除抖音短视频Logo的图形化工具实现
☞ ░ 前往老猿Python博文目录 ░ 一.引言 在<Python音视频开发:消除抖音短视频Logo和去电视台标的实现详解>节介绍了怎么通过Python+Moviepy+OpenCV实现 ...
- Python音视频开发:消除抖音短视频Logo和去电视台标
☞ ░ 前往老猿Python博文目录 ░ 一.引言 对于带Logo(如抖音Logo.电视台标)的视频,有三种方案进行Logo消除: 直接将对应区域用对应图像替换: 直接将对应区域模糊化: 通过变换将要 ...
- python+fiddler 抓取抖音数据包并下载抖音视频
这个我们要下载视频,那么肯定首先去找抖音视频的url地址,那么这个地址肯定在json格式的数据包中,所以我们就去专门查看json格式数据包 这个怎么找我就不用了,直接看结果吧 你找json包,可以选大 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- JAVA代码实现抖音短视频去水印功能
今天有人找我帮他抖音视频去水印,发到朋友圈,然后就研究了一下.去水印功能代码如下: public class DouYinQushuiyin { public static void main(Str ...
随机推荐
- C# 基础知识系列- 9 字符串的更多用法(一)
0. 前言 在前面的文章里简单介绍了一下字符串的相关内容,并没有涉及到更多的相关内容,这一篇将尝试讲解一下在实际开发工作中会遇到的字符串的很多操作. 1. 创建一个字符串 这部分介绍一下如何创建一个字 ...
- k8s pod yaml参数说明
- Linux C++ 网络编程学习系列(4)——多路IO之epoll基础
epoll实现多路IO 源码地址:https://github.com/whuwzp/linuxc/tree/master/epoll 源码说明: server.cpp: 监听127.1:6666,功 ...
- 如何使用Swagger-UI在线生成漂亮的接口文档
一.简单介绍 Swagger是一个实现了OpenAPI(OpenAPI Specification)规范的工具集.OpenAPI是Linux基金会的一个项目,试图通过定义一种用来描述API格式或API ...
- 动手学Transformer
动手实现Transformer,所有代码基于tensorflow2.0,配合illustrated-transformer更香. 模型架构 Encoder+Decoder Encoder Decode ...
- c++ 启发式搜索解决八数码问题
本文对八数码问题 启发式搜索 (C++)做了一点点修改 //fn=gn+hn #include<iostream> #include<queue> #include<st ...
- 利用numpy实现多维数组操作图片
1.上次介绍了一点点numpy的操作,今天我们来介绍它如何用多维数组操作图片,这之前我们要了解一下色彩是由blue ,green ,red 三种颜色混合而成,0:表示黑色 ,127:灰色 ,255:白 ...
- 如何假装黑客,使用python去批量破解朋友的网站密码
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- [转载]MySQL中int(11)最大长度是多少?
原文地址:https://blog.csdn.net/allenjay11/article/details/76549503 今天在添加数据的时候,发现当数据类型为 int(11) 时,我当时让用户添 ...
- python+selenium实现网页自动化与爬虫技术
举例某购物网站,通过selenium与python,实现主页上商品的搜索,并将信息爬虫保存至本地excel表内. 一.python环境与selenium环境安装 python在官网下载并安装并且设置环 ...