爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例
1. Scrapy框架
Scrapy功能非常强大,爬取效率高,相关扩展组件多,可配置和可扩展程度非常高,它几乎可以应对所有反爬网站,是目前Python中使用最广泛的爬虫框架。
1.1 Scrapy介绍
1.1.1 架构介绍
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
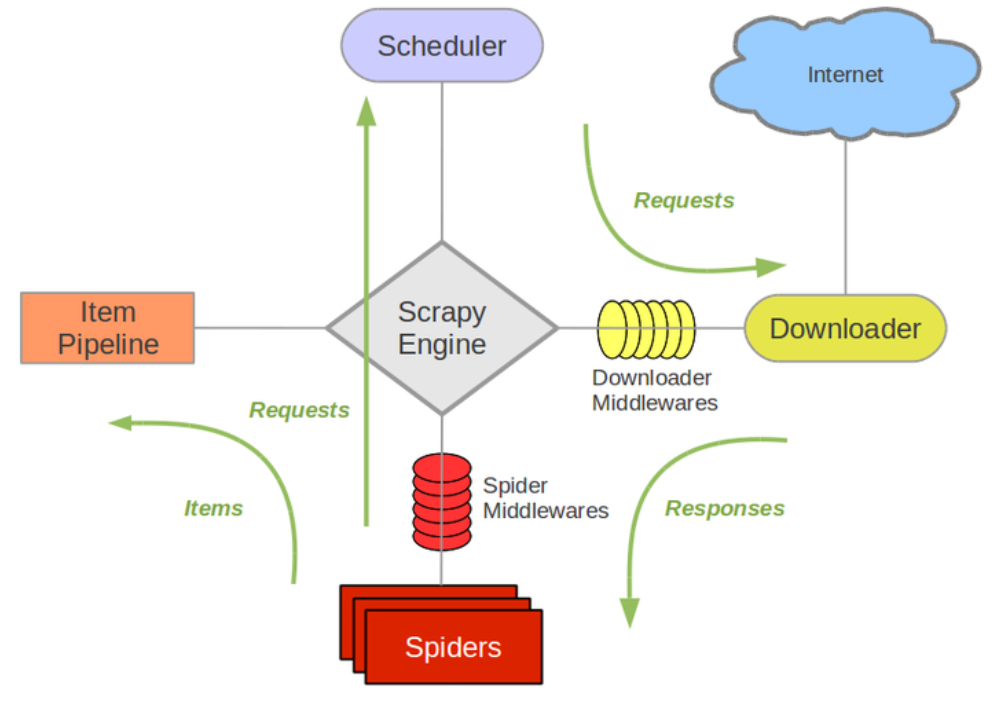
它可以分为如下的几个部分:
Engine:引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
Item:项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
Scheduler:调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
Downloader:下载器,下载网页内容,并将网页内容返回给蜘蛛。
Spiders:蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
Item Pipeline:项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares:下载器中间件,位于引擎和下载器之 的钩子框架,主要处理引擎与下载器之间的请求及响应。
Spider Middlewares:蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
1.1.2 数据流
Scrapy中的数据流由引擎控制,数据流的过程如下:
(1) Engine首先打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL。
(2) Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request的形式调度。
(3) Engine向Scheduler请求下一个要爬取的URL。
(4) Scheduler返回下一个要爬取的URL给Engine,Engine将URL通过Downloader Middlewares发给 Downloader下载。
(5) 一旦页面下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine。
(6) Engine从下载器中接收到Response,并将其通过Spider Middleware发送给Spider处理。
(7) Spider处理Response,并返回爬取到的Item及新的Request给Engine。
(8) Engine将Spider返回的Item给Item Pipeline,将新的Request给Scheduler。
(9)重复第(2)步到第(8)步,直到Scheduler中没有更多的Request,Engine关闭该网站,爬取结束。
通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持Scrapy最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
1.1.3 项目结构
Scrapy框架是通过命令行来创建项目的,代码的编写还是需要IDE。项目创建之后,项目文件的格式如下所示:
scrapy.cfg
project/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
spider1.py
spider2.py
...
这里各个文件的功能描述如下:
scrapy.cfg:它是Scrapy项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容
items.py:它定义Item数据结构,所有的Item的定义都可以放这里。
pipelines.py:它定义Item Pipeline的实现,所有的Item Pipeline的实现都可以放这里。
settings.py:它定义项目的全局配置。
middlewares.py:它定义Spider Middlewares和Downloader Middlewares的实现。
spiders:其内包含一个个Spider的实现,每个Spider都有一个文件。
1.2 Scrapy入门
接下来就写一个简单的项目,让我们对Scrapy的基本用法和原理有大致的了解。
1.2.1 创建项目
首先安装Scrapy模块,再创建Scrapy项目。
pip install scrapy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
创建Scrapy一个项目,项目文件可以直接用scrapy命令生成:
scrapy startproject tutorial
这个命令可以在任意文件夹运行。

这个命令将会创建一个名为tutoria文件夹,文件夹结构如下所示:

1.2.2 创建Spider
Spider是自己定义的类,Scrapy用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承Scrapy提供的Spider类scrapy.Spider,还要定义Spider的名称和起始请求,以及怎样处理爬取后的结果的方法。
也可以使用命令行创建一个Spider。比如要生成top250这个Spider。
cd tutorial
scrapy genspider top250 movie.douban.com/250
进入刚才创建的tutorial文件夹,然后执行genspider命令。第一个参数是Spider名称,第二个参数是网站域名。执行完毕之后,spiders文件夹中多了一个quotes.py,它就是刚刚创建的Spider。

这里有三个属性——name、allowed_domains和start_urls,还有一个方法parse。
name,它是每个项目唯一的名字,用来区分不同的Spider。
allowed_domains,它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
start_urls,它包含了Spider在启动时爬取的url列表,初始请求是由它来定义的。
parse,它是Spider一个方法。默认情况下,被调用时start_urls里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
1.2.3 创建Item
Item是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。观察目标网站,我们可以获取到到内容有serial_number、movie_name、introduce、star、evaluate、describe。
定义Item,此时修改items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
serial_number = scrapy.Field()
movie_name = scrapy.Field()
introduce = scrapy.Field()
star = scrapy.Field()
evaluate = scrapy.Field()
describe = scrapy.Field()
这里定义了三个字段,接下来爬取时我们会使用到这个Item。
1.2.4 解析Response
前面已经说了,parse()方法的参数resposne是start_urls里面的链接爬取后的结果。所以在parse()方法中,我们可以直接对response变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。我们可以看到网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都要进行处理。
首先看看网页结构:
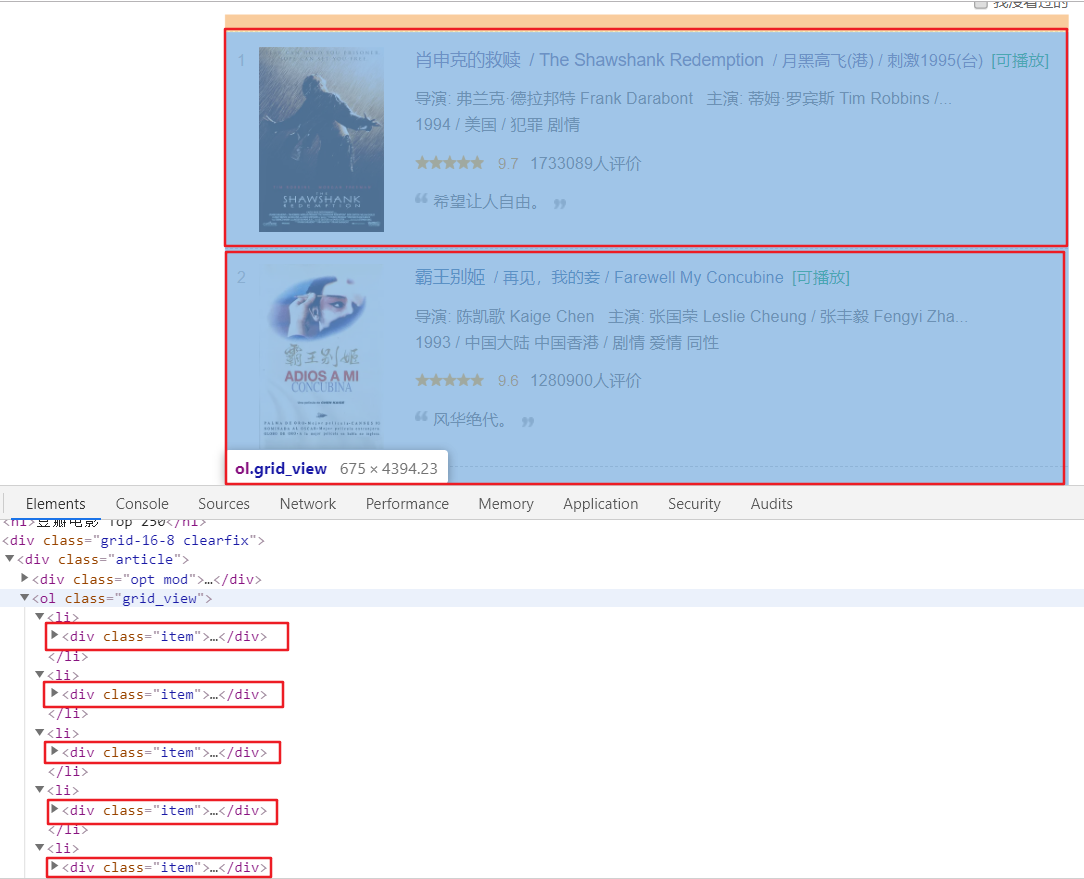
每一页都有多个class为item的区块,每个区块内都包含serial_number、movie_name、introduce、star、evaluate、describe那么我们先找出所有的item,然后提取每一个item中的内容。
提取的方式可以是css选择器或XPath选择器,top250.py的XPath改写如下:
# -*- coding: utf-8 -*-
import scrapy class Top250Spider(scrapy.Spider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/250/'] def parse(self, response):
movie_list = response.xpath('//div[@class="item"]')
for i_item in movie_list:
serial_number = i_item.xpath('.//em/text()').extract_first()
movie_name = i_item.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
content = i_item.xpath('.//div[@class="bd"]/p[1]/text()').extract()
for i_content in content:
introduce = "".join(i_content.split())
star = i_item.xpath('.//span[@class="rating_num"]/text()').extract_first()
evaluate = i_item.xpath('.//div[@class="star"]//span[4]/text()').extract_first()
describe = i_item.xpath('.//p[@class="quote"]//span/text()').extract_first()
这里首先利用选择器选取所有的item,并将其赋值为movie_list变量,然后利用for循环对每个item遍历,解析每个item的内容。
1.2.5 使用Item
前面定义了Item,接下来就要使用它了。Item可以理解为字典,不过在声明的时候需要实例化。然后依次用刚才解析的结果赋值Item的每一段,最后将Item返回即可。
修改top250.py文件:
# -*- coding: utf-8 -*-
import scrapy class Top250Spider(scrapy.Spider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/250/'] def parse(self, response):
movie_list = response.xpath('//div[@class="item"]')
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath('.//em/text()').extract_first()
douban_item['movie_name'] = i_item.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
content = i_item.xpath('.//div[@class="bd"]/p[1]/text()').extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath('.//span[@class="rating_num"]/text()').extract_first()
douban_item['evaluate'] = i_item.xpath('.//div[@class="star"]//span[4]/text()').extract_first()
douban_item['describe'] = i_item.xpath('.//p[@class="quote"]//span/text()').extract_first()
yield douban_item
这样首页的所有内容都可以被解析出来,并被赋值成一个个DoubanItem。
1.2.6 后续Request
前面的操作实现了从初始页面抓取内容。那么,下一页的内容该如何抓取?这就需要我们从当前页面中找到信息来生成下一个请求,然后在下一个请求的页面里找到信息再构造再下一个请求。这样 循环往复迭代,从而实现整站的爬取。
将页面拉到最底部,如图:
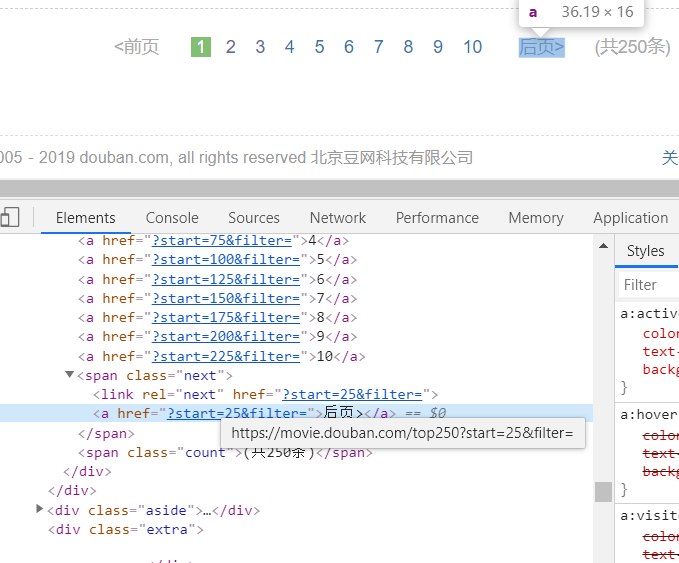
这里有后页按钮。查看它的源代码,可以发现它的链接是?start=25&filter=,完整链接是:https://movie.douban.com/top250?start=25&filter=,通过这个链接我们就可以构造下一个请求。
构造请求时需要用到scrapy.Request这里我们传递两个参数——url和callback。
Request参数:
url:它是请求链接。
callback:它是回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或生成下一个请求,回调函数如上文parse()所示。
由于parse()就是解析serial_number、movie_name、introduce、star、evaluate、describe的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用parse()方法来做页面解析。
接下来我们要做的就是利用选择器得到下一页链接并生成请求,在parse()方法后追加代码:
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import DoubanItem class Top250Spider(scrapy.Spider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/250/'] def parse(self, response):
movie_list = response.xpath('//div[@class="item"]')
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath('.//em/text()').extract_first()
douban_item['movie_name'] = i_item.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
content = i_item.xpath('.//div[@class="bd"]/p[1]/text()').extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath('.//span[@class="rating_num"]/text()').extract_first()
douban_item['evaluate'] = i_item.xpath('.//div[@class="star"]//span[4]/text()').extract_first()
douban_item['describe'] = i_item.xpath('.//p[@class="quote"]//span/text()').extract_first()
yield douban_item
next_link = response.xpath('//span[@class="next"]/link/@href').extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request('https://movie.douban.com/top250' + next_link, callback=self.parse)
1.2.7 运行程序
进入目录,运行如下命令:
scrapy crawl top250
信息刷的太快了,上面都刷没了,只要显示中没有出现报错,这样就算成功了,大家可以自己运行一遍。
首先,Scrapy输出了当前的版本号以及正在启动的项目名称。接着输出了当前settings.py中一些重写后的配置。然后输出了当前所应用的Middlewares和Pipelines。Middlewares默认是启用的,可以settings.py中修改。Pipelines 默认是空,同样也可以在settings.py中配置。
settings.py:
# -*- coding: utf-8 -*- # Scrapy settings for tutorial project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'tutorial' SPIDER_MODULES = ['tutorial.spiders']
NEWSPIDER_MODULE = 'tutorial.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tutorial (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' # Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
DOWNLOAD_DELAY = 0.5 # The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'tutorial.middlewares.TutorialSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'tutorial.middlewares.TutorialDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
接下来就是输出各个页面的抓取结果了,可以看到爬虫一边解析,一边翻页,直至将所有内容取完毕,然后终止。
最后,Scrapy输出了整个抓取过程的统计信息,如请求的字节数、请求次数、响应次数、完成原因等。
整个Scrapy程序成功运行。我们通过非常简单的代码就完成了一个网站内容的爬取,这样相比之前一步一步写程序简洁很多。
1.2.8 保存到文件
运行完Scrapy后,我们只在控制台看到了输出结果。如果想保存结果该怎么办呢?
要完成这个任务其实不需要任何额外的代码,Scrapy提供的Feed Exports可以轻松将抓取结果输出。例如,我们想将上面的结果保存成JSON文件,可以执行如下命令:
scrapy crawl top250 -o top250.json
命令运行后,项目内多了一个quotes.json文件(没有就刷新),文件包含了刚才抓取的所有内容,内容是JSON格式。
另外我们还可以每一个Item输出一行JSON,输出后缀为jl,为jsonline的缩写:
scrapy crawl top250 -o top250.jl
或
scrapy crawl top250 -o top250.jsonlines
输出格式还支持很多种,例如csv、xml、pickle、marshal等,还支持ftp、s3等远程输出,另外还可以通过自定义ItemExporter来实现其他的输出。
例如,下面命令对应的输出分别为csv、xml、pickle、marshal格式以及ftp远程输出:
scrapy crawl top250 -o top250.csv
scrapy crawl top250 -o top250.xml
scrapy crawl top250 -o top250.pickle
scrapy crawl top250 -o top250.marshal
scrapy crawl top250 -o ftp://user:pass@ftp.example.com/path/to/top250.csv
其中,ftp输出需要正确配置用户名、密码、地址、输出路径,否则会报错。
通过Scrapy提供的Feed Exports,我们可以轻松地输出抓取结果到文件。对于一些小型项目来说, 这应该足够了。不过如果想要更复杂的输出,如输出到数据库等,我们可以使用Item Pileline来完成。
爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例的更多相关文章
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- scrapy框架系列 (4) Scrapy Shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- Scrapy框架 之某网站产品采集案例
一.创建项目 第一步:scrapy startproject boyuan 第二步:cd boyuan scrapy genspider product -t crawl boyuan.com 如图 ...
- Python 之scrapy框架58同城招聘爬取案例
一.项目目录结构: 代码如下: # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See docu ...
- 第二十四天 框架之痛-Spring MVC(四)
6月3日,晴."绿树浓阴夏日长. 楼台倒影入池塘. 水晶帘动微风起, 满架蔷薇一院香". 以用户注冊过程为例.我们可能会选择继承AbstractController来实现表单的显示 ...
- Swift从入门到精通第十四篇 - 错误处理 初识
错误处理(学习笔记) 环境Xcode 11.0 beta4 swift 5.1 错误表现和抛出 在 swift 中,错误由符合 Error 协议的类型值表示 // 示例 enum VendingMac ...
- Python爬虫(十四)_BeautifulSoup4 解析器
CSS选择器:BeautifulSoup4 和lxml一样,Beautiful Soup也是一个HTML/XML的解析器,主要的功能也是如何解析和提取HTML/XML数据. lxml只会局部遍历,而B ...
- 十四 Django框架,中间件
django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间件中相应的方法. 在django项目的se ...
随机推荐
- 排查 k8s 集群 master 节点无法正常工作的问题
搭建的是 k8s 高可用集群,用了 3 台 master 节点,2 台 master 节点宕机后,仅剩的 1 台无法正常工作. 运行 kubectl get nodes 命令出现下面的错误 The c ...
- bugku 前女友
首先打开链接然后会发现 照常情况下进行分析 查看源码然后发现 在这一串文字后还有一个链接然后 发现链接被隐藏了然后我们将link 删除就会显示出来点开新的连接 然后会发现这个 (仔细一看好像是php中 ...
- 大数据的特征(4V+1O)
数据量大(Volume):第一个特征是数据量大,包括采集.存储和计算的量都非常大.大数据的起始计量单位至少是P(1000个T).E(100万个T)或Z(10亿个T). 类型繁多(Variety):第二 ...
- 生成树计数模板 spoj 104 (不用逆元的模板)
/* 这种题,没理解,只是记一记如何做而已: 生成树的计数--Matrix-Tree定理 题目:SPOJ104(Highways) 题目大意: *一个有n座城市的组成国家,城市1至n编号,其中一些城市 ...
- java 实体类 时间格式字段注解
@DatetimeFormat是将String转换成Date,一般前台给后台传值时用 @JsonFormat(pattern="yyyy-MM-dd") 将Date转换成Strin ...
- docker 报错 docker: Error response from daemon: driver failed....iptables failed:
现象: [root@localhost test]# docker run --name postgres1 -e POSTGRES_PASSWORD=password -p : -d postgre ...
- Python 多任务(线程) day1
多任务就是可以让一台电脑同时执行多个命令. 以前的单核cpu是怎么做到同时执行多个命令的?(时间片轮转) ——其实以前的单核CPU是让操作系统交替执行命令,每个任务执行0.01秒,这样看起来就像是在同 ...
- 自定义控件之绘图篇(四):canvas变换与操作
具体操作见下面链接: http://blog.csdn.net/harvic880925/article/details/39080931/
- Java将数据进行分组处理
将传人的数据进行分组,使用map保存每组的数据. /** * 将取出的数据进行分组 * @param list * @return */ public Map<Integer,Object> ...
- STM32F103_外部RAM用作运存---IS62WV51216
https://www.cnblogs.com/lilto/p/9548736.html STM32F103_外部RAM用作运存 概述 SRAM的简介 折腾过电脑的朋友都知道,当电脑运行比较卡的时 ...