cross_val_score 交叉验证与 K折交叉验证,嗯都是抄来的,自己作个参考
因为sklearn cross_val_score 交叉验证,这个函数没有洗牌功能,添加K 折交叉验证,可以用来选择模型,也可以用来选择特征
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)
这里的cv 可以用下面的kf
关于scoring 参数问题

如果两者都要求高,那就需要保证较高的F1 score
回归类(Regression)问题中
比较常用的是 'neg_mean_squared_error‘ 也就是 均方差回归损失
该统计参数是预测数据和原始数据对应点误差的平方和的均值
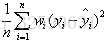
K折交叉验证:sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None)
n_splits:表示划分几等份
shuffle:在每次划分时,是否进行洗牌
random_state:随机种子数
属性:
①get_n_splits(X=None, y=None, groups=None):获取参数n_splits的值
②split(X, y=None, groups=None):将数据集划分成训练集和测试集,返回索引生成器
通过一个不能均等划分的栗子,设置不同参数值,观察其结果
①设置shuffle=False,运行两次,发现两次结果相同
from sklearn.model_selection import KFold
...: import numpy as np
# np.arange(起始,终点,步长)
# np.reshape() 是数组对象中的方法,用于改变数组的形状 这里是12维,每组两个元素
...: X = np.arange(24).reshape(12,2)
...: y = np.random.choice([1,2],12,p=[0.4,0.6])
...: kf = KFold(n_splits=5,shuffle=False)
...: for train_index , test_index in kf.split(X):
...: print('train_index:%s , test_index: %s ' %(train_index,test_index))
----------------------------------------------------------------
train_index:[ 3 4 5 6 7 8 9 10 11] , test_index: [0 1 2]
train_index:[ 0 1 2 6 7 8 9 10 11] , test_index: [3 4 5]
train_index:[ 0 1 2 3 4 5 8 9 10 11] , test_index: [6 7]
train_index:[ 0 1 2 3 4 5 6 7 10 11] , test_index: [8 9]
train_index:[0 1 2 3 4 5 6 7 8 9] , test_index: [10 11]
shuffle=True
train_index:[ 0 1 2 3 4 5 7 8 11] , test_index: [ 6 9 10]
train_index:[ 2 3 4 5 6 8 9 10 11] , test_index: [0 1 7]
train_index:[ 0 1 3 5 6 7 8 9 10 11] , test_index: [2 4]
train_index:[ 0 1 2 3 4 6 7 9 10 11] , test_index: [5 8]
train_index:[ 0 1 2 4 5 6 7 8 9 10] , test_index: [ 3 11]
n_splits 属性值获取方式



这里的cv 可以是cv
cross_val_score 交叉验证与 K折交叉验证,嗯都是抄来的,自己作个参考的更多相关文章
- sklearn的K折交叉验证函数KFold使用
K折交叉验证时使用: KFold(n_split, shuffle, random_state) 参数:n_split:要划分的折数 shuffle: 每次都进行shuffle,测试集中折数的总和就是 ...
- k折交叉验证
原理:将原始数据集划分为k个子集,将其中一个子集作为验证集,其余k-1个子集作为训练集,如此训练和验证一轮称为一次交叉验证.交叉验证重复k次,每个子集都做一次验证集,得到k个模型,加权平均k个模型的结 ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
- 小白学习之pytorch框架(7)之实战Kaggle比赛:房价预测(K折交叉验证、*args、**kwargs)
本篇博客代码来自于<动手学深度学习>pytorch版,也是代码较多,解释较少的一篇.不过好多方法在我以前的博客都有提,所以这次没提.还有一个原因是,这篇博客的代码,只要好好看看肯定能看懂( ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- K折-交叉验证
k-折交叉验证(k-fold crossValidation):在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数据 ...
- 偏差(bias)和方差(variance)及其与K折交叉验证的关系
先上图: 泛化误差可表示为偏差.方差和噪声之和 偏差(bias):学习算法的期望预测与真实结果(train set)的偏离程度(平均预测值与真实值之差),刻画算法本身的拟合能力: 方差(varianc ...
- KFold,StratifiedKFold k折交叉切分
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 模型选择---KFold,StratifiedKFold k折交叉切分
StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同. 例子: import numpy as np from sklearn.m ...
随机推荐
- 「题解」「JZOJ-4238」纪念碑
题目 在 \(N\times M\) 的网格中,有 \(P\) 个矩形建筑,求一个最大边长的正方形,使得网格中能找到一个放置正方形的地方,不会与建筑重合. 保证 \(N,M\le 10^6,P\le ...
- LeetCodr 43 字符串相乘
思路 用一个数组记录乘积的结果,最后处理进位. 代码 class Solution { public: string multiply(string num1, string num2) { if(n ...
- Linux - gitlab的命令
启动 sudo gitlab-ctl start 关闭 sudo gitlab-ctl stop 重新加载配置文件 sudo gitlab-ctl reconfigure 在本地初始化一个本地仓库 g ...
- zabbix-agent不能启动:配置文件出现特殊字符导致
问题如下: 定位查找问题: 命令:journalctl -xe [重点] 图中可见错误信息在zabbix_agent配置文件中的“hostname=”中不能出现特殊字符,我出错的原因是写成了:hos ...
- 转载:进程退出状态--waitpid status意义
最近遇到一个进程突然退出的问题,由于没有注册signalhandler所以没有捕捉到任何信号. 但是从log中看到init waitpid返回的status为0x008b,以前对status不是很了解 ...
- php 移动操作数组函数
下面的几个主要是移动数组指针和压入弹出数组元素的和个函数. 函数 功能 array_shift 弹出数组中的第一个元素 array_unshift 在数组的开始处压入元素 array_push 向数组 ...
- [原]eclipse中spring配置文件的自动提示和命名空间的添加
在用spring或者springmvc框架进行开发时,编辑applicationcontext.xml等配置文件是必不可少的,在eclipse中打开applicationcontext.xml通常是这 ...
- report_delay_calculation/check_timing/report_annotated_parasitics/report_analysis_coverge
如何debug 一颗cell 或一段net 的delay, 常用的办法是用report_delay_calculation 报这颗cell 或这段net, 会得到形式如下的report, 从该rep ...
- Scala实现网站流量实时分析
之前已经完成zookeeper集群.Hadoop集群.HBase集群.Flume.Kafka集群.Spark集群的搭建:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),且离线分析模 ...
- maven版cxf集合spring开发服务端(二)
一.新建一个maven项目 二.pom.xml引入依赖 <dependency> <groupId>org.apache.cxf</groupId> <art ...