stress施压案例分析——cpu、io、mem【命令分析】
stress施压命令分析
一、stress --cpu 1 --timeout 600 分析现象?负载为啥这么高?top命令查看用户进程消耗的cpu过高(stress进程消耗的)
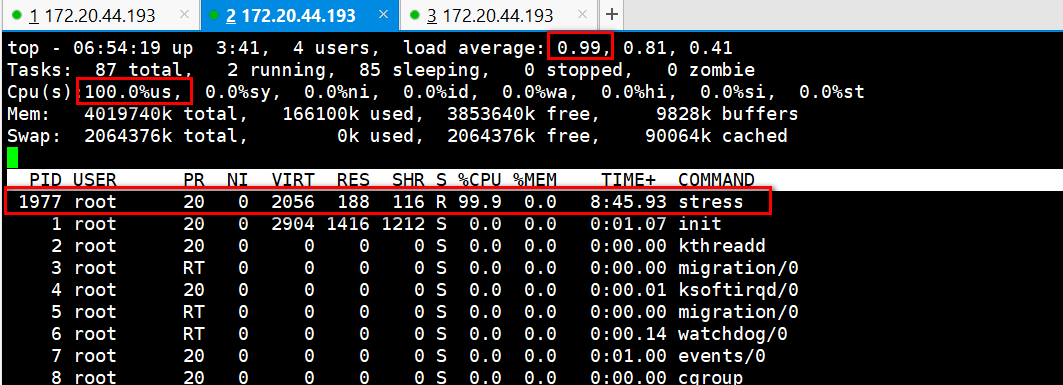
分析现象,可以看出负载很高,用户态的cpu的使用率是100%,stress进程使用的cpu也接近100%。
问题:负载为什么接近于1??
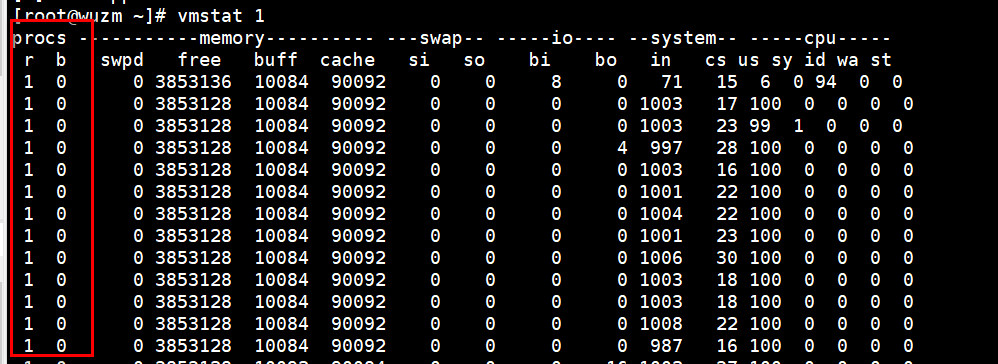
# vmstat 1 查看监控信息
负载=r+b,这是一个瞬时值。

下图可以看出r+b为1,所以这里的负载为1。
这里负载不为2的原因,这里只有一核cpu在干活,也只有一个进程在消耗cpu,所以这里负载是1,不会是2。
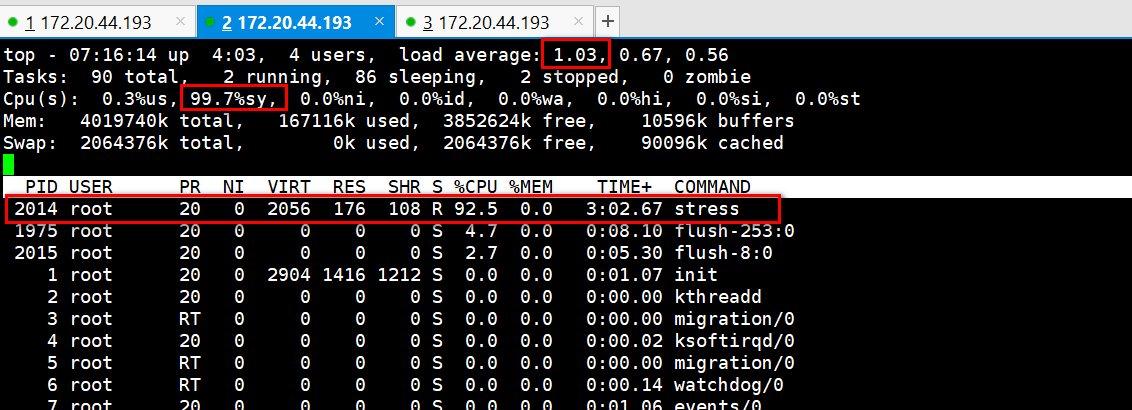
二、stress -i 1 --timeout 600 分析现象?top看负载升高,内核cpu过高? iostat -x 3 stress消耗cpu多,iowait 等待 pidstat -d
正常情况下,这里的iowait也是有数据的,不是0,应该会涨,可能是操作系统版本的原因,或者用stress-ng版本这个加强版
下载地址:https://kernel.ubuntu.com/~cking/tarballs/stress-ng/
安装步骤和stress一样的,需要编译安装。
高版本的stress-ng编译需要高版本的gcc,我这里以前是4.4.7版本的
gcc下载地址:http://www.gnu.org/prep/ftp.html
分析步骤:
top可以看到有iowait ,所以这里可能是io等待导致的。
1、 iostat -x 3
通过iostat 看磁盘的繁忙程度,这里的数据应该是达到20%以上,可以看出磁盘繁忙,还有进程读和写,我这里的操作系统版本太低,所以数据很小。
这里写操作也比较多,怀疑应该每秒写600多,所以磁盘繁忙是大量的写导致的,所以下面使用pidstat再分析。

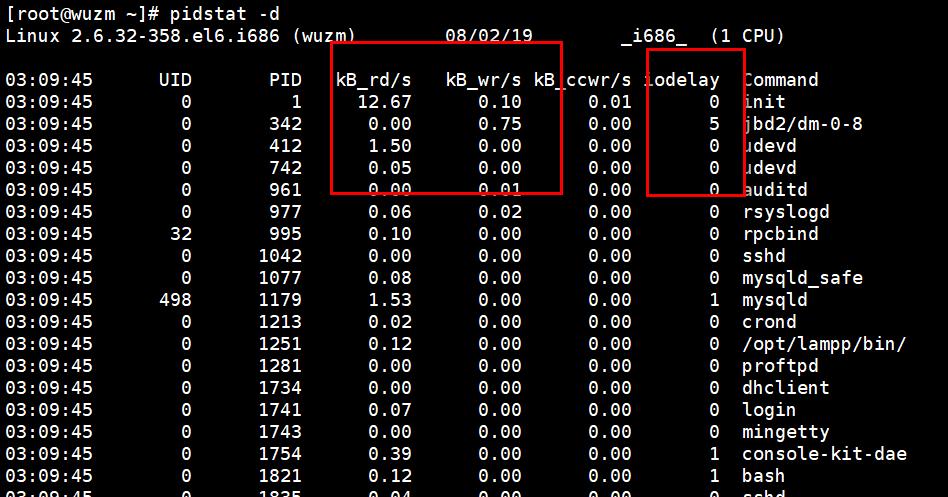
2、pidstat -d 3 查看进程读、进程写、和进程延迟
这里iodelay,这里每次都有java(tomcat)和stress。
这里的写操作比较多,
三、stress -c 8 --timeout 600
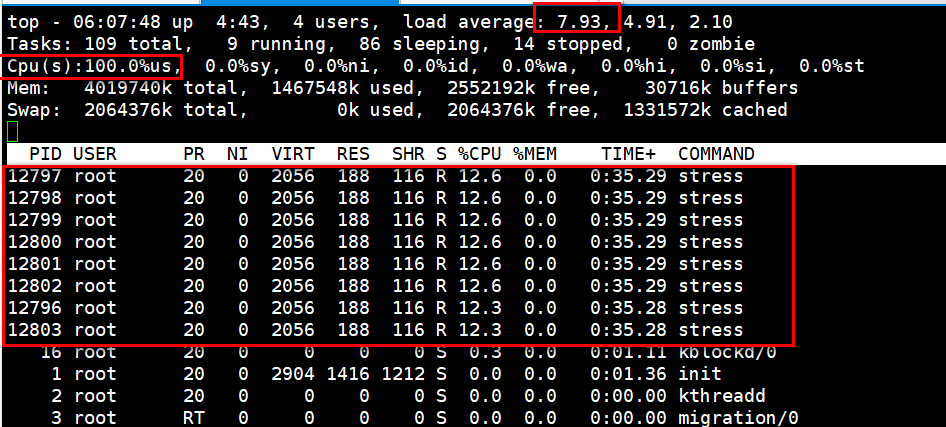
现象:用户cpu已经打满了,负载上升很快,并且很快就到8了,每个进程所占的cpu资源是12%多,就是这8个stress把cpu打满了。
vmstat 1
负载=r+b =8
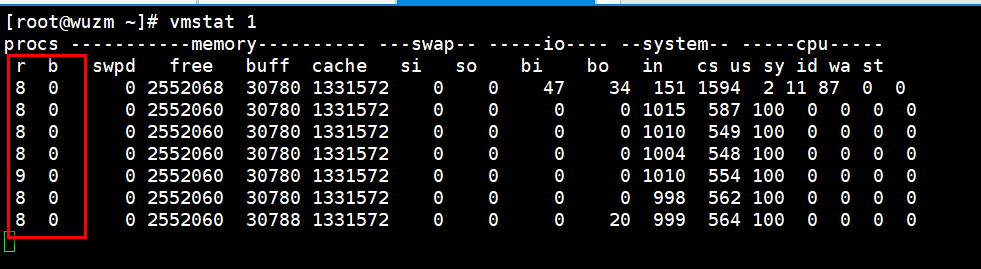
pidstat 3
这里的%wait是等待cpu临幸它所消耗的一个百分比,百分比越高,等待排队的时间越长,和iowait不同。
这里8个进程在抢占cpu,中断和上下文切换会高些。

vmstat 3 查看中断和上下文切换
这里cs应该达到几十万以上,我这里数据不对,
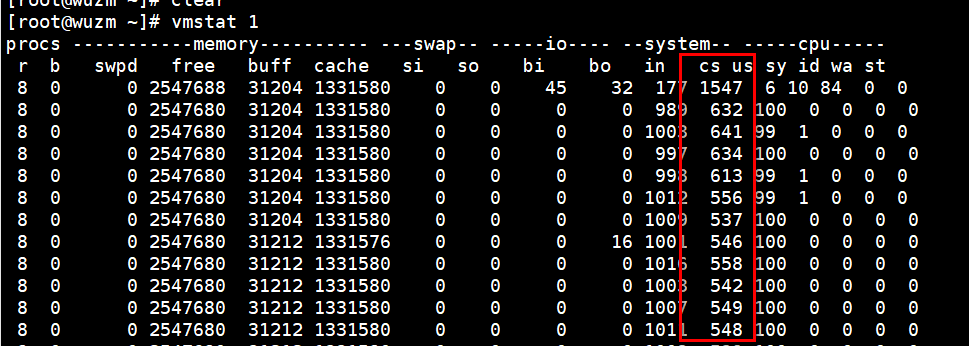

案例:有次压测用的是4核的一个cpu,用20个线程去压,cpu就打满了,到100%
一个tomcat写的java进程,20个并发的是tps大概是90多,30个并发tps是80多,80个并发的时候tps就是70多。
cpu都是打满的,随着并发数的时候,响应时间不断增加,tps不断减小。
什么原因???
响应时间增加怀疑cpu上下文切换导致的线程等待时间比较长,
tomcat打印tomcat整理处理时间,再打印一个接口的一个处理时间,接口处理时间从100ms增加到200ms,但是tomcat的处理时间从1s增加到8s。
随着并发数的增加,tomcat线程池的排队时间从1s增加到8s多,时间耗在哪里了呢,时间耗在了线程的上下文切换上了。
四、sysbench --threads=10 --max-time=300 threads run

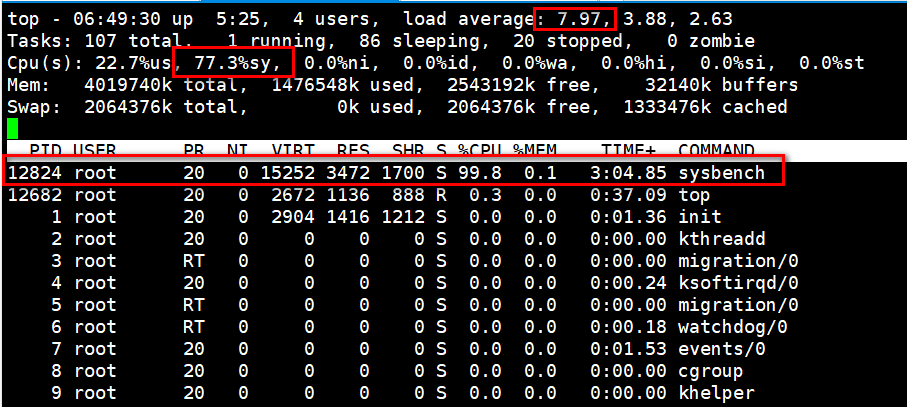
现象:负载很高,大部分还在内核态cpu,看看谁在用内核态cpu?iowait没有,中断没有,也不是虚拟化??那是谁把内核cpu打满了??
最有可能是上下文切换,进程之间上下文切换导致的内核态cpu比较高。
# vmstat 1
可以看到图中cs上下文切换真他妈好高,达到百万级别了。

#pidstat -w 看上下文切换,但是这里啥也看不出来。为啥看不出来呢???
因为???
pidstat默认看的是进程之间的上下文切换,上下文切换的最小单位是线程。
查看线程之间的上下文切换加一个-t参数
pidstat -wt 1
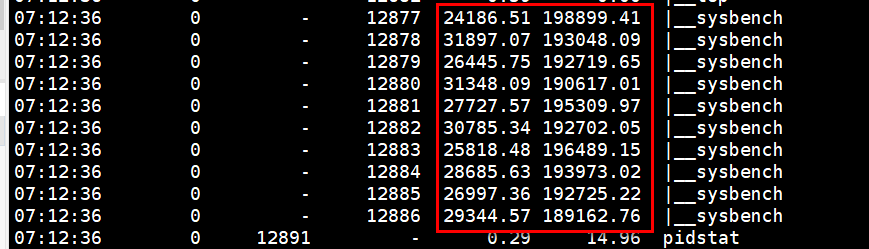
cswch自愿上下文切换:进程无法获取资源导致的上下文切换,比如;I/O,内存资源等系统资源不足,就会发生自愿上下文切换。
nvcswch非自愿上下文切换:进程由于时间片已到,被系统强制调度,进而发生的上下文切换 ,比如大量进程抢占cpu。
python脚本运行分析
五、app.py
python3 app.py 运行python脚本,看现象
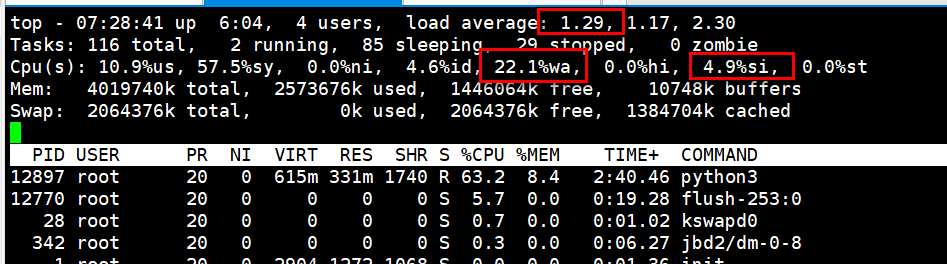
现象:负载上来,这里%iowait特别高,应该是80%多,cpu内核使用也挺高的,top 定位到磁盘有问题。
#vmstat 1
首先查看这里负载为啥升高?负载=r+b
可以看到这里只有一个进程运行也就是r,但是b(中断不可恢复)会有多个,可见负载高是由io导致的。

# iostat -x 3
查看下面的磁盘繁忙程度很高,并且写的排队时间到174多毫秒,写的速度为每秒20多万KB,可见是由大量的写操作导致的磁盘比较繁忙。

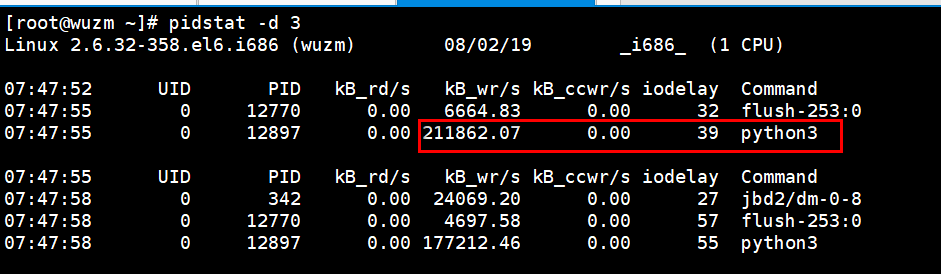
#pidstat -d 3 查看到底是哪个进程导致的iowait,也就是哪个进程在进行大量的写操作。
可以看到是python3这个进程在进行大量地写操作,达到十万级别以上。
分析流程屡一下:
1、top首先看负载高(负载=r+b),vmstat 查看这里是有中断不可恢复的进程的比较多(io操作一般是中断不可恢复的进程,可能是io问题);
2、然后看cpu使用情况,看到cpu这里iowait比较高,可见是由磁盘导致的;
3、然后iostat -x 看磁盘,磁盘这里确实比较繁忙,并且有很疯狂的写操作,磁盘每次操作消耗时间比较长,大部分时间耗排队时间比较长;
4、然后分析到底是哪个进程在进行写操作,这里使用pidstat -d 3 查看是python3进程在进行大量的写操作,消耗io比较高,这里是定位到了进程的层面;
5、对于应用程序要定位到方法层面,为啥导致了写操作比较多,到底在写什么东西呢??
这里可以看到python3的pid 为32488,这里内核调用也挺高的,用strace来跟踪系统内核进程的调用情况。
strace -p 32488
这里是在往logtest.txt写文件,进入到相应目录查看有没有这个文件。
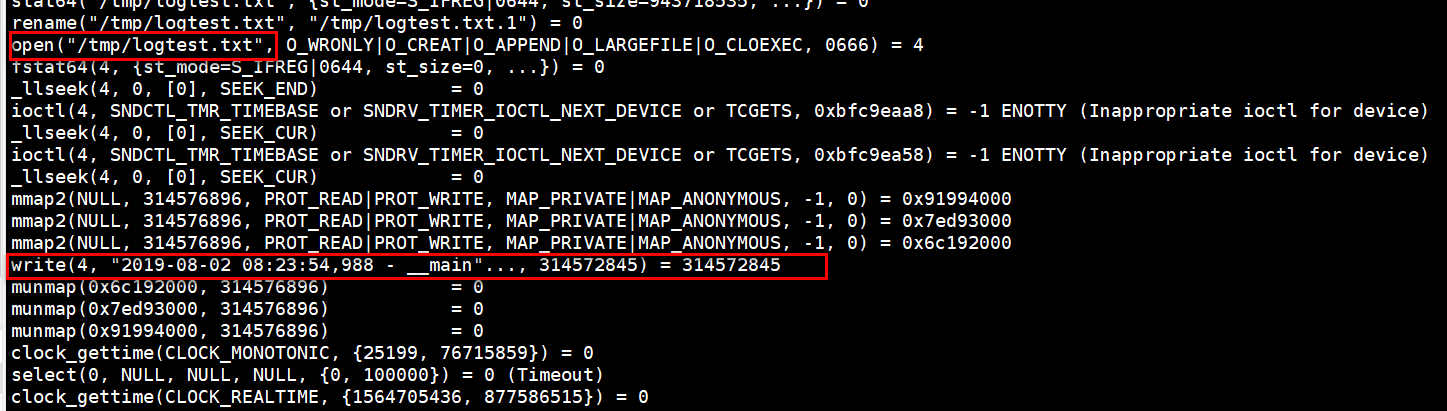

使用lsof查看文件句柄,看都是谁打开的,是python3打开的,目前已经定位到了在写什么了。

6、定位到方法,再去看代码,每次写得很大,大概10M。

六、iolatency.py
负载不高,cpu使用率也不高,iowait也不高,ni 中断都没问题,啥现象都没有,但就是使用的时候,或者使用某个具体功能,访问某个具体的页面的时候响应贼慢。
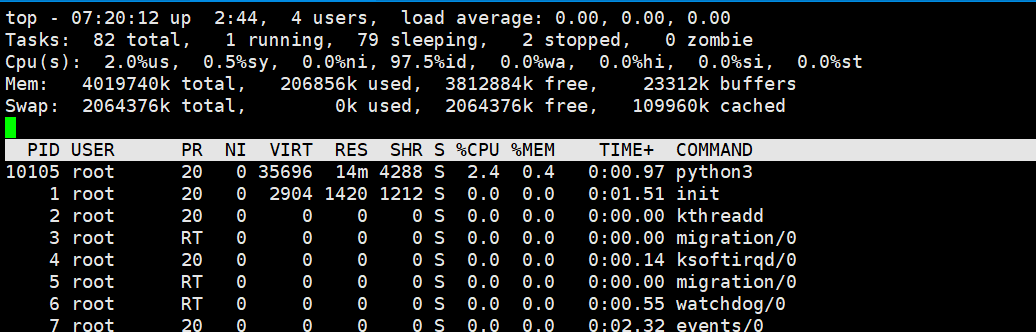
启动的时候,大家可以看到启动了一个ip:80
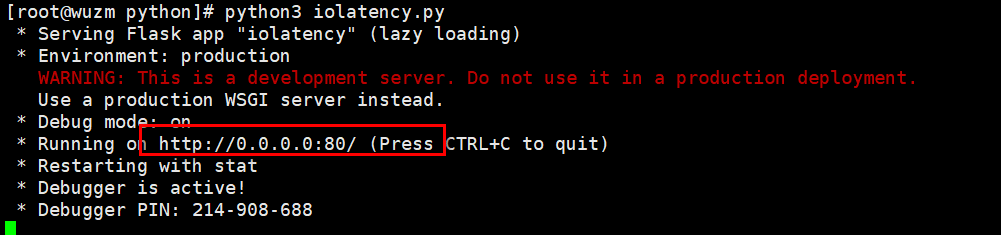
所以这里可以访问一下,192.168.1.17 (http默认80端口,可以不加)大家可以看到这里访问很快
但是如果大家访问 192.168.1.17/popularity/word 就可以看到这里访问贼慢,还没有返回结果。

过了好大一会,才返回如下结果:

这里进行压测该接口 http://192.168.1.17/popularity/word 我们top下观察现象:
这里负载升高、iowait也升高达80%多。
1、负载上去的原因:vmstat 1 b列有许多中断不可恢复的进程。io 里的bo数据很大,是在进行大量的写操作,定位到io问题。
2、iostat -x 3 查看队列、和写的速度都很大,定位到是大量的写操作导致磁盘繁忙和和排队,下面查看是哪个进程在大量地写。
3、pidstat -d 3 确定是python进程在写操作。
4、strace -p <pid>看这个进程在写啥,或者加个过滤条件:strace -p <pid> grep | write,跟踪不到在写啥????
5、filetop (bcc-tools里的一个包,github上下载,源码安装)
stress施压案例分析——cpu、io、mem【命令分析】的更多相关文章
- CPU IO MEM NETWork 监控命令
性能优化中CPU.内存.磁盘IO.网络性能的依赖(上) 性能优化中CPU.内存.磁盘IO.网络性能的依赖(下)
- 历史执行Sql语句性能分析 CPU资源占用时间分析
SELECT HIGHEST_CPU_QUERIES.PLAN_HANDLE, HIGHEST_CPU_QUERIES.TOTAL_WORKER_TIME, Q.DBID, ...
- Linux中IO监控命令的使用分析
一篇不错的有关linux io监控命令的介绍和使用. 1.系统级IO监控 iostat iostat -xdm 1 # 个人习惯 %util 代表磁盘繁忙程度.100% 表示磁盘 ...
- Linux性能分析——分析系统性能相关的命令
Linux性能分析——分析系统性能相关的命令 摘要:本文主要学习了Linux系统中分析性能相关的命令. ps命令 ps命令用来显示系统中进程的运行情况,显示的是当前系统的快照. 基本语法 ps [选项 ...
- Linux下java进程CPU占用率高分析方法
Linux下java进程CPU占用率高分析方法 在工作当中,肯定会遇到由代码所导致的高CPU耗用以及内存溢出的情况.这种情况发生时,我们怎么去找出原因并解决. 一般解决方法是通过top命令找出消耗资源 ...
- Centos下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuni ...
- Linux下的IO监控与分析
Linux下的IO监控与分析 近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performan ...
- 【转载】Linux下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuning G ...
- MySQL中使用SHOW PROFILE命令分析性能的用法整理(配合explain效果更好,可以作为优化周期性检查)
这篇文章主要介绍了MySQL中使用show profile命令分析性能的用法整理,show profiles是数据库性能优化的常用命令,需要的朋友可以参考下 show profile是由Jerem ...
随机推荐
- java IO流的概念与分类
DataInputStream && ObjectInputStream 示例 https://blog.csdn.net/hoho_12/article/details/520543 ...
- PAT Basic 反转链表 (25) [链表]
题目 给定⼀个常数K以及⼀个单链表L,请编写程序将L中每K个结点反转.例如:给定L为1→2→3→4→5→6,K为3,则输出应该为3→2→1→6→5→4:如果K为4,则输出应该为4→3→2→1→5→6, ...
- JAVA--Mybatis-Spring-SpringMVC框架整合
------Mybatis-Spring-SpringMVC框架整合示例----- mybatis SQL映射文件 <?xml version="1.0" encoding= ...
- 简单总结------redis
一.Redis 是一个基于内存的高性能key-value数据库. 二.端口 6379 三.特点: Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在 ...
- 安装R的h5包
系统 redhat7 安装H5的包, 依赖系统hdf5包,如下安装完, 发现版本不一致, sudo yum install hdf5-devel 解决办法: 移花接木 sudo ln -s /opt/ ...
- day55-mysql-用户权限、修改秘密、忘记密码
.用户权限:新创建的用户没有库,如果想让新用户访问我的库,必须给它授权才可以.我在使用的navicat要关闭新用户的连接才可以授权给它. .创建用户 '; -- 创建用户 .移除用户 drop use ...
- DNA methylation|Transcription factors|PTM|Chromosome conformation|表观遗传学测序技术
生物医疗大数据-DNA element functions and identification Genetic vs epigenetic GENETICS 遗传学 DNA Code: 64 tr ...
- Android之布局Application类
转载:https://blog.csdn.net/pi9nc/article/details/11200969 一 Application源码描述 * Base class for maintaini ...
- Sqlite教程(2) Data Access Object
因为这个项目的业务层很薄,因此想在架构上尽量保持着「轻」,不会把创建DbHelper的interface. 而是直接用DAO创建DbHelper对象. DAO和DbHelper也是同样使用懒汉模式. ...
- swift中的坑
1.NSClassFromString //获取工程名称 let group = Bundle.main.infoDictionary let fileName = group?[kCFBundleE ...