Erlang 进程被抢占的条件——一个进程长时霸占调度器的极端示例
最近研究 binary 的实现和各种操作对应的 beam 虚拟机汇编指令,发现有一些指令序列是不可重入的,比如说有的指令构造一个上下文(也就是某种全局状态),然后下一条指令会对这个上下文做操作(具体的场景示例参见这篇博文)。而上下文是调度器内部私有的全局变量。而我们一直在说,Erlang 调度器是抢占式调度器,进程耗光了 reduction 配额之后就会被抢占,那么调度器是怎么保证不可重入的指令序列不会被破坏呢?
关键在于,Erlang 调度器的抢占只会发生在一些特定的点上,像上面的指令序列之间是不会发生抢占的。
在 beam_emu.c 文件中,上下文切换(抢占必然要上下文切换)是通过 Dispatch()、Dispatchx() 和 Dispatchfun() 三个宏完成的,暂不用纠缠这些宏的区别和细节。比如说第一个宏 Dispatch():
- #define DispatchMacro() \
- do { \
- BeamInstr* dis_next; \
- dis_next = (BeamInstr *) *I; \
- CHECK_ARGS(I); \
- if (FCALLS > || FCALLS > neg_o_reds) { \
- FCALLS--; \
- Goto(dis_next); \
- } else { \
- goto context_switch; \
- } \
- } while ()
- # define Dispatch() DispatchMacro()
在 if 语句的 else 分句部分,可以看出 FCALLS 不够了就要 goto 到 context_switch,FCALLS 表示剩余的 reduction 数,context_switch 那里就要调用调度器切换进程了。
在这个文件中搜索一下,差不多可以看出哪些地方调用了这些宏,比如说下面几条和函数调用相关的指令:
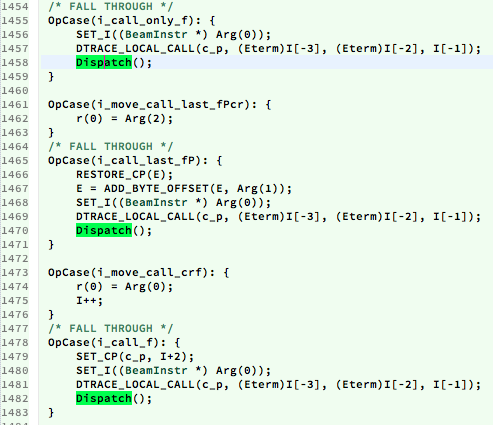
基本上都是和函数调用相关的指令,还有 call_bif,apply 之类的。这说明一个关键点:那就是 Erlang 虚拟机不会在任意指令之间或指令中抢占进程,而是在特定的点会发生抢占。
好消息是,Erlang 的设计使得 Erlang 会经常到达这些特定的点。比如说,Erlang 中没有循环结构,循环是通过递归调用自己实现的,那么这就可以保证超长的“循环”可以被抢占,而这在其他非函数式语言中可能就不好实现了。
再举一个例子,比如说前一篇博文提到的 binary comprehension,代码如下:
- bc(Input) ->
- << <<0, 1, 2, Bin:8/binary>> || <<Bin:8/binary>> <= Input >>.
我一开始担心,这一行中间也没有任何调用,要是 Input 很大该怎么办呢?会不会导致霸占调度器时间过长?不过看了编译器生成的汇编码就不用担心了:

可以看到,在第 12 步,有一条 call_only 指令。尽管第 8 到第 11 步中间的那些指令的序列在 Erlang 虚拟机看来是“原子”的,不会被打断,但是第 12 步就有可能发生抢占。
但是要特别注意的是,我们不能就此完全放心了,中间的这些指令可都是不消耗 reduction 的啊,这些指令还涉及到复制操作,所以如果复制的时间很长,那么这个函数霸占调度器的时间也会更长了。
下面举一个很变态的例子:
- binary_append_longrun(Bin0) ->
- Bin1 = <<Bin0/binary, Bin0/binary, Bin0/binary, Bin0/binary>>,
- Reds1 = erlang:process_info(self(), reductions),
- Bin2 = <<Bin1/binary, Bin1/binary, Bin1/binary, Bin1/binary>>,
- Reds2 = erlang:process_info(self(), reductions),
- Bin3 = <<Bin2/binary, Bin2/binary, Bin2/binary, Bin2/binary>>,
- Reds3 = erlang:process_info(self(), reductions),
- Bin4 = <<Bin3/binary, Bin3/binary, Bin3/binary, Bin3/binary>>,
- Reds4 = erlang:process_info(self(), reductions),
- Bin5 = <<Bin4/binary, Bin4/binary, Bin4/binary, Bin4/binary>>,
- Reds5 = erlang:process_info(self(), reductions),
- Bin6 = <<Bin5/binary, Bin5/binary, Bin5/binary, Bin5/binary>>,
- Reds6 = erlang:process_info(self(), reductions),
- Bin7 = <<Bin6/binary, Bin6/binary, Bin6/binary, Bin6/binary>>,
- Reds7 = erlang:process_info(self(), reductions),
- Bin8 = <<Bin7/binary, Bin7/binary, Bin7/binary, Bin7/binary>>,
- Reds8 = erlang:process_info(self(), reductions),
- Bin9 = <<Bin8/binary, Bin8/binary, Bin8/binary, Bin8/binary>>,
- Reds9 = erlang:process_info(self(), reductions),
- Bin10 = <<Bin9/binary, Bin9/binary, Bin9/binary, Bin9/binary>>,
- Reds10 = erlang:process_info(self(), reductions),
- Bin11 = <<Bin10/binary, Bin10/binary, Bin10/binary, Bin10/binary>>,
- Reds11 = erlang:process_info(self(), reductions),
- Bin12 = <<Bin11/binary, Bin11/binary, Bin11/binary, Bin11/binary>>,
- Reds12 = erlang:process_info(self(), reductions),
- Bin13 = <<Bin12/binary, Bin12/binary, Bin12/binary, Bin12/binary>>,
- Reds13 = erlang:process_info(self(), reductions),
- Bin14 = <<Bin13/binary, Bin13/binary, Bin13/binary, Bin13/binary>>,
- Reds14 = erlang:process_info(self(), reductions),
- Bin15 = <<Bin14/binary, Bin14/binary, Bin14/binary, Bin14/binary>>,
- Reds15 = erlang:process_info(self(), reductions),
- Bin16 = <<Bin15/binary, Bin15/binary, Bin15/binary, Bin15/binary>>,
- Reds16 = erlang:process_info(self(), reductions),
- Res = {Reds1, Reds2, Reds3, Reds4, Reds5, Reds6, Reds7, Reds8, Reds9, Reds10, Reds11, Reds12, Reds13, Reds14, Reds15, Reds16, byte_size(Bin16)},
- Res.
这个变态的函数接受一个 binary Bin0 作为参数。然后 Bin1 变成 4 个 Bin0那么大,Bin2 变成 4 个 Bin1 那么大,以此类推,最后 Bin16 就有 \(4^{16}\) 个 Bin0 那么大了。Bin0 是 1 字节的话,Bin16 就有 4G 字节那么大。Bin15 有 1G 字节那么大。在第 32 行,即使有预分配内存的优化,这一行还得复制 3 次 1G 字节的数据。显然这是非常费时的操作。
为了观察 reduction 的变化,在中间安插了一些 bif 调用获得当前进程的 reduction 值。我们看一下运行结果:
- 461> spawn(fun() -> Res = bin_test:binary_append_longrun(<<0>>), io:format("~p~n", [Res]) end).
- {{reductions,63},
- {reductions,65},
- {reductions,67},
- {reductions,69},
- {reductions,71},
- {reductions,73},
- {reductions,75},
- {reductions,77},
- {reductions,79},
- {reductions,81},
- {reductions,83},
- {reductions,85},
- {reductions,87},
- {reductions,89},
- {reductions,91},
- {reductions,93},
- 4294967296}
- <0.175.1>
在终端 spawn 了一个进程,让新进程去跑这个函数,跑完之后打印最后的结果。结果按下回车之后,shell 失去响应。等了好一阵子之后,才把结果打印出来。从结果可以看出,这个新创建的进程跑到结束也才用了几十个 reduction。而且,整个调度器都失去了响应。怎么说呢?如果调度器有响应的话,新建进程的 pid,也就是 spawn 的返回值,应该很快在 shell 中打印出来,但是直到新进程执行完了才打印出来。而且如果之前打开了 observer 或 etop 之类的工具,GUI 也是在这个进程执行期间没有反应的。可以说,这个进程在跑的时候,Erlang 就没法“实时”了,连“软实时”都没了。
当然,我们在实际写程序的时候不太可能会写出这样变态的极端情况。可是万一呢。。。有些情况下,例如追加特别大的 binary 的情况,而且需要反复执行多次的时候,这个进程扣的 reduction 并不多,所以这种进程可能会破坏系统的响应能力。
Erlang 进程被抢占的条件——一个进程长时霸占调度器的极端示例的更多相关文章
- 并发错误:事务(进程 ID )与另一个进程已被死锁在 lock 资源上,且该事务已被选作死锁牺牲品
这个是并发情况下导致的数据库事务错误,先介绍下背景. 背景 springboot+springmvc+sqlserver+mybatis 一个controller里有五六个接口,这些接口都用到了spr ...
- 事务(进程 ID 64)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品。
访问频率比较高的app接口,在后台写的异常日志会偶尔出现以下错误. 事务(进程 ID 64)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品.请重新运行该事务 实所有的死锁最深层的原因就是一个 ...
- Kettle 解决数据锁的问题(事务(进程 ID 51)与另一个进程被死锁在 锁 资源上)
1.Kettle做了一个作业, 执行的时候问题发生在步骤2和步骤3之间,也就是步骤2还未完全执行完的时候,步骤3就要更新步骤2插入的数据,造成死锁.(我的理解是既然都分开作业了,那么每个作业都是一个单 ...
- C# 最基本的涉及模式(单例模式) C#种死锁:事务(进程 ID 112)与另一个进程被死锁在 锁 | 通信缓冲区 资源上,并且已被选作死锁牺牲品。请重新运行该事务,解决方案: C#关闭应用程序时如何关闭子线程 C#中 ThreadStart和ParameterizedThreadStart区别
C# 最基本的涉及模式(单例模式) //密封,保证不能继承 public sealed class Xiaohouye { //私有的构造函数,保证外部不能实例化 private ...
- SQL Server死锁问题:事务(进程 ID x)与另一个进程被死锁在 锁 | 通信缓冲区资源上并且已被选作死锁牺牲品。请重新运行该事务。
### The error occurred while setting parameters### SQL: update ERP_SCjh_zzc_pl set IF_TONGBU=1 where ...
- 小记:事务(进程 ID 56)与另一个进程被死锁在 锁 | 通信缓冲区 资源上,并且已被选作死锁牺牲品。
今天在做SQL并发UPDATE时遇到一个异常:(代码如下) //Parallel 类可产生并发操作(即多线程) Parallel.ForEach(topics, topic => { //DBH ...
- 事务 ( 进程 ID 60) 与另一个进程被死锁在锁资源上,并且已被选作死锁牺牲品
Select * FROM [TableName] With(NoLock) .....
- Linux进程管理 (2)CFS调度器
关键词: 目录: Linux进程管理 (1)进程的诞生 Linux进程管理 (2)CFS调度器 Linux进程管理 (3)SMP负载均衡 Linux进程管理 (4)HMP调度器 Linux进程管理 ( ...
- 第一次作业:基于Linux 4.5的进程模型与调度器分析
1.操作系统是怎么组织进程的? 1.1什么是线程,什么是进程: 刚接触时可能经常会将这两个东西搞混.简单一点的说,进程是一个大工程,线程则是这个大工程中每个小地方需要做的东西(在linux下看作&qu ...
随机推荐
- iOS-开发技巧-页面布局
#pragma mark - Life Cycle//1.初始化//2.view did load//3.view will appear…#pragma mark - System Delegate ...
- SQL Server技术问题之游标优缺点
分类: MS SQL SERVER 支持三种类型的游标:Transact_SQL 游标,API 服务器游标和客户游标. (1) Transact_SQL 游标 Transact_SQL 游标是由DEC ...
- 【读书笔记】-【编程语言的实现模式】-【LL(1)递归下降的语法解析器】
形如:[a,b,c] [a,[b,cd],f] 为 嵌套列表 其ANTLR文法表示: list :'[' elements ']'; // 匹配方括号 elements : elements (',' ...
- C#开发ActiveX网页截图控件
故事背景:Java组的小伙伴需要一个能在IE(还是6...)下截图并返回给网页的功能,但是IE做起来很麻烦(可能根本做不到),于是找到我写一个ActiveX控件实现此功能,想着可能还有其他小伙伴需要这 ...
- 改变Visual Studio 2012的皮肤
习惯了用vs的绿色背景,vs2012有自己的主题管理工具--Theme Editor vs2012默认没有安装Theme Editor,菜单:工具->扩展和更新,搜索栏里面输入Theme Edi ...
- jQuery实现隐藏标签
要求:用户进入该页面时,品牌列表默认是精简显示,用户可以单击商品列表下方的“显示全部品牌”按钮来显示全部的品牌. <%@ Page Language="C#" Inherit ...
- 记一次纠结Macbook 重装OS X的系统
本文所有图片都是网上截图,不是实操环境.本文不具有教学意义. 起因:Macbook 白苹果了,无限菊花. 我的Macbook 只能装 OS X Mountain Lion 10.8,但是呢 MacBo ...
- knockout的依赖属性dependentObservable的参数 和Value转换器
可写的依赖监控属性ko.dependentObservable的参数 read: 必选,一个用来执行取得依赖监控属性当前值的函数write: 可选,如果声明将使你的依赖属性可写,别的代码如果这个 ...
- sql server 2008还原数据库,出现缺少介质问题
我在sql server2008中备份数据库时,新增了一个自己建立的数据库,备份成功后,在去别的电脑总是还原数据 还原不了,最后在网上找到了解决方案
- csharp: Export DataSet into Excel and import all the Excel sheets to DataSet
/// <summary> /// Export DataSet into Excel /// </summary> /// <param name="send ...