SQL Server里简单参数化的痛苦
在今天的文章里,我想谈下对于即席SQL语句(ad-hoc SQL statements),SQL Server使用的简单参数化(Simple Parameterization)的一些特性和副作用。首先,如果你的SQL语句包含这些,简单参数化不会发生:
- JOIN
- IN
- BULK INSERT
- UNION
- INTO
- DISTINCT
- TOP
- GROUP BY
- HAVING
- COMPUTE
- Sub Queries
一般来说,如果你处理所谓的安全执行计划(Safe Execution Plan),SQL Server自动参数化你的SQL语句:不管提供的参数值,查询总必须通向一样的执行计划。如果你的执行计划里有书签查找,这就是不可能的例子。因为临界点定义了是否进行书签查找还是全表/聚集索引扫描。
自动参数化并不那么酷!
如果SQL Server能自动参数化你的SQL语句,你还是要考虑下SQL Server引入的自动参数化SQL语句的一些副作用。我们来看一个具体的例子。下列查询创建一个表,执行一个会被SQL Server自动参数化的简单SQL语句。
-- Create a simple table
CREATE TABLE Orders
(
Col1 INT IDENTITY(1, 1) PRIMARY KEY NOT NULL,
Price DECIMAL(18, 2)
)
GO -- This query gets auto parametrized, because it is a simple query with a safe (consistent) plan
SELECT * FROM Orders
WHERE Price = 5.70
GO -- Analyze the Plan Cache
SELECT
st.text,
qs.execution_count,
cp.cacheobjtype,
cp.objtype,
cp.*,
qs.*,
p.*
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) p
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
LEFT JOIN sys.dm_exec_query_stats qs ON qs.plan_handle = cp.plan_handle
WHERE st.text LIKE '%Orders%'
GO
然后当你查看计划缓存时,你会看到SQL Server能为你自动参数化SQL语句:
(@1 numeric(3,2))SELECT * FROM [Orders] WHERE [Price]=@1
但什么是选择的作为参数的数据类型?最小可能的那个!在这里是NUMERIC(3,2)!如果现在你执行下列2个查询:
-- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 8.70
GO -- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 124.50
GO
SQL Server能重用为第1个使用8.7值SQL语句的参数化SQL语句的执行计划。但用124.50值的第2个SQL语句呢?对于这个SQL语句缓存的计划不能被重用,因为124.50值不符合NUMERIC(3,2)。在这个情况下,SQL Server用NUMERIC(5,2)数据类型生成你SQL语句的新参数化版本。你刚用你的SQL语句的额外的参数化版本污染了你的计划缓存!当你执行下列语句会变得更糟:
-- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 1204.50
GO
这个会再次给你新的用NUMERIC(6,2)数据类型的新参数化版本——计划缓存里另一个版本!当我展示这个行为的时候,很多人都建议我应该用逆序来执行刚才的SQL语句。我们通过首先清空计划缓存来试下。
-- Clear the Plan Cache
DBCC FREEPROCCACHE
GO -- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 1204.50
GO -- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 124.50
GO -- Execute a slightly different query
SELECT * FROM Orders
WHERE Price = 8.70
GO
然后当你看计划缓存时,没有任何改变:SQL Server还生成了3个不同的参数化SQL语句——每次都用最小可能的数据类型。
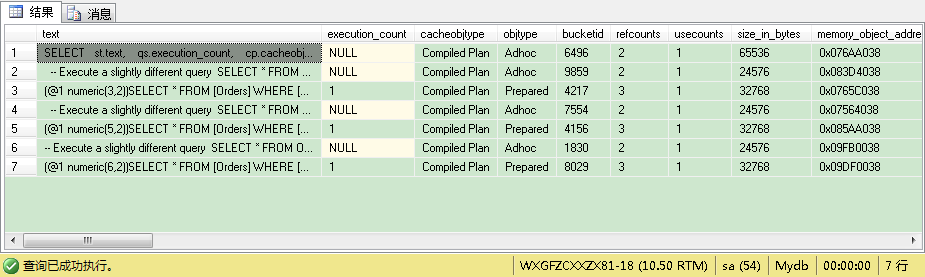
你怎么做没有一点关系,即你执行你SQL语句的顺序:在自动参数化期间,SQL Server总会选择最小可能的数据类型。当你依赖SQL Server这个特性时,好好考虑下。
VARCHAR如何呢?SQL Server自动参数化包含字符值(例如VARCHAR)的SQL语句时,事情会好点。假设有下列表定义和下列2个查询:
-- Create another table to demonstrate this problem
CREATE TABLE Orders3
(
Col1 INT IDENTITY(1, 1) PRIMARY KEY NOT NULL,
Col2 VARCHAR(100)
)
GO -- Clears the Plan Cache
DBCC FREEPROCCACHE
GO -- A VARCHAR/CHAR column is always auto parametrized to a VARCHAR(8000)
SELECT * FROM Orders3
WHERE Col2 = 'Woody'
GO -- A VARCHAR column is always auto parametrized to a VARCHAR(8000)
SELECT * FROM Orders3
WHERE Col2 = 'Tu'
GO
在这个情况下,SQL Server用VARCHAR(8000)生成1个自动参数化SQL语句——最大可能的数据类型。从刚才例子里,这是你所期待的行为。有时SQL Server好事坏事同时做……
小结
当你和简单SQL语句打交道时,自动参数化可以非常棒。但如你在这个文章里所见,你要知道SQL Server引入的副作用。另外SQL Server的简单参数化特性还会提供你强制参数化(Forced Parameterization)功能,这个我会在以后的文章里介绍。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/04/27/the-pain-of-simple-parameterization-in-sql-server/
SQL Server里简单参数化的痛苦的更多相关文章
- SQL Server里强制参数化的痛苦
几天前,我写了篇SQL Server里简单参数化的痛苦.今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization). 强制参数化(Forced Par ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server里的文件和文件组
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组.当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个 ...
- 在SQL Server里我们为什么需要意向锁(Intent Locks)?
在1年前,我写了篇在SQL Server里为什么我们需要更新锁.今天我想继续这个讨论,谈下SQL Server里的意向锁,还有为什么需要它们. SQL Server里的锁层级 当我讨论SQL Serv ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
- SQL Server里ORDER BY的歧义性
在今天的文章里,我想谈下SQL Server里非常有争议和复杂的话题:ORDER BY子句的歧义性. 视图与ORDER BY 我们用一个非常简单的SELECT语句开始. -- A very simpl ...
- SQL Server里等待统计(Wait Statistics)介绍
在今天的文章里我想详细谈下SQL Server里的统计等待(Wait Statistics),还有她们如何帮助你立即为什么你的SQL Server当前很慢.一提到性能调优,对我来说统计等待是SQL S ...
- SQL Server里的INTERSECT ALL
在上一篇文章里,我讨论了INTERSECT设置操作的基础,它和INNER JOIN的区别,还有为什么需要好的索引设计支持.今天我想谈下SQL Server里并未实现的INTERSECT ALL操作. ...
- SQL Server里的INTERSECT
在今天的文章里,我想讨论下SQL Server里的INTERSECT设置操作.INTERSECT设置操作彼此交叉2个记录集,返回2个集里列值一样的记录.下图演示了这个概念. INTERSECT与INN ...
随机推荐
- 【CUDA学习】共享存储器
下面简单介绍一些cuda中的共享存储器和全局存储器 共享存储器,shared memory,可以被同一块中的所有线程访问的可读写存储器,生存期是块的生命期. Tesla的每个SM拥有16KB共享存储器 ...
- 使用Installutil安装系统服务方法
系统必须装有.net Framework2.0然后点击开始-运行输入以下指令即可完成相应操作安装服务:C:/WINDOWS/Microsoft.NET/Framework/v2.0.50727/Ins ...
- (转)c#.net常用字符串函数
Compare 比较字符串的内容,考虑文化背景(场所),确定某些字符是否相等 CompareOrdinal 与Compare一样,但不考虑文化背景 Format 格式化包含各种值的字符串和如何格式化每 ...
- [转]Java Spring的Ioc控制反转Java反射原理
转自:http://www.kokojia.com/article/12598.html 学习一个东西的时候,如果想弄明白,最好想想框架内部是如何实现的,如果是我做我会怎么实现.下面我就写一个Ioc ...
- 谢谢博客-园,让我不再有开源AYUI的想法
第一次 第二次 教程不会在博客园上写了,具体的看我官网博客吧,谢谢大家了 ================= 我是个有素质的程序员 艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹艹 ...
- VS常用的配置和插件
- 太阳升起并下落的小动画-SWIFT
一个小小的动画,太阳公公上山又下山.先上效果图. 用 lipecap 录的gif效果有点卡顿.好吧,说下如何实现的. 首先在一个大圆内先计算出内切九边形各个顶点的位置,接着连接相应的顶点变成一个九角星 ...
- 关于 Redis 访问安全性的问题
升级版本 3.0.2 版本升级到 redis-3.2.0 版本远程无法访问,比较配置文件有些变化,比如默认只能本地的机器才能访问 3.0.2 版本 # By default Redis listens ...
- Openvswitch原理与代码分析(1):总体架构
一.Opevswitch总体架构 Openvswitch的架构网上有如下的图表示: 每个模块都有不同的功能 ovs-vswitchd 为主要模块,实现交换机的守护进程daemon ...
- [论文笔记] Legacy Application Migration to the Cloud: Practicability and Methodology (SERVICES, 2012)
Quang Hieu Vu, Rasool Asal: Legacy Application Migration to the Cloud: Practicability and Methodolog ...