SSD-tensorflow-2 制作自己的数据集
VOC2007数据集格式:
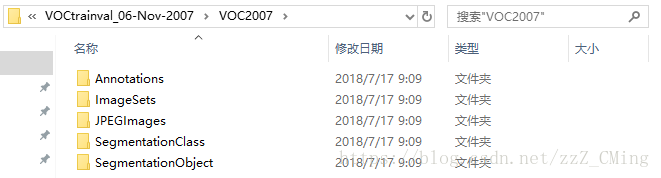
VOC2007详细介绍在这里,提供给大家有兴趣作了解。而制作自己的数据集只需用到前三个文件夹,所以请事先建好这三个文件夹放入同一文件夹内,同时ImageSets文件夹内包含Main文件夹
JPEGImages:用于存放训练、测试的图片(图片格式最好为.jpg)
Annatations:用于存放.xml格式的文件,也就是图片对应的标签,每个.xml文件都对应于JPEGImages文件夹的一张图片
ImageSets:内含Main文件夹,在…/ImageSets/Main文件夹下包含test.txt、train.txt、val.txt、trainval.txt四个文件,生成的方式第二步有详细说明
第一步
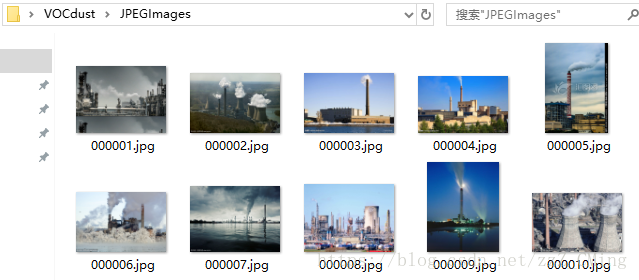
下载图片,存入JPEGImages文件夹——你可以直接从各种渠道下载得到所需要的图片集,存入到JPEGImages文件夹下,命名格式统一为“00xxxx.jpg”,如下图:
第二步
使用labelImg工具给图片打标签——这是最重要的一步。如果你的python已经pip install lxml下载了lxml,
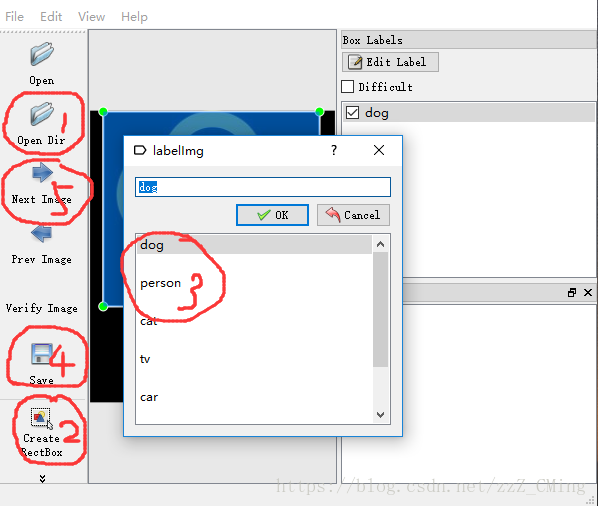
labelImg工具简单的使用步骤就是:
打开单个文件,或者打开一个图片文件夹
给目标物体建立box边框
对box边框内的物体贴上标签
把一张图片内所有目标物都打上各自标签后,再保存生成.xml文件,注意存入Annatations文件夹,文件名也要与当前图片保存一致
然后next下一张图片继续打标签,直到所有图片内物体都打上了标签,最后exit
第三步
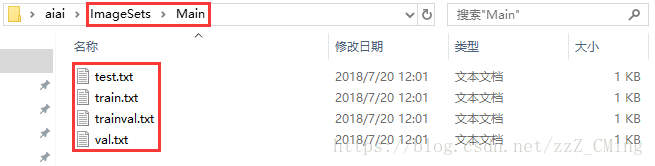
生成Main文件夹下的.txt文件——在主目录下运行以下代码既可生成test.txt、train.txt、val.txt、trainval.txt四个文件,请注意每一个path地址是否正确(其实这四个txt文件在后续并没有什么用处)
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
# -*- 2018/07/18; 15:19
# -*- python3.5
import os
import random trainval_percent = 0.7
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath) num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval = random.sample(list,tv)
train = random.sample(trainval,tr) ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w') for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name) ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
print('Well Done!!!')
运行完成,得到如下文件:可以打开看一看,内容就是各个图片的索引,意味着哪些图片用做训练,哪些用做测试。
第四步
用.xml标签,生成.tfrecord文件
说明:SSD框架所用到的标签文件并不直接是.xml格式文件,而是.tfrecord文件
特别注意:要在主目录提前建好tfrecords_文件夹,不然会报错找不到目标文件夹
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
# -*- 2018/07/17; 13:18
# -*- python3.5
"""
特别注意: path地址是否正确、要在主目录下提前创建“tfrecords_”文件夹
""" import os
import sys
import random
import numpy as np
import tensorflow as tf
import xml.etree.ElementTree as ET # 操作xml文件 # 我的标签定义只有两类,要根据自己的图片而定
VOC_LABELS = {
'none': (0, 'Background'),
'aiaitie': (1, 'Product')
} # 图片和标签存放的文件夹.
DIRECTORY_ANNOTATIONS = 'Annotations/'
DIRECTORY_IMAGES = 'JPEGImages/' # 随机种子.
RANDOM_SEED = 4242
SAMPLES_PER_FILES = 3 # 每个.tfrecords文件包含几个.xml样本 # 生成整数型,浮点型和字符串型的属性
def int64_feature(value):
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value)) def float_feature(value):
if not isinstance(value, list):
value = [value]
return tf.train.Feature(float_list=tf.train.FloatList(value=value)) def bytes_feature(value):
if not isinstance(value, list):
value = [value]
return tf.train.Feature(bytes_list=tf.train.BytesList(value=value)) # 图片处理
def _process_image(directory, name):
# Read the image file.
filename = directory + DIRECTORY_IMAGES + name + '.jpg'
image_data = tf.gfile.FastGFile(filename, 'rb').read() # Read the XML annotation file.
filename = os.path.join(directory, DIRECTORY_ANNOTATIONS, name + '.xml')
tree = ET.parse(filename)
root = tree.getroot() # Image shape.
size = root.find('size')
shape = [int(size.find('height').text),
int(size.find('width').text),
int(size.find('depth').text)]
# Find annotations.
bboxes = []
labels = []
labels_text = []
difficult = []
truncated = []
for obj in root.findall('object'):
label = obj.find('name').text
labels.append(int(VOC_LABELS[label][0]))
labels_text.append(label.encode('ascii')) # 变为ascii格式 if obj.find('difficult'):
difficult.append(int(obj.find('difficult').text))
else:
difficult.append(0)
if obj.find('truncated'):
truncated.append(int(obj.find('truncated').text))
else:
truncated.append(0) bbox = obj.find('bndbox')
a = float(bbox.find('ymin').text) / shape[0]
b = float(bbox.find('xmin').text) / shape[1]
a1 = float(bbox.find('ymax').text) / shape[0]
b1 = float(bbox.find('xmax').text) / shape[1]
a_e = a1 - a
b_e = b1 - b
if abs(a_e) < 1 and abs(b_e) < 1:
bboxes.append((a, b, a1, b1)) return image_data, shape, bboxes, labels, labels_text, difficult, truncated # 转化样例
def _convert_to_example(image_data, labels, labels_text, bboxes, shape,
difficult, truncated):
xmin = []
ymin = []
xmax = []
ymax = []
for b in bboxes:
assert len(b) == 4
# pylint: disable=expression-not-assigned
[l.append(point) for l, point in zip([ymin, xmin, ymax, xmax], b)]
# pylint: enable=expression-not-assigned image_format = b'JPEG'
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': int64_feature(shape[0]),
'image/width': int64_feature(shape[1]),
'image/channels': int64_feature(shape[2]),
'image/shape': int64_feature(shape),
'image/object/bbox/xmin': float_feature(xmin),
'image/object/bbox/xmax': float_feature(xmax),
'image/object/bbox/ymin': float_feature(ymin),
'image/object/bbox/ymax': float_feature(ymax),
'image/object/bbox/label': int64_feature(labels),
'image/object/bbox/label_text': bytes_feature(labels_text),
'image/object/bbox/difficult': int64_feature(difficult),
'image/object/bbox/truncated': int64_feature(truncated),
'image/format': bytes_feature(image_format),
'image/encoded': bytes_feature(image_data)}))
return example # 增加到tfrecord
def _add_to_tfrecord(dataset_dir, name, tfrecord_writer):
image_data, shape, bboxes, labels, labels_text, difficult, truncated = \
_process_image(dataset_dir, name)
example = _convert_to_example(image_data, labels, labels_text,
bboxes, shape, difficult, truncated)
tfrecord_writer.write(example.SerializeToString()) # name为转化文件的前缀
def _get_output_filename(output_dir, name, idx):
return '%s/%s_%03d.tfrecord' % (output_dir, name, idx) def run(dataset_dir, output_dir, name='voc_train', shuffling=False):
if not tf.gfile.Exists(dataset_dir):
tf.gfile.MakeDirs(dataset_dir) path = os.path.join(dataset_dir, DIRECTORY_ANNOTATIONS)
filenames = sorted(os.listdir(path)) # 排序
if shuffling:
random.seed(RANDOM_SEED)
random.shuffle(filenames) i = 0
fidx = 0
while i < len(filenames):
# Open new TFRecord file.
tf_filename = _get_output_filename(output_dir, name, fidx)
with tf.python_io.TFRecordWriter(tf_filename) as tfrecord_writer:
j = 0
while i < len(filenames) and j < SAMPLES_PER_FILES:
sys.stdout.write(' Converting image %d/%d \n' % (i + 1, len(filenames))) # 终端打印,类似print
sys.stdout.flush() # 缓冲 filename = filenames[i]
img_name = filename[:-4]
_add_to_tfrecord(dataset_dir, img_name, tfrecord_writer)
i += 1
j += 1
fidx += 1 print('\nFinished converting the Pascal VOC dataset!') # 原数据集路径,输出路径以及输出文件名,要根据自己实际做改动
dataset_dir = "C:/Users/Admin/Desktop/"
output_dir = "./tfrecords_"
name = "voc_train" def main(_):
run(dataset_dir, output_dir, name) if __name__ == '__main__':
tf.app.run()
得到的.tfrecords文件如下:

SSD-tensorflow-2 制作自己的数据集的更多相关文章
- 仿照CIFAR-10数据集格式,制作自己的数据集
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50801226 前一篇博客:C/C++ ...
- tensorflow 使用tfrecords创建自己数据集
直接采用矩阵方式建立数据集见:https://www.cnblogs.com/WSX1994/p/10128338.html 制作自己的数据集(使用tfrecords) 为什么采用这个格式? TFRe ...
- 自动化工具制作PASCAL VOC 数据集
自动化工具制作PASCAL VOC 数据集 1. VOC的格式 VOC主要有三个重要的文件夹:Annotations.ImageSets和JPEGImages JPEGImages 文件夹 该文件 ...
- matlab遍历文件制作自己的数据集 .mat文件
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/9115788.html 看到深度学习里面的教学动不动就是拿MNIST数据集,或者是IMGPACK ...
- Windows10+YOLOv3实现检测自己的数据集(1)——制作自己的数据集
本文将从以下三个方面介绍如何制作自己的数据集 数据标注 数据扩增 将数据转化为COCO的json格式 参考资料 一.数据标注 在深度学习的目标检测任务中,首先要使用训练集进行模型训练.训练的数据集好坏 ...
- Tensorflow创建和读取17flowers数据集
http://blog.csdn.net/sinat_16823063/article/details/53946549 Tensorflow创建和读取17flowers数据集 标签: tensorf ...
- 在C#下使用TensorFlow.NET训练自己的数据集
在C#下使用TensorFlow.NET训练自己的数据集 今天,我结合代码来详细介绍如何使用 SciSharp STACK 的 TensorFlow.NET 来训练CNN模型,该模型主要实现 图像的分 ...
- TensorFlow从0到1之TensorFlow逻辑回归处理MNIST数据集(17)
本节基于回归学习对 MNIST 数据集进行处理,但将添加一些 TensorBoard 总结以便更好地理解 MNIST 数据集. MNIST由https://www.tensorflow.org/get ...
- 【目标检测】SSD+Tensorflow 300&512 配置详解
SSD_300_vgg和SSD_512_vgg weights下载链接[需要科学上网~]: Model Training data Testing data mAP FPS SSD-300 VGG-b ...
随机推荐
- systemd服务管理---systemctl命令列出所有服务
1.列出系统所有服务 #systemctl list-units --all --type=service
- Linux常用命令之rpm安装命令
转自:http://www.cnblogs.com/datasyman/p/6942557.html 在 Linux 操作系统下,几乎所有的软件均通过RPM 进行安装.卸载及管理等操作.RPM 的全称 ...
- Windows 10 秋季更新错误
uefi 启动丢失修复 bcdboot c:\windows /s y: /f uefi /l zh-cn 0x80240034 你尝试安装的内部版本是有签名的外部测试版.若要继续安装,请启用外部测试 ...
- Tarjan专题
前排Orz tarjan tarjan算法在图的连通性方面有非常多的应用,dfn和low数组真是奥妙重重(并没有很搞懂反正背就完事了) 有向图强连通分量 #include<iostream> ...
- tensorflow学习笔记(一)安装
1.tensorflow介绍 中文社区地址 http://www.tensorfly.cn/ TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库. ...
- C#获取实例运行时间StopWatch类
在程序运行时有时需要获取某一步骤的操作时间,C#提供的StopWatch类可以很方便的实现这一目的. StopWatch sw=new StopWatch(); sw.Start(); //Do So ...
- HDU-4296 Buildings 贪心 从相邻元素的相对位置开始考虑
题目链接:https://cn.vjudge.net/problem/HDU-4296 题意 有很多板子,每一个板子有重量(w)和承重(s)能力 现规定一块板子的PDV值为其上所有板子的重量和减去这个 ...
- 51nod 1321 收集点心(最小割)
给出一种最小割的方法. 设\(num1[i]\),\(num2[i]\)为第i种形状的点心的两种口味的数量 设\(type[i]\),\(type[i]\)为第i种形状的点心的两种口味 假设\(num ...
- 紫书 习题 11-8 UVa 1663 (最大流求二分图最大基数匹配)
很奇怪, 看到网上用的都是匈牙利算法求最大基数匹配 紫书上压根没讲这个算法, 而是用最大流求的. 难道是因为第一个人用匈牙利算法然后其他所有的博客都是看这个博客的吗? 很有可能-- 回归正题. 题目中 ...
- 紫书 例题11-8 UVa 11082(网络流最大流)
这道题的建模真的非常的秀, 非常牛逼. 先讲建模过程.源点到每一行连一条弧, 容量为这一行的和减去列数, 然后每一列到汇点连一条弧, 容量为这一列 的和减去行数, 然后每一行和列之间连一条弧, 容量为 ...