大数据学习[16]--使用scroll实现Elasticsearch数据遍历和深度分页[转]
作者:星爷
出处:
http://lxWei.github.io/posts/%E4%BD%BF%E7%94%A8scroll%E5%AE%9E%E7%8E%B0Elasticsearch%E6%95%B0%E6%8D%AE%E9%81%8D%E5%8E%86%E5%92%8C%E6%B7%B1%E5%BA%A6%E5%88%86%E9%A1%B5.html
背景
Elasticsearch 是一个实时的分布式搜索与分析引擎,被广泛用来做全文搜索、结构化搜索、分析。在使用过程中,有一些典型的使用场景,比如分页、遍历等。在使用关系型数据库中,我们被告知要注意甚至被明确禁止使用深度分页,同理,在 Elasticsearch 中,也应该尽量避免使用深度分页。这篇文章主要介绍 Elasticsearch 中使用分页的方式、Elasticsearch 搜索执行过程以及为什么深度分页应该被禁止,最后再介绍使用 scroll 的方式遍历数据。
Elasticsearch 搜索内部执行原理
一个最基本的 Elasticsearch 查询语句是这样的:
POST /my_index/my_type/_search
{
"query": { "match_all": {}},
"from": 100,
"size": 10
}
上面的查询表示从搜索结果中取第100条开始的10条数据。下面讲解搜索过程时也以这个请求为例。
那么,这个查询语句在 Elasticsearch 集群内部是怎么执行的呢?为了方便描述,我们假设该 index 只有primary shards,没有 replica shards。
在 Elasticsearch 中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些doc,fetch 阶段取出具体的 doc。
Query 阶段

如上图所示,描述了一次搜索请求的 query 阶段。
- Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为 from + size 的优先级队列用来存结果,我们管 node1 叫 coordinating node。
- coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列里,可以把优先级队列理解为一个包含 top N 结果的列表。
- 每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
在上面的例子中,coordinating node 拿到 (from + size) * 6 条数据,然后合并并排序后选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。另外,各个分片返回给 coordinating node 的数据用于选出前 from + size 条数据,所以,只需要返回唯一标记 doc 的 _id 以及用于排序的 _score 即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
Fetch 阶段
query 阶段知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。
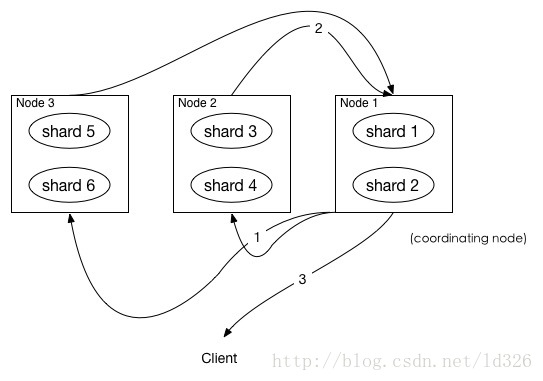
上图展示了 fetch 过程:
- coordinating node 发送 GET 请求到相关shards。
- shard 根据 doc 的 _id 取到数据详情,然后返回给 coordinating node。
- coordinating node 返回数据给 Client。
coordinating node 的优先级队列里有 from + size 个 _doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。
深度分页的问题
Elasticsearch 的这种方式提供了分页的功能,同时,也有相应的限制。举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1,000,000,size=100,这时候,会带来严重的性能问题:
- CPU
- 内存
- IO
- 网络带宽
CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在 query 阶段,每个shards需要返回 1,000,100 条数据给 coordinating node,而 coordinating node 需要接收 10 * 1,000,100 条数据,即使每条数据只有 _doc _id 和 _score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
在另一方面,我们意识到,这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前100页。
不过,这种深度分页确实存在,比如,被爬虫了,这个时候,直接干掉深度分页就好;又或者,业务上有遍历数据的需要,比如,有1千万粉丝的微信大V,要给所有粉丝群发消息,或者给某省粉丝群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用 from + size 来实现,不过,这个是不现实的,这时,可以采用 Elasticsearch 提供的 scroll 方式来实现遍历。
利用 scroll 遍历数据
可以把 scroll 理解为关系型数据库里的 cursor,因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
可以把 scroll 分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。
使用介绍
下面介绍下scroll的使用,可以通过 Elasticsearch 的 HTTP 接口做试验下,包括初始化和遍历两个部分。
初始化
POST ip:port/my_index/my_type/_search?scroll=1m
{
"query": { "match_all": {}}
}
初始化时需要像普通 search 一样,指明 index 和 type (当然,search 是可以不指明 index 和 type 的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
初始化返回一个 _scroll_id,_scroll_id 用来下次取数据用。
遍历
POST /_search?scroll=1m
{
"scroll_id":"XXXXXXXXXXXXXXXXXXXXXXX I am scroll id XXXXXXXXXXXXXXX"
}
这里的 scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id,同样的,需要带 scroll 参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。
设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟空间有限。
Scroll-Scan
Elasticsearch 提供了 Scroll-Scan 方式进一步提高遍历性能。还是上面的例子,微信大V要给粉丝群发这种后台任务,是不需要关注顺序的,只要能遍历所有数据即可,这时候,就可以用Scroll-Scan。
Scroll-Scan 的遍历与普通 Scroll 一样,初始化存在一点差别。
POST ip:port/my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
"query": { "match_all": {}}
}
需要指明参数:
- search_type。赋值为scan,表示采用 Scroll-Scan 的方式遍历,同时告诉 Elasticsearch 搜索结果不需要排序。
- scroll。同上,传时间。
- size。与普通的 size 不同,这个 size 表示的是每个 shard 返回的 size 数,最终结果最大为 number_of_shards * size。
Scroll-Scan 方式与普通 scroll 有几点不同:
- Scroll-Scan 结果没有排序,按 index 顺序返回,没有排序,可以提高取数据性能。
- 初始化时只返回 _scroll_id,没有具体的 hits 结果。
- size 控制的是每个分片的返回的数据量而不是整个请求返回的数据量。
Java 实现
用 Java 举个例子。
初始化
try {
response = esClient.prepareSearch(index)
.setTypes(type)
.setSearchType(SearchType.SCAN)
.setQuery(query)
.setScroll(new TimeValue(timeout))
.setSize(size)
.execute()
.actionGet();
} catch (ElasticsearchException e) {
// handle Exception
}
初始化返回 _scroll_id,然后,用 _scroll_id 去遍历,注意,上面的query是一个JSONObject,不过这里很多种实现方式,我这儿只是个例子。
遍历
try {
response = esClient.prepareSearchScroll(scrollId)
.setScroll(new TimeValue(timeout))
.execute()
.actionGet();
} catch (ElasticsearchException e) {
// handle Exception
}
总结
- 深度分页不管是关系型数据库还是Elasticsearch还是其他搜索引擎,都会带来巨大性能开销,特别是在分布式情况下。
- 有些问题可以考业务解决而不是靠技术解决,比如很多业务都对页码有限制,google 搜索,往后翻到一定页码就不行了。
- Elasticsearch 提供的 Scroll 接口专门用来获取大量数据甚至全部数据,在顺序无关情况下,首推Scroll-Scan。
- 描述搜索过程时,为了简化描述,假设 index 没有备份,实际上,index 肯定会有备份,这时候,就涉及到选择 shard。
PS:Elasticsearch 各个版本可能有区别,但原理基本相同,本文包括文末的代码都基于Elasticsearch 1.3。
大数据学习[16]--使用scroll实现Elasticsearch数据遍历和深度分页[转]的更多相关文章
- django学习-16.返回给前端页面数据为json数据类型的3种方案
目录结构 1.前言 2.JsonResponse类的源码简单分析 2.1.JsonResponse类的源码如下所示 2.2.JsonResponse类的构造函数里的每个入参的大概含义和作用 3.[方案 ...
- es学习(二):elasticsearch 数据存储
当服务器上 es安装好后,第一步就是数据的增删改查. 有一些概念: 索引: 索引是集群用来存放数据的地方,可以理解为一个数据库. index_type:索引类型,数据在索引中按照type存放.可以理 ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- Elasticsearch 在分布式系统中深度分页问题
理解为什么深度分页是有问题的,我们可以假设在一个有 5 个主分片的索引中搜索. 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 5 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
随机推荐
- luogu2765 魔术球问题 网络流
题目大意: 假设有n根柱子,现要按下述规则在这n根柱子中依次放入编号为1,2,3,...的球.(1)每次只能在某根柱子的最上面放球.(2)在同一根柱子中,任何2个相邻球的编号之和为完全平方数.试设计一 ...
- Android系统Recovery工作原理之使用update.zip升级过程分析(六)---Recovery服务流程细节【转】
本文转载自:http://blog.csdn.net/mu0206mu/article/details/7465439 Android系统Recovery工作原理之使用update.zip升级过程分 ...
- Android+Jquery Mobile学习系列(5)-SQLite数据库
SQLite是轻量级的.嵌入式的.关系型数据库,目前已经在iPhone.Android等手机系统中使用,SQLite可移植性好,很容易使用,很小,高效而且可靠. 因为Android已经集成了SQLit ...
- hdu4405Aeroplane chess(概率与期望dp)
Aeroplane chess Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)T ...
- 数据通讯与网络 第五版第24章 传输层协议-TCP协议部分要点
上一博客记录了UDP协议的关键要点,这部分记录TCP协议的关键要点. 24.3 传输控制协议(TRANSMISSION CONTROL PROTOCOL) TCP(Transmission Contr ...
- 工具分享3:VMware 10虚拟机、MS-DOS 7.1、安装教程(MS-DOS环境安装)
VMware 10工具下载地址: 网页下载链接:http://www.xp510.com/xiazai/ossoft/desktools/22610.html MS-DOS .10镜像下载地址: 网页 ...
- mysql Workbench新建数据库连接时提示SSl not enabled的问题
在使用workbench时会弹出以下的对话框,不过这不影响使用,点击ok之后对话框关闭,接着直接点击close就行了,之后会显示已经连接上了数据库.具体ssl的方面还没研究,等研究了再贴
- hibernate_02_session介绍
什么是session? hibernate的session对象就相当于jdbc的connection.我们对数据库的操作(增删改等)都是使用的session方法. 写一个java类 package c ...
- CDC之fast->slow (2)
1 Open-loop solution One potential solution is to assert CDC signals for a period of time that excee ...
- JavaScript编程题(一)
使用Javascript脚板输出如图所示的效果页面: 使用document.write()输出水平线 使用循环控制每个水平线的长度 答案:<!doctype html> <html ...