0926mysql join的原理
转自 http://www.cnblogs.com/shengdimaya/p/7123069.html
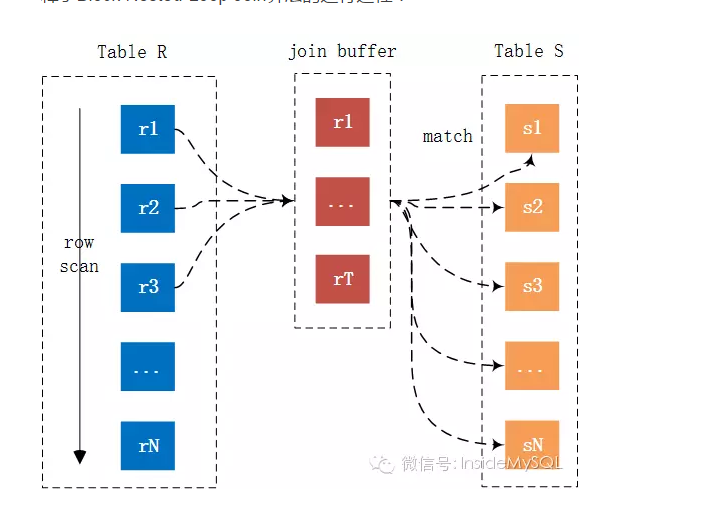
MySQL JOIN原理
先看一下实验的两张表:
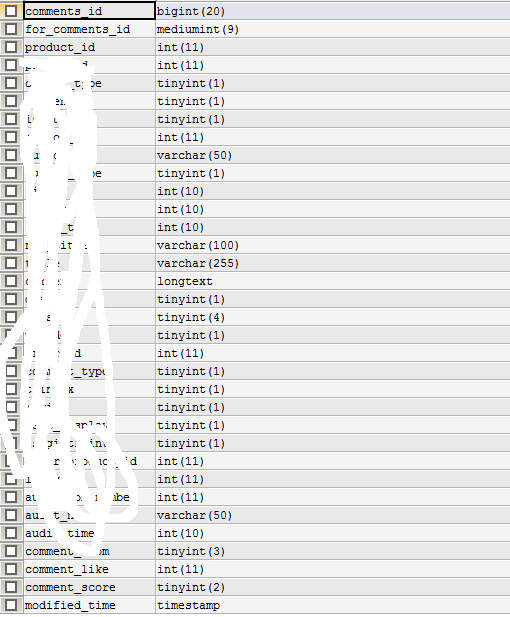
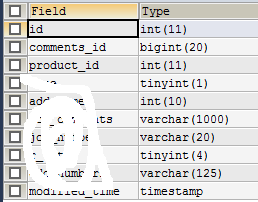
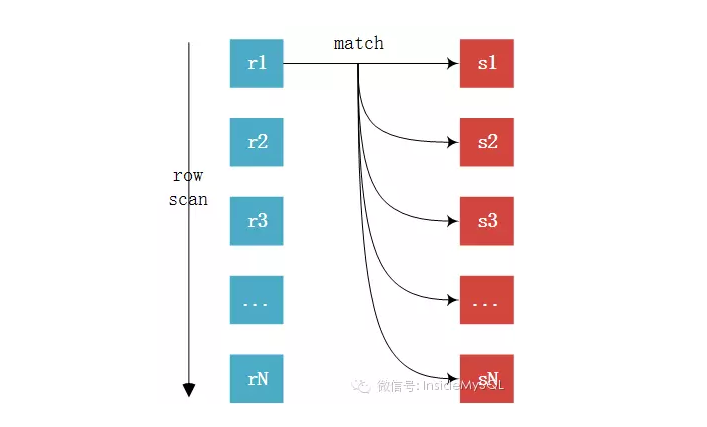
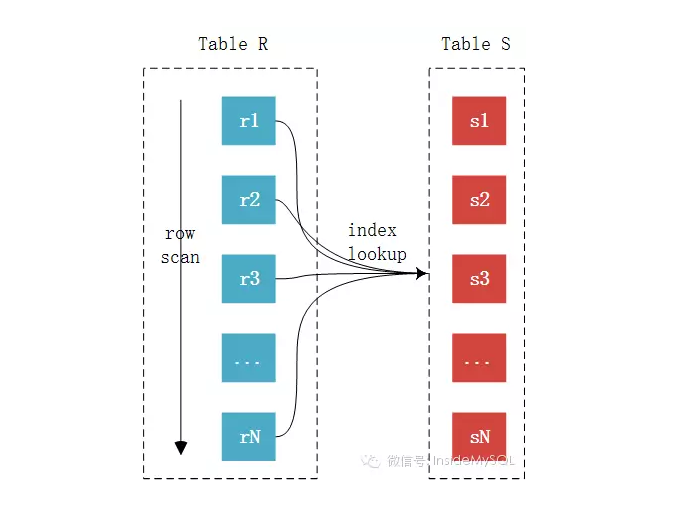
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =2056
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。0926mysql join的原理的更多相关文章
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- MySql join匹配原理
疑问 表:sl_sales_bill_head 订单抬头表 数据行:8474 表:sl_sales_bill 订单明细 数据行:8839 字段:SALES_BILL_NO 订单号 情 ...
- join方法原理
join()方法--原理同wait方法 如果不知道保护性暂停是啥的可以参考一下上一篇文章 https://www.cnblogs.com/duizhangz/p/16222854.html join方 ...
- 谈谈fork/join实现原理
害,又是一个炒冷饭的时间.fork/join是在jdk1.7中出现的一个并发工作包,其特点是可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出.从而达到多 ...
- mysql join 底层原理
你知道 Sql 中 left join 的底层原理吗? 2019-09-10阅读 7130 https://cloud.tencent.com/developer/column/2367 01.前 ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- 8.深入TiDB:解析Hash Join实现原理
本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本 我的博客地址:https://www.luozhiyun.com/archives/631 所谓 Hash Jo ...
- mysql join优化原理
http://blog.itpub.net/22664653/viewspace-1692317/ http://itindex.net/detail/46772-%E4%BC%98%E5%8C%96 ...
随机推荐
- hihocoder 1671 反转子串
时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 给定一个只包含括号和小写字母的字符串S,例如S="a(bc(de)fg)hijk". 其中括号表示将里 ...
- bzoj 1053 [ HAOI 2007 ] 反素数ant ——暴搜
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1053 试图打表找规律,但无果... 看TJ了,暴搜: 注意参数 w 是 long long. ...
- bzoj1030 文本生成器(AC自动机+dp)
1030: [JSOI2007]文本生成器 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 4777 Solved: 1986[Submit][Stat ...
- java input 实现调用手机相机和本地照片上传图片到服务器然后压缩
在微信公众号里面需要上传头像,时间比较紧,调用学习jssdk并使用 来不及 就用了input 使用input:file标签, 去调用系统默认相机,摄像,录音功能,其实是有个capture属性,直接说 ...
- POJ 3630 trie树
Phone List Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 26559 Accepted: 8000 Descripti ...
- .net中实现aspnetpager分页
第一步首先导入aspnetpager控件,然后再把他从工具箱中拖出,代码如下: <webdiyer:AspNetPager ID="aspnetpager1" runat= ...
- matplotlib之pyplot 学习示例
现在通过numpy和matplotlib.pyplot 在Python上实现科学计算和绘图,而且和matlab极为相像(效率差点,关键是方便简单) 这里有大量plots代码例子. 1. 简单的绘图( ...
- 控件中出现的e.xxxx之类的
在遇到窗体应用程序开发的时候,会在控件事件的后台写一些代码,特别是带e.xxx什么的 C#中的Graphics g = e.Graphics是什么意思? 解释是: Graphics 这个类,比较特殊, ...
- Hadoop2.6.5高可用集群搭建
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3, m4, m5这五部机, 每部主机的用户名 ...
- Deutsch lernen (06)
1. das Verzeichnis,-se 表格:名单,目录 Die Daten sind in einem Verzeichnis enthalten. (包括,含有) 2. enthalten ...