python文件的操作
文件的操作,归根结底就只有两种:打开文件、操作文件
一、打开文件:文件句柄 = open('文件路径', '模式')
python中打开文件有两种方式,即:open(...) 和 file(...),本质上前者在内部会调用后者来进行文件操作,在这里我们推荐使用open,解释
二、操作文件
操作文件包括了文件的读、写和关闭,首先来谈谈打开方式:当我们执行 文件句柄 = open('文件路径', '模式')操作的时候,要传递给open方法一个表示模式的参数:
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,先写再读。【这个方法打开文件会清空原本文件中的所有内容,将新的内容写进去,之后也可读取已经写入的内容】
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (注意:只能与 r 或 r+ 模式同使用)
- rU
- r+U
- rbU
- rb+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
以下是file操作的源码解析:
class file(object):
def close(self): # real signature unknown; restored from __doc__
关闭文件
"""close() -> None or (perhaps) an integer. Close the file.
Sets data attribute .closed to True. A closed file cannot be used for
further I/O operations. close() may be called more than once without
error. Some kinds of file objects (for example, opened by popen())
may return an exit status upon closing.
"""
def fileno(self): # real signature unknown; restored from __doc__
文件描述符
"""fileno() -> integer "file descriptor".
This is needed for lower-level file interfaces, such os.read(). """
return 0
def flush(self): # real signature unknown; restored from __doc__
刷新文件内部缓冲区
""" flush() -> None. Flush the internal I/O buffer. """
pass
def isatty(self): # real signature unknown; restored from __doc__
判断文件是否是同意tty设备
""" isatty() -> true or false. True if the file is connected to a tty device. """
return False
def next(self): # real signature unknown; restored from __doc__
获取下一行数据,不存在,则报错
""" x.next() -> the next value, or raise StopIteration """
pass
def read(self, size=None): # real signature unknown; restored from __doc__
读取指定字节数据
"""read([size]) -> read at most size bytes, returned as a string.
If the size argument is negative or omitted, read until EOF is reached.
Notice that when in non-blocking mode, less data than what was requested
may be returned, even if no size parameter was given."""
pass
def readinto(self): # real signature unknown; restored from __doc__
读取到缓冲区,不要用,将被遗弃
""" readinto() -> Undocumented. Don't use this; it may go away. """
pass
def readline(self, size=None): # real signature unknown; restored from __doc__
仅读取一行数据
"""readline([size]) -> next line from the file, as a string.
Retain newline. A non-negative size argument limits the maximum
number of bytes to return (an incomplete line may be returned then).
Return an empty string at EOF. """
pass
def readlines(self, size=None): # real signature unknown; restored from __doc__
读取所有数据,并根据换行保存值列表
"""readlines([size]) -> list of strings, each a line from the file.
Call readline() repeatedly and return a list of the lines so read.
The optional size argument, if given, is an approximate bound on the
total number of bytes in the lines returned. """
return []
def seek(self, offset, whence=None): # real signature unknown; restored from __doc__
指定文件中指针位置
"""seek(offset[, whence]) -> None. Move to new file position.
Argument offset is a byte count. Optional argument whence defaults to
0 (offset from start of file, offset should be >= 0); other values are 1
(move relative to current position, positive or negative), and 2 (move
relative to end of file, usually negative, although many platforms allow
seeking beyond the end of a file). If the file is opened in text mode,
only offsets returned by tell() are legal. Use of other offsets causes
undefined behavior.
Note that not all file objects are seekable. """
pass
def tell(self): # real signature unknown; restored from __doc__
获取当前指针位置
""" tell() -> current file position, an integer (may be a long integer). """
pass
def truncate(self, size=None): # real signature unknown; restored from __doc__
截断数据,仅保留指定之前数据
""" truncate([size]) -> None. Truncate the file to at most size bytes.
Size defaults to the current file position, as returned by tell().“""
pass
def write(self, p_str): # real signature unknown; restored from __doc__
写内容
"""write(str) -> None. Write string str to file.
Note that due to buffering, flush() or close() may be needed before
the file on disk reflects the data written."""
pass
def writelines(self, sequence_of_strings): # real signature unknown; restored from __doc__
将一个字符串列表写入文件
"""writelines(sequence_of_strings) -> None. Write the strings to the file.
Note that newlines are not added. The sequence can be any iterable object
producing strings. This is equivalent to calling write() for each string. """
pass
def xreadlines(self): # real signature unknown; restored from __doc__
可用于逐行读取文件,非全部
"""xreadlines() -> returns self.
For backward compatibility. File objects now include the performance
optimizations previously implemented in the xreadlines module. """
pass
file Code
针对上面源码中的个方法,可以具体看一下在实际操作中的用例:
obj1 = open('filetest.txt','w+')
obj1.write('I heard the echo, from the valleys and the heart\n')
obj1.writelines(['Open to the lonely soul of sickle harvesting\n',
'Repeat outrightly, but also repeat the well-being of\n',
'Eventually swaying in the desert oasis'])
obj1.seek(0)
print obj1.readline()
print obj1.tell()
print obj1.readlines()
obj1.close()
我们以‘w+’的打开方式为例,write是向文件中写入一个字符串,而writelines是想文件中写入一个字符串数组。seek(0)方法是将指针指向其实位置,因为在写的过程中,指针的标记是随着写入的内容不断后移的,seek方法可以将指针移动到指定位置,而这个时候就指向0位置,从这个位置开始读,就可以读到刚刚写入的所有内容了;readline()是从指针位置读取一行,所以在这里,执行readline会将刚刚写入文件中的第一行读取出来;tell是指出指针当前的位置,这个时候执行tell()方法,指针指向了第二行的起始位置;之后的readlines方法,则会将文件当前指针之后的剩余内容按行读入数组中。下图是程序执行后文件和控制台的结果:
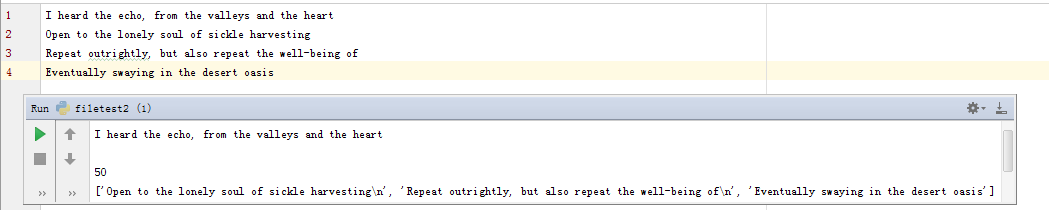
尽管刚刚使用'w+'的方式打开文件,但是事实上这种打开方式在文件处理中并不常用,曾一度被我们老师评为‘无意义’,因为用‘w+’方法会清空原文件里所有的东西~
上面一口气介绍了那么多方法,让我们有了一个笼统的概念,接下来把这些方法们各功能拿出来对比下:
写文件操作
write,writelines,相比于那些五花八门的读方法,写方法就单纯的多了,只有wite和writelines两种。看下面的例子和写入的结果,其实write方法和writelines方法都差不多,只不过一个接受的参数是list格式,一个接受的参数是字符串格式而已。这里使用的时候要注意换行符。
obj1 = open('E:\PythonL\\11-8\\filetest.txt','r')
obj1 = open('filetest.txt','w+')
obj1.write('I heard the echo, from the valleys and the heart\nOpen to the lonely soul of sickle harvesting\n')
obj1.writelines([
'Repeat outrightly, but also repeat the well-being of\n',
'Eventually swaying in the desert oasis'
])
刚刚我们使用write和writelines方法向文件里写入了泰戈尔的一段小诗,结果如下:
I heard the echo, from the valleys and the heart
Open to the lonely soul of sickle harvesting
Repeat outrightly, but also repeat the well-being of
Eventually swaying in the desert oasis
读文件操作
我们以上面这个文件为例,来说说读文件:
首先来看一下直接读取文件中所有内容的方法read和readlines,从下面的结果来看就知道这两种方法一个返回列表,一个是返回字符串,和上面的write方法相对应:
1 #readline方法
2 obj1 = open('E:\PythonL\\11-8\\filetest.txt','r')
3 print 'readlines:',obj1.readlines()5 #readline方法
6 print "read:",obj1.read()
1 readlines: ['I heard the echo, from the valleys and the heart\n', 'Open to the lonely soul of sickle harvesting\n', 'Repeat outrightly, but also repeat the well-being of\n', 'Eventually swaying in the desert oasis']
1 read: I heard the echo, from the valleys and the heart
2 Open to the lonely soul of sickle harvesting
3 Repeat outrightly, but also repeat the well-being of
4 Eventually swaying in the desert oasis
readlines和read方法虽然简便好用,但是如果这个文件很庞大,那么一次性读入内存就降低了程序的性能,这个时候我们就需要一行一行的读取文件来降低内存的使用率了。
readline,next,xreadlines:用来按行读取文件,其中需要仔细看xreadlines的用法,因为xreadlines返回的是一个迭代器,并不会直接返回某一行的内容
需要注意的是,尽管我把这一大坨代码放在一起展示,但是要是真的把这一大堆东西放在一起执行,就会报错(ValueError: Mixing iteration and read methods would lose data),具体的原因下面会进行解释。
obj1 = open('E:\PythonL\\11-8\\filetest.txt','r')
#readline方法
print "readline:",obj1.readline()
#readline方法
print "next:",obj1.next()
#readline方法
r = obj1.xreadlines()
print 'xreadlines:',r.next()
#readline方法
print 'readlines:',obj1.readlines()
#readline方法
print "read:",obj1.read()
先展示一下执行上面这些程序的结果好了:
左侧是代码,右侧是相应的执行结果。这里先展示readline,next,xreadlines这三个方法。
readline: I heard the echo, from the valleys and the heart next: Open to the lonely soul of sickle harvesting xreadlines: Repeat outrightly, but also repeat the well-being of
这里要补充一点,xreadlines方法在python3.0以后就被弃用了,它被for语句直接遍历渐渐取代了:
obj1 = open('filetest.txt','r')
for line in obj1:
print line
运行结果:
I heard the echo, from the valleys and the heart
Open to the lonely soul of sickle harvesting
Repeat outrightly, but also repeat the well-being of
Eventually swaying in the desert oasis
文件中的指针
看完了文件的读写,文件的基本操作我们就解决了,下面介绍文件处理中和指针相关的一些方法: seek,tell,truncate
obj1 = open('filetest.txt','w+')
obj1.write('I heard the echo, from the valleys and the heart\n'
'Open to the lonely soul of sickle harvesting\n')
print '1.tell:',obj1.tell()
obj1.writelines([
'Repeat outrightly, but also repeat the well-being of\n',
'Eventually swaying in the desert oasis'
])
print '2.tell:',obj1.tell()
首先看tell,tell的作用是指出当前指针所在的位置。无论对文件的读或者写,都是依赖于指针的位置,我们从指针的位置开始读,也从指针的位置开始写。我们还是写入之前的内容,在中间打印一下tell的结果。执行代码后结果如下:
1.tell: 96
2.tell: 188
接下来再看一下seek的使用:
1 obj1 = open('E:\PythonL\\11-8\\filetest.txt','r')
2 print "next:",obj1.next(),'tell1:',obj1.tell(),'\n'
3 obj1.seek(50)
4 print "read:",obj1.read(),'tell2:',obj1.tell(),'\n'
next: I heard the echo, from the valleys and the heart
tell1: 188 read: Open to the lonely soul of sickle harvesting
Repeat outrightly, but also repeat the well-being of
Eventually swaying in the desert oasis tell2: 188
从显示的执行结果来看这个问题,我们在使用next读取文件的时候,使用了tell方法,这个时候返回的是188,指针已经指向了tell的结尾(具体原因在下面解释),那么我们执行read方法,就读不到内容了,这个时候我们使用seek方法将指针指向50这个位置,再使用中read方法,就可以把剩下的内容读取出来。
在看一个关于truncate的例子:
obj1 = open('filetest.txt','r+')
obj1.write('this is a truncate test,***')
obj1.seek(0)
print 'first read:\n',obj1.read()
obj1.seek(0)
obj1.write('this is a truncate test')
obj1.truncate()
obj1.seek(0)
print '\nsecond read:\n',obj1.read()
first read:
this is a truncate test,***valleys and the heart
Open to the lonely soul of sickle harvesting
Repeat outrightly, but also repeat the well-being of
Eventually swaying in the desert oasis second read
this is a truncate test truncate result
有上面的打印结果我们可以知道,在文件进行写操作的时候,会根据指针的位置直接覆盖相应的内容,但是很多时候我们修改完文件之后,后面的东西就不想保留了,这个时候我们使用truncate方法,文件就仅保存当前指针位置之前的内容。我们同样可以使用truncate(n)来保存n之前的内容,n表示指针位置。
with操作文件
为了避免打开文件后忘记关闭,可以通过管理上下文,即:with open('文件路径','操作方式') as 文件句柄:
#使用whith打开可以不用close
with open('E:\PythonL\\filetest.txt','r') as file_obj:
file_obj.write('') #在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,下例为同时打开两个文件
#with open('E:\PythonL\\filetest1.txt','r') as file_obj1,open('E:\PythonL\\filetest2.txt','w') as file_obj2:'''
容易犯的错误:
ValueError: Mixing iteration and read methods would lose data
我在操作文件的过程中遇到过这样一个问题,从字面上来看是说指针错误,那么这种问题是怎么产生的呢?我发现在使用next或者xreadlines方法之后再使用read或readlines方法就会出现这种错误,原因是next或者xreadlines包括我们平时常用的for循环读取文件的方式,程序都是在自己内部维护了一个指针(这也解释了我们使用这些方法的时候再用tell方法拿到的指针都是指向了的文件末尾,而不是当前独到的位置),所以如果我们要先使用上述的next或者xreadlines方法读取一行,然后再用read或readlines方法将剩余的内容读到就会报错。
解决方案:
这个时候有两种解决方案:
第一种,在读取一行后,用seek指定指针的位置,就可以继续使用其他方法了
第二种,使用readline方法,这个方法没有内部维护的指针,它就是辣么单纯的一行一行傻傻的读,指针也就傻傻的一行一行往下移动。这个时候你也可以使用tell方法追踪到指针的正确位置,也可以使用seek方法定位到想定位的地方,配合truncate,wirte等方法,简直不能更好用一些。
python文件的操作的更多相关文章
- python文件相关操作
Python文件相关操作 打开文件 打开文件,采用open方法,会将文件的句柄返回,如下: f = open('test_file.txt','r',encoding='utf-8') 在上面的代码中 ...
- Python文件基础操作(IO入门1)
转载请标明出处: http://www.cnblogs.com/why168888/p/6422270.html 本文出自:[Edwin博客园] Python文件基础操作(IO入门1) 1. pyth ...
- python文件高级操作
python文件高级操作和注意事项等等 文件过大保护 由于read是一次性读取文件所有的内容,如果文件100G,内存就会吃不消,所以推荐使用read(size)一次读取指定字节/字符(根据rb,或者r ...
- python 文件读写操作(24)
以前的代码都是直接将数据输出到控制台,实际上我们也可以通过读/写文件的方式读取/输出到磁盘文件中,文件读写简称I/O操作.文件I/O操作一共分为四部分:打开(open)/读取(read)/写入(wri ...
- Python 文件常见操作
# -*-coding:utf8 -*- ''''' Python常见文件操作示例 os.path 模块中的路径名访问函数 分隔 basename() 去掉目录路径, 返回文件名 dirname() ...
- python 文件 IO 操作
Python 的底层操作 * 其实Python的文件IO操作方法,和Linux底层的差不多 打开 f = open(filename , "r") 后面的 "r" ...
- ~~Python文件简单操作~~
进击のpython Python文件操作 在说Python的文件操作之前 我们可以先思考一个问题 平时我们是怎么对电脑中的文件进行操作的呢? 打开电脑⇨找到文件⇨打开文件⇨读文件⇨修改文件⇨保存文件⇨ ...
- Python 文件读写操作实例详解
Python提供了必要的函数和方法进行默认情况下的文件基本操作.你可以用file对象做大部分的文件操作 一.python中对文件.文件夹操作时经常用到的os模块和shutil模块常用方法.1.得到当前 ...
- 12、python文件的操作
前言:本文主要介绍python中文件的操作,包括打开文件.读取文件.写入文件.关闭文件以及上下文管理器. 一.打开文件 Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处 ...
随机推荐
- C#读写config配置文件--读取配置文件类
一:通过Key访问Value的方法: //判断App.config配置文件中是否有Key(非null) if (ConfigurationManager.AppSettings.HasKeys()) ...
- 请允许我成为你的夏季——shiro、jdbcInsertall
这两天总是觉得自己被关进了一个大笼子,日子拮据.生活不就是这样吗,一边觉得自己很差劲,一边又想成为一个更好的自己.可那又有什么办法呢,万物皆有裂痕,但那又怎样,那是光照进来的地方啊. 开始学习shir ...
- secureCRT 小技巧
破解: keygen.exe 放到安装目录下填好姓名公司 ,patch后generate就行了 连接问题: 连接出现socket error很有可能是你的防火墙没关,今天排查了很久才发现是这个问题,浪 ...
- 变量对象、作用域链和This
变量对象 作用域链 This 整理自:https://www.cnblogs.com/TomXu/archive/2011/12/15/2288411.html 系列文章中变量对象,作用域链和this ...
- Js 中的i++ 和 ++i 的区别
首先碰见 i++ 和 ++i 会一脸蒙蔽 感觉没什么区别,都是相加 , 但是 输出的值是不同!!! 来奉上代码来进行比较 var i = 1; var a = i++; //a = 1; 此时i ...
- 计算机科学书籍推荐和CSS、js书籍推荐
计算机科学:<深入理解计算机系统>,这是基础知识 JavaScript:JavaScript高级程序设计:大名鼎鼎的红宝书 <精通CSS:高级Web标准解决方案>:因为我觉CS ...
- 如何更新 CentOS 镜像源
话不多说, 直接上教程. 首先备份/etc/yum.repos.d/CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.rep ...
- 使用Xcode的Targets来管理开发和生产版本的构建
如何创建一个新的Target 如何在Xcode中创建一个开发的target?我使用示例项目“todo”引导您一步一步完成整个过程..您也可以使用自己的项目并按照步骤: 1. 在项目的导航面板进入项目设 ...
- CSUOJ 1603 Scheduling the final examination
1603: Scheduling the final examination Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 49 Solved: 1 ...
- [Python] Read and Parse Files in Python
This lesson will teach you how to read the contents of an external file from Python. You will also l ...