mysql字符设置乱码问题
在操作系统中对于任意一个字符而言是没有编码格式概念的;同样的字母在不同的编码集里面可能代表不同的东西;关键在于你用什么样的软件打开它,软件本身是以什么样的编码格式来显示你的字符,那么你的字符当前就是什么编码;就看你用什么编码集来查看你的字符了;
在程序开发中,编码最终的呈现与系统编码,项目编码(如你的项目是以什么编码格式编译以及启动的),文件编码都有关系;比如你在编辑器中你用GBK的编码编写的Java文件,在打包的时候JDK以UTF-8形式编码就会出错,所以这个时候保持编码一致就很重要了,类似比如你在idea中编译或在maven下编译都是如此;
字符串在计算机中都是以字节形式表现的,如果不指定编码是无法看到正确的字符串的;先来了解一下常见的编码:
1.iso8858-1:
属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母a的编码为0x61=97。
很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用 iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然"中文"两个字不存在iso8859-1编码,以gb2312编码为例,应该是"d6d0 cec4"两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:"d6 d0 ce c4"(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节"e4 b8 ad e6 96 87"。很明显,这种表示方法还需要以另一种编码为基础。
2.gb2312/gbk:
这就是汉子的国标码,专门用来表示汉字,是双字节编码,而英文字母和iso8859-1一致(兼容iso8859-1编码)。其中gbk编码能够用来同时表示繁体字和简体字,而 gb2312只能表示简体字,gbk是兼容gb2312编码的。
3.unicode:
这是最统一的编码,可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母a为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用 unicode编码来处理的,比如java。
4.UTF8
虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字使用三个字节。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包含了很多的英文字符。
utf8与utf-8:在数据库(mysql)中只能用utf8不能用utf-8;而在http请求中content-Type的charset是用UTF-8; 如text/html;charset=UTF-8其中后面的charset保证了text/html是utf-8格式的。
编码之间转换问题,
val str = "中国" val v4 = new String(v3.getBytes("GBK"), "GBK")
println(v4) 如果你的编码是gbk的中文,你在去转换utf-8你看到的都是乱码,一般都是采用先转换成gbk,然后在转换utf-8才能正确查看编码: val v5 = new String(v2.getBytes("UTF-8"), "UTF-8")
println(v5) 所以如果你本身是什么样的编码,就要转成相应的编码,在去转成其他你想要的编码才能成功 |
mysql读取字符乱码问题
一般如果我们保证mysql编码格式,http编码格式,页面编码格式一致的话编码可以正确显示成功:
例:jdbc:mysql://localhost/DBVF?useUnicode=true&characterEncoding=utf8 如果你数据库的编码是gbk,访问的时候会自动转换成utf8;如果是utf8就不需要?后面参数了
show variables like '%charecter%' 可以查看数据的库的编码
show variables like 'collation_%'
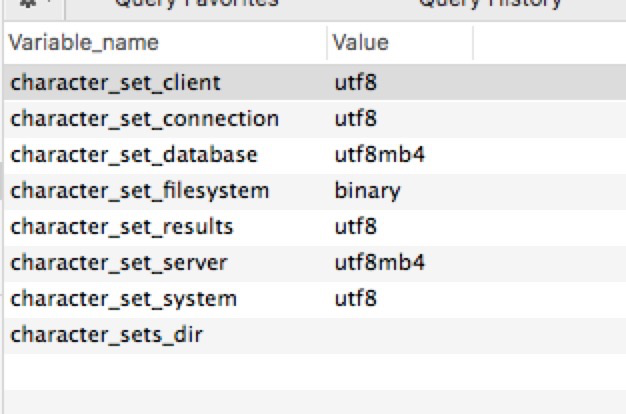
character_set_results表示返回的数据是以utf8形式返回的;当然在java读取数据库之前:
执行set character set 'utf8'或者写入执行set character set 'utf8' 都可以保证编码正确
参考:mysql编码格式介绍 http://www.2cto.com/database/201412/363509.html
mysql编码转换过程http://cenalulu.github.io/mysql/mysql-mojibake/
统一分析:
1.linux环境上编码问题
如果是centeros可以先安装中文包 yum groupinstall "Chinese Support"
编辑/etc/sysconfig/i18n,修改内容如下:
LANG="zh_CN.UTF-8"
SUPPORTED="zh_CN.UTF-8:zh_CN:zh:en_US.UTF-8:en_US:en"
SYSFONT="latarcyrheb-sun16"
编辑/etc/profile,加入: etc/profile为全局环境变量
export LC_ALL=zh_CN.UTF-8
2.JVM设置:
JVM的缺省编码方式由系统的“本地语言环境Locale”设置确定。JVM的file.encoding属性,这个属性确定了JVM的缺省的编码/解码方式:从而影响应用中所有字节流==>字符流的解码方式 ,字符流==>字节流的编码方式。JVM会根据操作系统的Locale设置自动调整语言环境。基本不用设置。
3.web容器:
一般的web容器默认编码格式都是以iso8859-1
tomcat:
为了使Tomcat支持中文文件名并且让Tomcat能够自己处理Get方式传递过来的参数,那么我们已经在Tomcat安装目录下的conf/server.xml里头修改如下:
<Connectorport="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"/>
注意一种特殊情况,如果在程序中调用response.sendRedirect()方法重定向到中文文件名的页面,需要以如下方式调用:
response.sendRedirect(java.NET.URLEncoder.encode(“中文.html”,”UTF-8”))
也就是在使用重定向语句的时候,需要用java.Net.URLEncoder的静态方法 encoder() 按照指定的编码手动转码。
4.html页面:需要指定一致的编码格式如jsp:
关于JSP页面中的pageEncoding和contentType两种属性的区别:
pageEncoding是jsp文件本身的编码
contentType的charset是指服务器发送给客户端时的内容编码
JSP要经过两次的“编码”,第一阶段会用pageEncoding,第二阶段会用utf-8至utf-8,第三阶段就是由Tomcat出来的网页, 用的是contentType。
第一阶段是jsp编译成.java,它会根据pageEncoding的设定读取jsp,结果是由指定的编码方案翻译成统一的UTF-8 JAVA源码(即.java),如果pageEncoding设定错了,或没有设定,出来的就是中文乱码。
第二阶段是由JAVAC的JAVA源码至JavabyteCode的编译,不论JSP编写时候用的是什么编码方案,经过这个阶段的结果全部是UTF-8的encoding的java源码。
JAVAC用UTF-8的encoding读取java源码,编译成UTF-8 encoding的二进制码(即.class),这是JVM对常数字串在二进制码(java encoding)内表达的规范。
第三阶段是Tomcat(或其的application Container)载入和执行阶段二的来的JAVA二进制码,输出的结果,也就是在客户端见到的,这时隐藏在阶段一和阶段二的参数contentType就发挥了功效。
对于每个JSP页面,为了让它使用Utf-8的编码去返回给浏览器,那么加入下面一行在页面开始是必不可少的:
<%@page contentType="text/html;charset=utf-8"%>
5.http设置:
request.setCharacterEncoding("utf-8")。
HTTP header 里面,Content-Type 这一条目的写法就是 "text/html; charset=utf-8"
这一串信息描述的是内容的格式:
设计的角度来讲
因为“text/html; charset=utf-8” 这一串信息所描述的就是一个属性:内容的格式(即Content-Type)。
XML的设计,并不是为了数据存储与查询,而是为了规范、合理、统一地描述数据。所以XML的属性设计与数据库表的字段设计并不一样。从数据库表设计的角度,把text/html; charset=utf-8拆成两个甚至三个字段都是合理的。但是对于XML而言并不是这样。这三个属性的作用很明确而且无歧义:保证数据接受者能正确解析其内容。单独拿出来任何一个属性都做不到这一点。那么对于XML而言,它们就应该被放在一起。
从标准与历史的角度来讲
另外,第一版的HTML标准,出现在1993年:http://www.w3.org/MarkUp/draft-ietf-iiir-html-01.txt
Content-Type这个东西的出现,却可以追溯到1988年:http://tools.ietf.org/html/rfc1049
http协议参考:
http://kb.cnblogs.com/page/130970/
mysql字符设置乱码问题的更多相关文章
- mysql字符设置
MySQL字符集设置 mysql>CREATE DATABASE IF NOT EXISTS mydb default charset utf8 COLLATE utf8_general_ci; ...
- MySQL字符集设置及字符转换(latin1转utf8)
MySQL字符集设置及字符转换(latin1转utf8) http://blog.chinaunix.net/uid-25266990-id-3344584.html MySQL字符集设置及字符转换 ...
- 微信nickname乱码及mysql编码格式设置(utf8mb4)
微信nickname乱码及mysql编码格式设置(utf8mb4) 今天在写微信公众平台项目时,写到一个用户管理模块,接口神马的已经调试好了,于是将用户从微信服务器保存到本地数据库,发现报错: jav ...
- mysql字符乱码
解决mysql字符乱码思路: mysql服务器字符集 mysql客户端字符集 系统字符集 生产环境改字符集: 1.导出表结构到 scam.sql文件中 2.更改scam.sql文件中的字符集为想要的字 ...
- MySQL字符集设置—MySQL数据库乱码问题
MySQL(4.1以后版本) 服务器中有六个关键位置使用了字符集的概念,他们是:client .connection.database.results.server .system.MySQL有两个字 ...
- c/c++连接mysql数据库设置及乱码问题(vs2013连接mysql数据库,使用Mysql API操作数据库)
我的安装环境: (1)vs2013(32位版) (vs2013只有32位的 没有64位的,但是它可以编译出64位的程序) : (2)mysql-5.7.15(64位) vs2013中的设置(按步骤来 ...
- Mysql字符集设置
转 基本概念 • 字符(Character)是指人类语言中最小的表义符号.例如’A'.’B'等:• 给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encodi ...
- mysql数据库 中文乱码
看到一篇很好的文章,转录于此 中文乱码似乎是程序编写中永恒的一个话题和难点,就比如MySQL存取中文乱码,但我想做任何事情,都要有个思路才行,有了思路才知道如何去解决问题,否则,即使一时解决了问题,但 ...
- 修改数据库mysql字符编码为UTF8
Mysql数据库是一个开源的数据库,应用非常广泛.以下是修改mysql数据库的字符编码的操作过程. 步骤1:查看当前的字符编码方法 mysql> show variables like'char ...
随机推荐
- Java中将String转json对象
import org.json.simple.JSONObject; import org.json.simple.parser.JSONParser; import org.json.simple. ...
- [转] -- html5手机网站自适应需要加的meta标签
webapp开发初期,会碰到在pc端开发好的页面在移动端显示过大的问题,这里需要在html head中加入meta标签来控制缩放 <meta name=" viewport" ...
- 洛谷3961 [TJOI2013]黄金矿工
题目描述 小A最近迷上了在上课时玩<黄金矿工>这款游戏.为了避免被老师发现,他必须小心翼翼,因此他总是输.在输掉自己所有的金币后,他向你求助.每个黄金可以看做一个点(没有体积).现在给出你 ...
- 洛谷P1280 && caioj 1085 动态规划入门(非常规DP9:尼克的任务)
这道题我一直按照往常的思路想 f[i]为前i个任务的最大空暇时间 然后想不出来怎么做-- 后来看了题解 发现这里设的状态是时间,不是任务 自己思维还是太局限了,题做得太少. 很多网上题解都反着做,那么 ...
- 紫书 习题 10-6 UVa 1210(前缀和)
素数筛然后前缀和 看代码 #include<cstdio> #include<vector> #include<cstring> #include<map&g ...
- [洛谷P3121] 审查(黄金) (AC自动机)
题目描述 FJ把杂志上所有的文章摘抄了下来并把它变成了一个长度不超过10^5的字符串S.他有一个包含n个单词的列表,列表里的n个单词记为t_1...t_N.他希望从S中删除这些单词. FJ每次在S中找 ...
- 【Henu ACM Round#16 F】Om Nom and Necklace
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] KMP算法可以把"i前缀"pre[i] 分成ssssst的形式 这里t是s的前缀. 然后s其实就是pre[i]中 ...
- 【转】[译]理解HTTP/304响应
[转][译]理解HTTP/304响应 原文:http://www.telerik.com/automated-testing-tools/blog/eric-lawrence/12-11-06/und ...
- centos同步网络北京时间
sudo yum -y install ntpdate ntp sudo ntpdate time.windows.com sudo hwclock -w
- 【 D3.js 入门系列 --- 2.1 】 关于怎样选择,插入,删除元素
本人的个人博客首页为: http://www.ourd3js.com/ ,csdn博客首页为:http://blog.csdn.net/lzhlzz/. 转载请注明出处,谢谢. 在D3.js中,选择 ...