cluster discovery概述及FaultDetection分析
elasticsearch cluster实现了自己发现机制zen。Discovery功能主要包括以下几部分内容:master选举,master错误探测,集群中其它节点探测,单播多播ping。本篇会首先概述以下Discovery这一部分的功能,然后介绍节点检测。其它内容会在接下来介绍。
discovery是可配式模块,官方支持亚马逊的Azure discovery,Google Compute Engine,EC2 Discovery三种发现机制,根据插件规则完全可以自己实现其它的发现机制。整个模块通过实现guice的DiscoveryModule对外提供模块的注册和启动, 默认使用zen discovery。发现模块对外接口为DiscoveryService,它的方法如下所示:
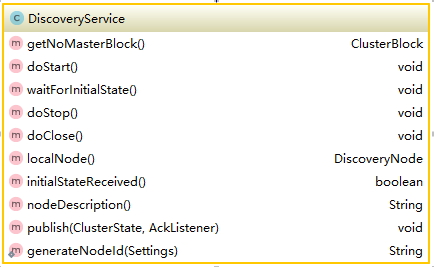
它本质上是discovery的一个代理,所有的功能最终都是由所绑定的discovery所实现的。节点启动时通过DiscoveryModule获取DiscoveryService,然后启动DiscoveryService,DiscoveryService启动绑定的Discovery,整个功能模块就完成了加载和启动。这也是elasticsearch所有模块的实现方式,通过module对外提供绑定和获取,通过service接口对外提供模块的功能,在后面的分析中会经常遇到。
以上就Discovery模块的概述。接下来分析cluster的一个重要功能就是节点探测。cluster中不能没有master节点,因此集群中所有节点都要周期探测master节点,一旦无法检测到,将会进行master选举。同时作为master,对于节点变动也要时刻关注,因此它需要周期性探测集群中所有节点,确保及时剔除已经宕机的节点。这种相互间的心跳检测就是cluster的faultdetection。下图是faultdetection的继承关系:
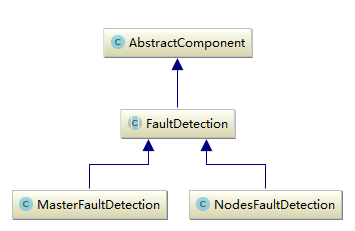
有两种实现方式,分别是master探测集群中其它节点和其它节点对master节点的探测。FaultDetection只要一个抽象方法handleTransportDisconnect,该方法在内部类FDConnectionListener中被调用。在elasticsearch中大量使用了listener的异步方式,异步可以极大提升系统性能。它的代码如下所示:
private class FDConnectionListener implements TransportConnectionListener {
@Override
public void onNodeConnected(DiscoveryNode node) {
}
@Override
public void onNodeDisconnected(DiscoveryNode node) {
handleTransportDisconnect(node);
}
}
faultdetection启动时会注册相应的FDConnetionListener,当探测到节点丢失,会通过onNodeDisconnected方法回调对于的handleTransportDisconnect进行处理。首先看一下MasterFaultDetection的启动代码:private void innerStart(final DiscoveryNode masterNode) {
this.masterNode = masterNode;
this.retryCount = 0;
this.notifiedMasterFailure.set(false); // 尝试连接master节点
try {
transportService.connectToNode(masterNode);
} catch (final Exception e) {
// 连接失败通知masterNode失败
notifyMasterFailure(masterNode, "failed to perform initial connect [" + e.getMessage() + "]");
return;
}
//关闭之前的masterping,重启新的masterping
if (masterPinger != null) {
masterPinger.stop();
}
this.masterPinger = new MasterPinger(); // 周期之后启动masterPing,这里并没有周期启动masterPing,只是设定了延迟时间。
threadPool.schedule(pingInterval, ThreadPool.Names.SAME, masterPinger);
}
代码有有详细注释,就不再过多解释。接下来看一下master连接失败的逻辑,代码如下:
private void notifyMasterFailure(final DiscoveryNode masterNode, final String reason) {
if (notifiedMasterFailure.compareAndSet(false, true)) {
threadPool.generic().execute(new Runnable() {
@Override
public void run() {
//通知所有listener master丢失
for (Listener listener : listeners) {
listener.onMasterFailure(masterNode, reason);
}
}
});
stop("master failure, " + reason);
}
}
在ZenDiscovery中实现了listener.onMasterFailure接口。会进行master丢失的相关处理,在后面再分析。以下MasterPing的相关代码(有删节):
private class MasterPinger implements Runnable {
private volatile boolean running = true;
public void stop() {
this.running = false;
}
@Override
public void run() {
if (!running) {
// return and don't spawn...
return;
}
final DiscoveryNode masterToPing = masterNode;
final MasterPingRequest request = new MasterPingRequest(clusterService.localNode().id(), masterToPing.id(), clusterName);
final TransportRequestOptions options = options().withType(TransportRequestOptions.Type.PING).withTimeout(pingRetryTimeout);
transportService.sendRequest(masterToPing, MASTER_PING_ACTION_NAME, request, options, new BaseTransportResponseHandler<MasterPingResponseResponse>() {
@Override
public MasterPingResponseResponse newInstance() {
return new MasterPingResponseResponse();
}
@Override
public void handleResponse(MasterPingResponseResponse response) {
if (!running) {
return;
}
// reset the counter, we got a good result
MasterFaultDetection.this.retryCount = 0;
// check if the master node did not get switched on us..., if it did, we simply return with no reschedule
if (masterToPing.equals(MasterFaultDetection.this.masterNode())) {
// 启动新的ping周期
threadPool.schedule(pingInterval, ThreadPool.Names.SAME, MasterPinger.this);
}
}
@Override
public void handleException(TransportException exp) {
if (!running) {
return;
}
synchronized (masterNodeMutex) {
// check if the master node did not get switched on us...
if (masterToPing.equals(MasterFaultDetection.this.masterNode())) {
if (exp instanceof ConnectTransportException || exp.getCause() instanceof ConnectTransportException) {
handleTransportDisconnect(masterToPing);
return;
} else if (exp.getCause() instanceof NoLongerMasterException) {
logger.debug("[master] pinging a master {} that is no longer a master", masterNode);
notifyMasterFailure(masterToPing, "no longer master");
return;
} else if (exp.getCause() instanceof NotMasterException) {
logger.debug("[master] pinging a master {} that is not the master", masterNode);
notifyMasterFailure(masterToPing, "not master");
return;
} else if (exp.getCause() instanceof NodeDoesNotExistOnMasterException) {
logger.debug("[master] pinging a master {} but we do not exists on it, act as if its master failure", masterNode);
notifyMasterFailure(masterToPing, "do not exists on master, act as master failure");
return;
}
int retryCount = ++MasterFaultDetection.this.retryCount;
logger.trace("[master] failed to ping [{}], retry [{}] out of [{}]", exp, masterNode, retryCount, pingRetryCount);
if (retryCount >= pingRetryCount) {
logger.debug("[master] failed to ping [{}], tried [{}] times, each with maximum [{}] timeout", masterNode, pingRetryCount, pingRetryTimeout);
// not good, failure
notifyMasterFailure(masterToPing, "failed to ping, tried [" + pingRetryCount + "] times, each with maximum [" + pingRetryTimeout + "] timeout");
} else {
// resend the request, not reschedule, rely on send timeout
transportService.sendRequest(masterToPing, MASTER_PING_ACTION_NAME, request, options, this);
}
}
}
}
);
}
}
MasterPing是一个线程,在innerStart的方法中没有设定周期启动masterping,但是masterping需要周期进行,这个秘密就在run 方法中,如果ping成功就会重启一个新的ping。这样既保证了ping线程的唯一性同时也保证了ping的顺序和间隔。ping的方式跟之前一样是也是通过transport发送一个masterpingrequest,进行一个连接。节点收到该请求后,如果已不再是master会抛出NotMasterException,状态更新出差会抛出其它异常,异常会通过。否则会正常响应notifyMasterFailure方法处理跟启动逻辑一样。对于网络问题导致的无响应情况,会调用handleTransportDisconnect(masterToPing)方法处理。masterfaultDetection对该方法的实现如下:
protected void handleTransportDisconnect(DiscoveryNode node) {
//这里需要同步
synchronized (masterNodeMutex) {
//master 已经换成其它节点,就没必要再连接
if (!node.equals(this.masterNode)) {
return;
}
if (connectOnNetworkDisconnect) {
try {
//尝试再次连接
transportService.connectToNode(node);
// if all is well, make sure we restart the pinger
if (masterPinger != null) {
masterPinger.stop();
}
//连接成功启动新的masterping
this.masterPinger = new MasterPinger();
// we use schedule with a 0 time value to run the pinger on the pool as it will run on later
threadPool.schedule(TimeValue.timeValueMillis(0), ThreadPool.Names.SAME, masterPinger);
} catch (Exception e) {
//连接出现异常,启动master节点丢失通知
logger.trace("[master] [{}] transport disconnected (with verified connect)", masterNode);
notifyMasterFailure(masterNode, "transport disconnected (with verified connect)");
}
} else {
//不需要重连,通知master丢失。
logger.trace("[master] [{}] transport disconnected", node);
notifyMasterFailure(node, "transport disconnected");
}
}
}
这就是masterfaultDetection的整个流程:启动中如果master丢失则通知节点丢失,否则在一定延迟(3s)后启动masterping,masterping线程尝试连接master节点,如果master节点网络失联,尝试再次连接。master节点收到masterpingrequest后首先看一下自己还是不是master,如果不是则抛出异常,否则正常回应。节点如果收到响应是异常则启动master丢失通知,否则此次ping结束。在一定延迟后启动新的masterping线程。
NodeFaultDetection的逻辑跟实现上跟MasterFualtDetetion相似,区别主要在于ping异常处理上。当某个节点出现异常或者没有响应时,会启动节点丢失机制,只是受到通知后的处理逻辑不通。就不再详细分析,有兴趣可以参考具体代码。
cluster discovery概述及FaultDetection分析的更多相关文章
- JPEG概述和头分析(C源码)
原创文章,转载请注明:JPEG概述和头分析(C源码) By Lucio.Yang 部分内容来自:w285868925,JPEG压缩标准 1.JPEG概述 JPEG是一个压缩标准,又可分为标准 JPE ...
- MySQL Cluster配置概述
一. MySQL Cluster概述 MySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的 Cluster .通过无共享体系结构,系统能够使用廉价的硬件,而 ...
- x264源代码学习1:概述与架构分析
函数背景色 函数在图中以方框的形式表现出来.不同的背景色标志了该函数不同的作用: 白色背景的函数:不加区分的普通内部函数. 浅红背景的函数:libx264类库的接口函数(API). 粉红色背景函数:滤 ...
- Redis 单机模式,主从模式,哨兵模式(sentinel),集群模式(cluster),第三方模式优缺点分析
Redis 的几种常见使用方式包括: 单机模式 主从模式 哨兵模式(sentinel) 集群模式(cluster) 第三方模式 单机模式 Redis 单副本,采用单个 Redis 节点部署架构,没有备 ...
- AMR音频编码器概述及文件格式分析
全称Adaptive Multi-Rate,自适应多速率编码,主要用于移动设备的音频,压缩比比较大,但相对其他的压缩格式质量比较差,由于多用于人声,通话,效果还是很不错的. 一.分类 1. AMR: ...
- C++入门到理解阶段二核心篇(1)——c++面向对象概述、内存分析、引用
1.c++内存分区模型 c++程序在运行的过程中,内存会被划分为以下四个分区 代码区:程序的所有程序的二进制代码,包括注释会被放到此区 全局区:存放静态变量.全局变量.常量(字符串常量和const修饰 ...
- elasticsearch cluster 概述
在源码概述中我们分析过,elasticsearch源码从功能上可以分为分布式功能和数据功能,接下来这几篇会就分布式功能展开.这里首先会对cluster作简单概述,然后对cluster所涉及的主要功能详 ...
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文主要讲述在standalone cluster部署模式下,Spark Application在整个运行期间,资源(主要是cpu core和内存)的申请与 ...
- 机器学习:线性判别式分析(LDA)
1.概述 线性判别式分析(Linear Discriminant Analysis),简称为LDA.也称为Fisher线性判别(Fisher Linear Discriminant,FLD) ...
随机推荐
- hdu 1024 最大m子段和
注:摘的老师写的 最大m子段和问题 以-1 4 -2 3 -2 3为例最大子段和是:6最大2子段和是:4+(3-2+3)=8所以,最大子段和和最大m子段和不一样,不能用比如先求一个最大子段和,从序列中 ...
- [Poi] Customize Babel to Build a React App with Poi
Developing React with Poi is as easy as adding the babel-preset-react-appto a .babelrc and installin ...
- orm 通用方法——QueryModelCount条件查询记录数
定义代码: /** * 描述:根据条件查询对象数 * 作者:Tianqi * 日期:2014-09-17 * param:model 对象实例 * param:cond 查询条件 * return:i ...
- Spring security工作流程及集成
A user enters their username and password into a login screen and clicks a login button. The entered ...
- React-router 4 总结
React-Router 4: BrowserRouter包裹整个应用 Router路由对应渲染的组件,可嵌套 Link跳转专用 首先 然后 其他组件: url参数 Route组建参数可用冒号标识参数 ...
- 【Henu ACM Round#17 C】Kitahara Haruki's Gift
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 判断sum/2这个价值能不能得到就可以了. 则就是一个01背包模型了. 判断某个价值能否得到. f[j]表示价值j能否得到. f[0 ...
- Eclipse+PyDev解决中文输入和注释问题
Eclipse的设置 window->preferences->general->editors->text editors->spelling->encoding ...
- [Python] Working with file
Python allows you to open a file, do operations on it, and automatically close it afterwards using w ...
- SelectSort
/**简单选择排序*/ #include<cstdio> #include<algorithm> using namespace std; int a[]={5,2,1,3,4 ...
- [c++]基类对象作为函数參数(赋值兼容规则)
编程处理教师的基本情况. 要求: 1.定义一个"person"类.用来存储及处理人的姓名.性别.年龄,成员函数自定: 2.定义"teacher"类,公有继承&q ...