Lucene学习总结之二:Lucene的总体架构 2014-06-25 14:12 622人阅读 评论(0) 收藏
Lucene总的来说是:
- 一个高效的,可扩展的,全文检索库。
- 全部用Java实现,无须配置。
- 仅支持纯文本文件的索引(Indexing)和搜索(Search)。
- 不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
在Lucene in action中,Lucene 的构架和过程如下图,
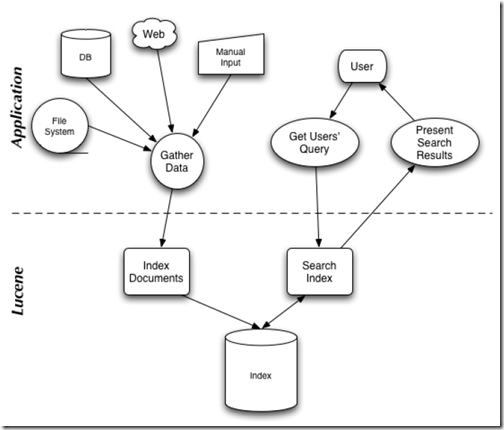
说明Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。
让我们更细一些看Lucene的各组件:
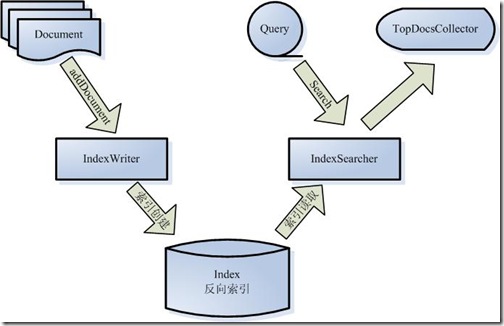
- 被索引的文档用Document对象 表示。
- IndexWriter 通过函数addDocument 将文档添加到索引中,实现创建索引的过程。
- Lucene 的索引是应用反向索引。
- 当用户有请求时,Query 代表用户的查询语句。
- IndexSearcher 通过函数search 搜索Lucene Index 。
- IndexSearcher 计算term weight 和score 并且将结果返回给用户。
- 返回给用户的文档集合用TopDocsCollector 表示。
那么如何应用这些组件呢?
让我们再详细到对Lucene API 的调用实现索引和搜索过程。
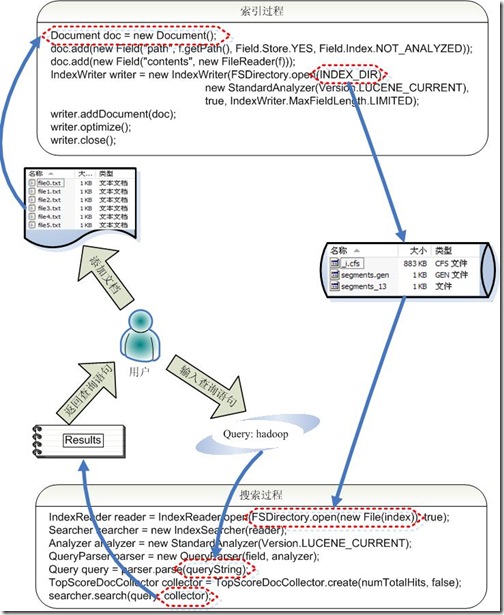
- 索引过程如下:
- 创建一个IndexWriter 用来写索引文件,它有几个参数,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用来对文档进行词法分析和语言处理的。
- 创建一个Document 代表我们要索引的文档。
- 将不同的Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field 来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader 的SRC_FILE 就表示要索引的源文件。
- IndexWriter 调用函数addDocument 将索引写到索引文件夹中。
- 搜索过程如下:
- IndexReader 将磁盘上的索引信息读入到内存,INDEX_DIR 就是索引文件存放的位置。
- 创建IndexSearcher 准备进行搜索。
- 创建Analyer 用来对查询语句进行词法分析和语言处理。
- 创建QueryParser 用来对查询语句进行语法分析。
- QueryParser 调用parser 进行语法分析,形成查询语法树,放到Query 中。
- IndexSearcher 调用search 对查询语法树Query 进行搜索,得到结果TopScoreDocCollector 。
以上便是Lucene API函数的简单调用。
然而当进入Lucene的源代码后,发现Lucene有很多包,关系错综复杂。
然而通过下图,我们不难发现,Lucene的各源码模块,都是对普通索引和搜索过程的一种实现。
此图是上一节介绍的全文检索的流程对应的Lucene实现的包结构。(参照http://www.lucene.com.cn/about.htm 中文章《开放源代码的全文检索引擎Lucene》)
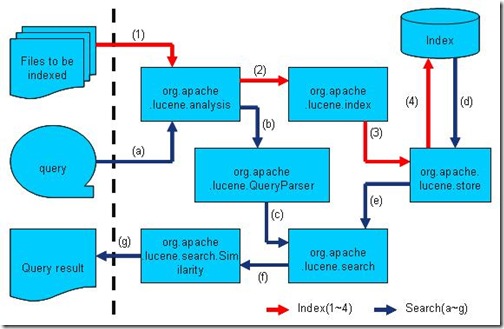
- Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term 。
- Lucene 的index 模块主要负责索引的创建,里面有IndexWriter 。
- Lucene 的store 模块主要负责索引的读写。
- Lucene 的QueryParser 主要负责语法分析。
- Lucene 的search 模块主要负责对索引的搜索。
- Lucene 的similarity 模块主要负责对相关性打分的实现。
Lucene学习总结之二:Lucene的总体架构 2014-06-25 14:12 622人阅读 评论(0) 收藏的更多相关文章
- Lucene学习总结之三:Lucene的索引文件格式(1) 2014-06-25 14:15 1124人阅读 评论(0) 收藏
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习总结之一:全文检索的基本原理 2014-06-25 14:11 666人阅读 评论(0) 收藏
一.总论 根据http://lucene.apache.org/java/docs/index.html 定义: Lucene 是一个高效的,基于Java 的全文检索库. 所以在了解Lucene之前要 ...
- Lucene学习总结之五:Lucene段合并(merge)过程分析 2014-06-25 14:20 537人阅读 评论(0) 收藏
一.段合并过程总论 IndexWriter中与段合并有关的成员变量有: HashSet<SegmentInfo> mergingSegments = new HashSet<Segm ...
- HDU 2042 不容易系列之二 [补6.24] 分类: ACM 2015-06-26 20:40 9人阅读 评论(0) 收藏
不容易系列之二 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- 团体程序设计天梯赛L3-010 是否完全二叉搜索树 2017-03-24 16:12 29人阅读 评论(0) 收藏
L3-010. 是否完全二叉搜索树 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 将一系列给定数字顺序插入一个初始为空的二叉搜 ...
- jdbc之二:DAO模式 分类: B1_JAVA 2014-04-29 15:13 1536人阅读 评论(0) 收藏
详细代码请参见 https://github.com/lujinhong/dao 一.前期准备 1.创建数据库 create database filter_conf; 2.创建表并插入数据 crea ...
- 使用Broadcast实现android组件之间的通信 分类: android 学习笔记 2015-07-09 14:16 110人阅读 评论(0) 收藏
android组件之间的通信有多种实现方式,Broadcast就是其中一种.在activity和fragment之间的通信,broadcast用的更多本文以一个activity为例. 效果如图: 布局 ...
随机推荐
- 使用 Bluemix™ Live Sync 高速更新 Bluemix 上执行的应用程序实例
假设您要构建 Node.js 应用程序,那么能够使用 IBM® Bluemix® Live Sync 高速更新 Bluemix 上的应用程序实例,并像在桌面上进行操作一样进行开发,而无需又一次部署.执 ...
- Android手机间使用socket进行文件互传实例
这是一个Android手机间文件传输的例子,两个手机同时装上此app,然后输入接收端的ip,选择文件,可以多选,点确定,就发送到另一个手机,一个简单快捷文件快传实例.可以直接运用到项目中. 下面是文件 ...
- python 新模块或者包的安装方法
主要介绍通过pip自动工具来安装需要的包. 1,先安装pip 下载pip的包(包括setup.py文件) cmd载入到pip本地文件所在路径,使用命令进行安装. python setup.py ins ...
- NVM安装nodejs的方法
安装nodejs方式有很多种. 第一种:官网下载 通过nodejs官网下载安装 ,但有个缺陷,不同版本的nodejs无法顺利的切换. 第二种: NVM安装 NVM可以帮助我们快速切换 node版本 ...
- vue踩坑记- Cannot find module 'wrappy'
找不到模块"包装" 当你维护别人的项目代码的时候,在自己这里电脑上运行,打开一个项目cnpm run dev的时候,报错如下 Cannot find module 'wrappy' ...
- GIT,SVN,CVS的区别比较
Git .CVS.SVN比较 项目源代码的版本管理工具中,比较常用的主要有:CVS.SVN.Git 和 Mercurial (其中,关于SVN,请参见博客:SVN常用命令 和 SVN服务器配置) 目 ...
- Vue 使用use、prototype自定义自己的全局组件
使用Vue.use()写一个自己的全局组件. 目录如下: 然后在Loading.vue里面定义自己的组件模板 <template> <div v-if="loadFlag& ...
- 注意knn与kmeans的区别
开始的时候,我居然弄混了. knn是分类方法,是通过新加入的节点最接近的N个节点的属性,来判定新的节点. kmeans是聚类方法,是先选择k个点作为k个簇的中点,然后分簇之后重新划定中心点,然后再分簇 ...
- 下次自己主动登录(记住password)功能
1:进入cookie插件 <script src="jquery.cookie.js" type="text/javascript"></sc ...
- NYOJ 552 小数阶乘
小数阶乘 时间限制:1000 ms | 内存限制:65535 KB 难度:1 描写叙述 编写一个程序,求一个数m的阶乘. 输入 有多组測试数据,以EOF结束. 每组測试数据有1个整数m. 输出 每 ...