HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了。
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。

hbase(main):020:0> desc 'test_table'
Table test_table is ENABLED
test_table
COLUMN FAMILIES DESCRIPTION
{NAME => 'f', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS
=> 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
1 row(s) in 0.2190 seconds
hbase(main):021:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.2270 seconds
hbase(main):022:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.1480 seconds
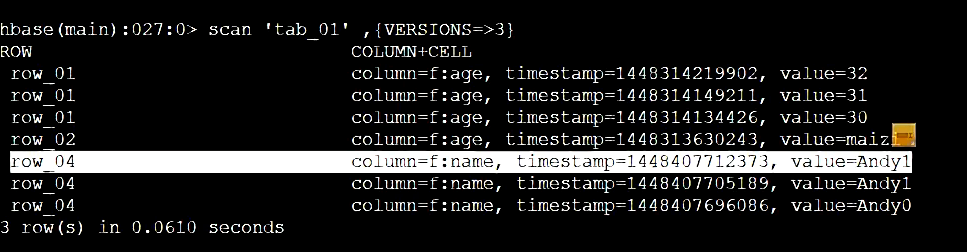
hbase(main):023:0> scan 'test_table',{VERSIONS=>3}
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.1670 seconds
hbase(main):024:0>
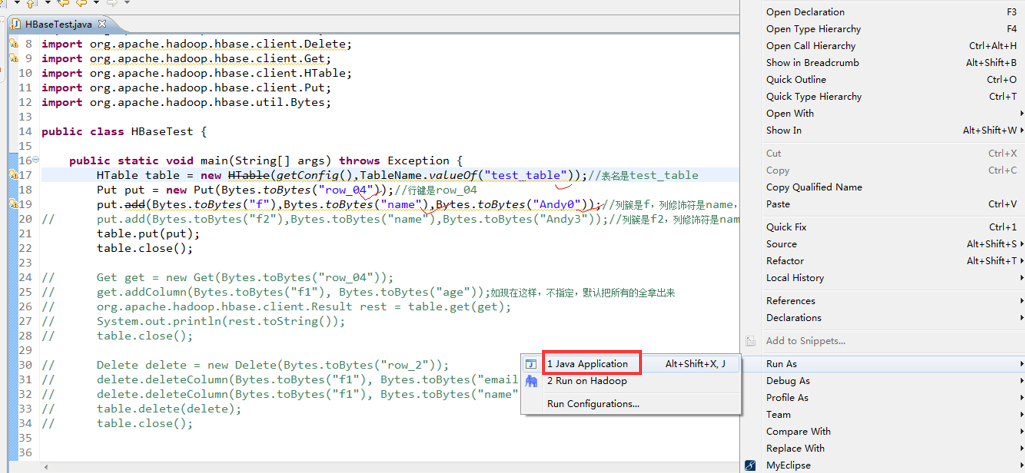
package zhouls.bigdata.HbaseProject.Test1; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest {
public static void main(String[] args) throws Exception {
HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
table.put(put);
table.close(); // Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
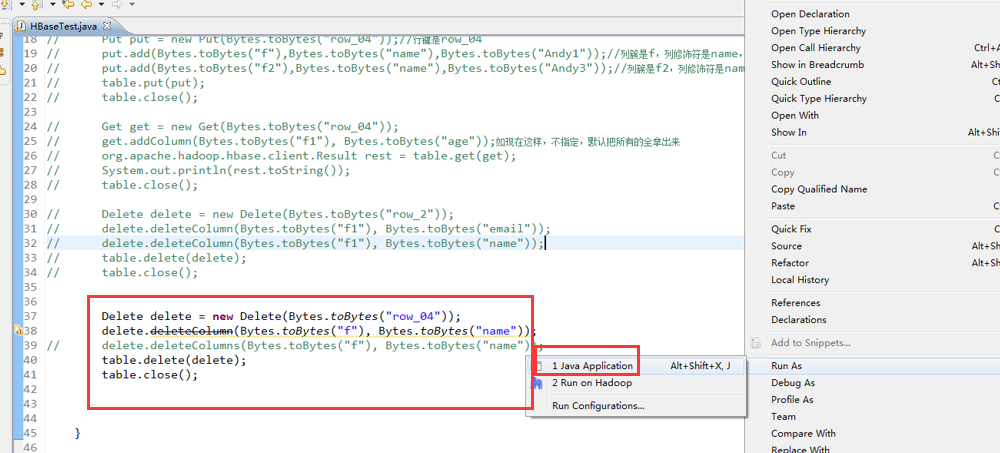
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_03"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
} public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
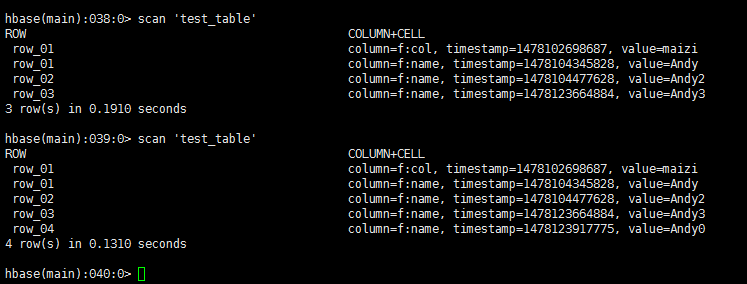
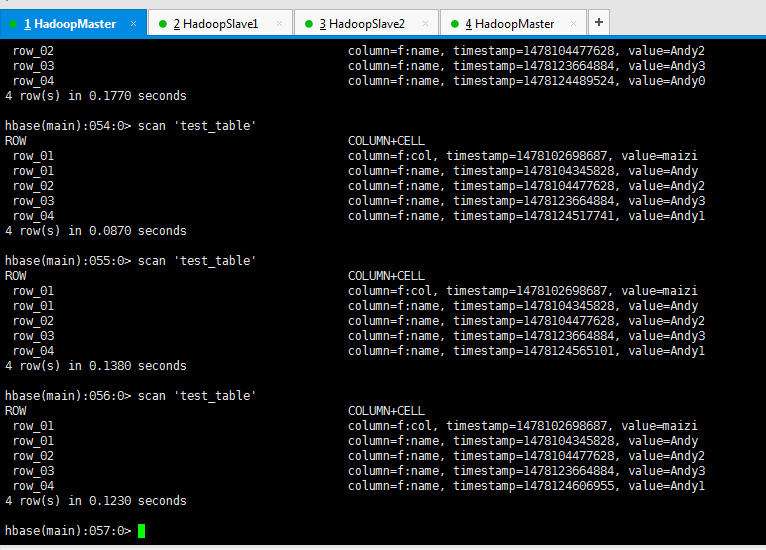
hbase(main):038:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478123664884, value=Andy3
3 row(s) in 0.1910 seconds
hbase(main):039:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478123664884, value=Andy3
row_04 column=f:name, timestamp=1478123917775, value=Andy0
4 row(s) in 0.1310 seconds
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。
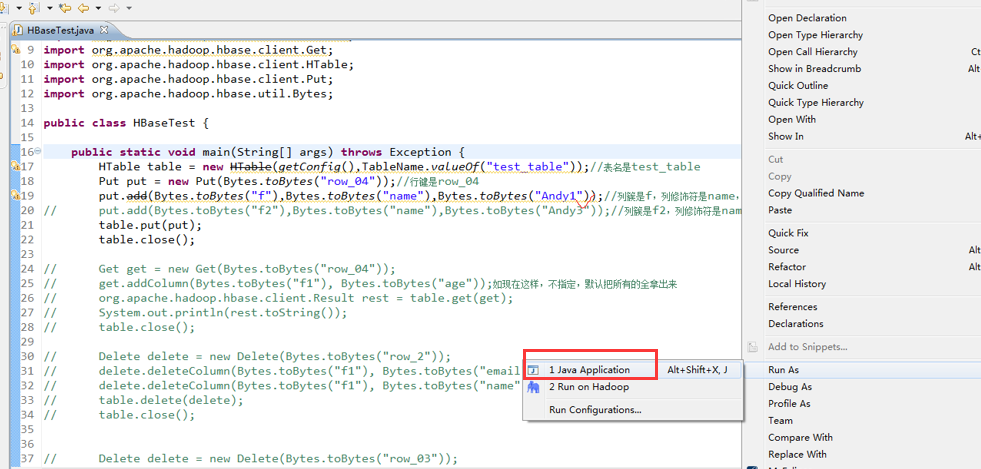
package zhouls.bigdata.HbaseProject.Test1; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest {
public static void main(String[] args) throws Exception {
HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
table.put(put);
table.close(); // Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_03"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
} public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
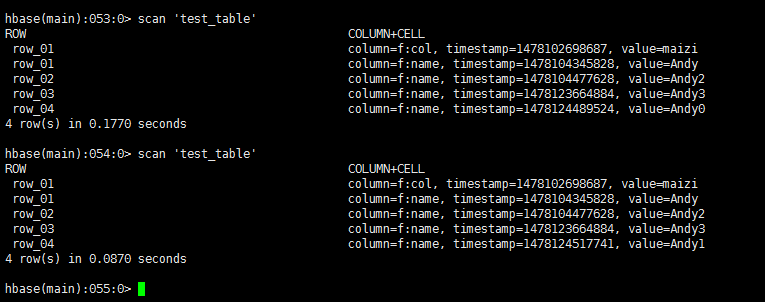


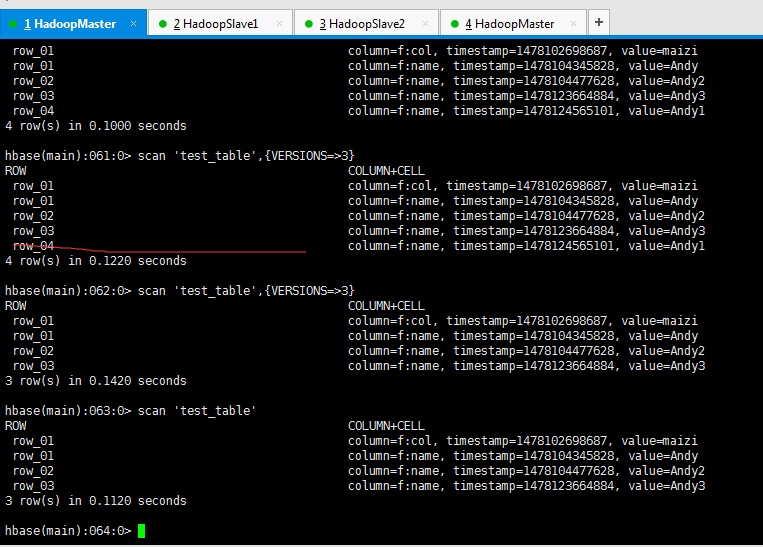
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。


HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)的更多相关文章
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
- HBase编程 API入门系列之modify(管理端而言)(10)
这里,我带领大家,学习更高级的,因为,在开发中,尽量不能去服务器上修改表. 所以,在管理端来修改HBase表.采用线程池的方式(也是生产开发里首推的) package zhouls.bigdata.H ...
- HBase编程 API入门系列之scan(客户端而言)(5)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. package zhouls.bigdata.HbaseProject.Test1; import javax.xml.trans ...
- HBase编程 API入门系列之工具Bytes类(7)
这是从程度开发层面来说,为了方便和提高开发人员. 这个工具Bytes类,有很多很多方法,帮助我们HBase编程开发人员,提高开发. 这里,我只赘述,很常用的! package zhouls.bigda ...
- HBase编程 API入门系列之put(客户端而言)(1)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. [hadoop@HadoopSlave1 conf]$ cat regionservers HadoopMasterHadoopS ...
随机推荐
- [Advanced Algorithm] - Exact Change
题目 设计一个收银程序 checkCashRegister(),其把购买价格(price)作为第一个参数 , 付款金额 (cash)作为第二个参数, 和收银机中零钱 (cid) 作为第三个参数. ci ...
- SQL基本概述
DBMS的种类: 层次数据库HDB 面向对象数据库OODB XML数据库XMLDB 键值存储系统KVS 关系数据库RDB RDBMS(关系数据库管理系统),主要5有种: Oracle Database ...
- webpack核心提炼
基本是学习的时候在网上整理的资料,并非自己原创,这篇文章的的主要目的是记录webpack.config.js的配置方式.可能也有不少错误,欢迎指正!! 一.应用场景 前端模块化开发.功能拓展.css预 ...
- vue 强制刷新组件
<component v-if="hackReset"></component> 2 3 4 this.hackReset = false this.$ne ...
- eas之指定虚模式
KDTable支持三种取数模式:实模式.虚模式分页.虚模式分组,默认为实模式.// 实模式table.getDataRequestManager().setDataRequestMode(KDTDat ...
- Python之CSV模块
1. CSV简介 CSV(Comma Separated Values)是逗号分隔符文本格式,常用于Excel和数据库的导入和导出,Python标准库的CSV模块提供了读取和写入CSV格式文件的对象. ...
- node源码详解(四)
本作品采用知识共享署名 4.0 国际许可协议进行许可.转载保留声明头部与原文链接https://luzeshu.com/blog/nodesource4 本博客同步在https://cnodejs.o ...
- 使用pm2启动nodejs+express+mysql管理系统步骤
背景: 由于个人兴趣,了解了一下nodejs+express+mysql项目.在项目搭建完成并开发完成并部署时,遇到一个尴尬的问题,就是后台的servive服务启动问题.日常开发时,打开2个cm窗口, ...
- centos 7.2 安装php56-xml
linux下, 使用thinkphp的模板标签,如 eq, gt, volist defined, present , empty等 标签时, 报错: used undefined function ...
- Spring MVC灵活控制返回json的值(自定义过滤字段)
在使用spring MVC开发过程中,为了提高项目执行效率,所以在一些外键字段的实体中会注解”@ManyToOne(fetch = FetchType.LAZY)”以实现延迟加载的效果. 但是,在使用 ...