python大杂铺
python中continue,break,return三者之间的区别
return 会直接令函数返回,所有该函数体内的代码都不再执行了,所以该函数体内的循环也不可能再继续运行。
break:跳出所在的当前整个循环,到外层代码继续执行。
continue:跳出本次循环,从下一个迭代继续运行循环,内层循环执行完毕,外层代码继续运行。
import time
while True:
time.sleep(0.5) #可简单理解为程序休止一秒
print("执行了")
continue # 结束本次循环,进行下次循环
print("没有执行")#不会执行
continue
def say_hello():
print("No Hello!")
return #可以加返回值
print("Can not say hello") #不会执行 say_hello()
return
while True:
print("执行了")
break # 跳出当前循环
print("没有执行") #不会执行
print("OVER!!!")
break
深浅copy:
1.copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。
dic1 = {
'k1': 'v1',
'k2': [11]
}
dic2 = dic1.copy()
print(dic1,dic2)
print("********区分线********")
dic1['k2'].append(66)
print(dic1,dic2)
输出:
可看到,浅拷贝后再次对原数据(dic1)更改时,新的数据也会发生更改(dic2会随之更改)
2. copy.deepcopy() 深拷贝,拷贝对象及其子孙对象
dic1 = {
'k1': 'v1',
'k2': [11,22,33,44]
}
import copy
dic2 = copy.deepcopy(dic1)
print(dic1,dic2)
dic1['k2'].append(666)
print(dic1,dic2)
深copy时,dic1有两层对象,可以理解为父对象和子孙对象;一层是'k1'(key1): 'v1'(value1),'k2'(key2):[11,22,33,44] (value2),而value2又是一层对象(子对象)
输出:
总结:
deepcopy : 即深拷贝,与我们寻常理解的拷贝的意义相同,拷贝原数据,形成新的相同数据,并且两份数据保持独立,没有关联关系。
copy: 即浅拷贝,拷贝原数据,实际上是给原数据贴上新的标签,都是指向同一对象。既然两个数据是指向相同对象,当其中一个数据做出修改,另一个数据也随之改变。
参考:https://www.cnblogs.com/wujiaqing/p/11024382.html
enumerate函数
描述:
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
同时列出数据和数据下标,一般用在 for 循环当中。
语法:
enumerate(sequence, [start=0])
sequence :一个序列、迭代器或其他支持迭代对象。
start :下标起始位置。
实例:
# _*_coding:utf-8_*_
'''
需求a = [1,2,3,4,5,6,7,8,9],把列表中的值加一 方法? '''
#方法: # 方法1:
'''
a = [1,2,3,4,5,6,7,8,9]
b = []
for i in a:
b.append(i+1)
a = b
print(a)
''' #方法2:
'''
a = [1,2,3,4,5,6,7,8,9]
b =map(lambda x:x+1,a)
for i in b:
print(i) '''
#方法3:
'''
a = [1,2,3,4,5,6,7,8,9]
for index,value in enumerate(a):
a[index] += 1
# print(i,index)
print(a) '''
#方法4:
'''
a = [1,2,3,4,5,6,7,8,9]
a = [i+1 for i in a]
print(a) '''
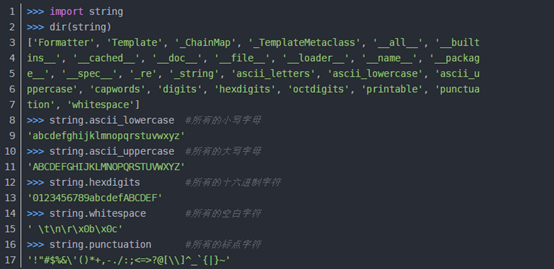
去掉string(英文状态)的标点符号

python大杂铺的更多相关文章
- Python 10 —— 杂
Python 10 —— 杂 科学计算 NumPy:数组,数组函数,傅里叶变换 SciPy:依赖于NumPy,提供更多工具,比如绘图 绘图 Matplitlib:依赖于NumPy和Tkinter
- python大数据工作流程
本文作者:hhh5460 大数据分析,内存不够用怎么办? 当然,你可以升级你的电脑为超级电脑. 另外,你也可以采用硬盘操作. 本文示范了硬盘操作的一种可能的方式. 本文基于:win10(64) + p ...
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
- 《零起点,python大数据与量化交易》
<零起点,python大数据与量化交易>,这应该是国内第一部,关于python量化交易的书籍. 有出版社约稿,写本量化交易与大数据的书籍,因为好几年没写书了,再加上近期"前海智库 ...
- python大文件读取
python大文件读取 https://stackoverflow.com/questions/8009882/how-to-read-a-large-file-line-by-line-in-pyt ...
- 学习推荐《零起点Python大数据与量化交易》中文PDF+源代码
学习量化交易推荐学习国内关于Python大数据与量化交易的原创图书<零起点Python大数据与量化交易>. 配合zwPython开发平台和zwQuant开源量化软件学习,是一套完整的大数据 ...
- 零起点Python大数据与量化交易
零起点Python大数据与量化交易 第1章 从故事开始学量化 1 1.1 亿万富翁的“神奇公式” 2 1.1.1 案例1-1:亿万富翁的“神奇公式” 2 1.1.2 案例分析:Python图表 5 1 ...
- Python大数据与机器学习之NumPy初体验
本文是Python大数据与机器学习系列文章中的第6篇,将介绍学习Python大数据与机器学习所必须的NumPy库. 通过本文系列文章您将能够学到的知识如下: 应用Python进行大数据与机器学习 应用 ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
随机推荐
- (转)Arcgis for JS之Cluster聚类分析的实现
http://blog.csdn.net/gisshixisheng/article/details/40711075 在做项目的时候,碰见了这样一个问题:给地图上标注点对象,数据是从数据库来的,包含 ...
- HDU_1698_Just a Hook_线段树区间更新
Just a Hook Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- 怎么用最短时间高效而踏实地学习Python?
之所以写这篇文章,在标题里已经表达得很清楚了.做技术的人都知道,时间就是金钱不是一句空话,同一个技术,你比别人早学会半年,那你就能比别人多拿半年的钱.所以有时候别人去培训我也不怎么拦着,为什么?因为培 ...
- Oracle数据库的自动备份脚本
@echo off echo ================================================ echo Windows环境下Oracle数据库的自动备份脚本 echo ...
- uva 12108 Extraordinarily Tired Students (UVA - 12108)
算法完全转载...原博客(https://blog.csdn.net/u014800748/article/details/38407087) 题目简单叙述 题目就是一堆学生他们有清醒的时候和昏迷的时 ...
- 7 numpy 傅里叶,提取图片轮廓
任务:提取照片中轮廓 本次处理图片:我的女神之一 江一燕 导入模块: #jyy.show() 会打开本地图片浏览器 使用傅里叶反转 获取实部,舍弃虚部 去除小数部分 将一维数 ...
- mysql-索引、导入、导出、备份、恢复
1.索引 索引是一种与表有关的结构,它的作用相当于书的目录,可以根据目录中的页码快速找到所需的内容. 当表中有大量记录时,若要对表进行查询,没有索引的情况是全表搜索:将所有记录一一取出,和查询条件进行 ...
- 【LeetCode Weekly Contest 26 Q3】Friend Circles
[题目链接]:https://leetcode.com/contest/leetcode-weekly-contest-26/problems/friend-circles/ [题意] 告诉你任意两个 ...
- 史上最全opencv源代码解读,opencv源代码具体解读文件夹
本博原创,如有转载请注明本博网址http://blog.csdn.net/ding977921830/article/details/46799043. opencv源代码主要是基于adaboost算 ...
- [字典树] poj 2418 Hardwood Species
题目链接: id=2418">http://poj.org/problem?id=2418 Hardwood Species Time Limit: 10000MS Memory ...