python数据分析处理库-Pandas
1、读取数据
import pandas
food_info = pandas.read_csv("food_info.csv")
print(type(food_info)) # <class 'pandas.core.frame.DataFrame'>
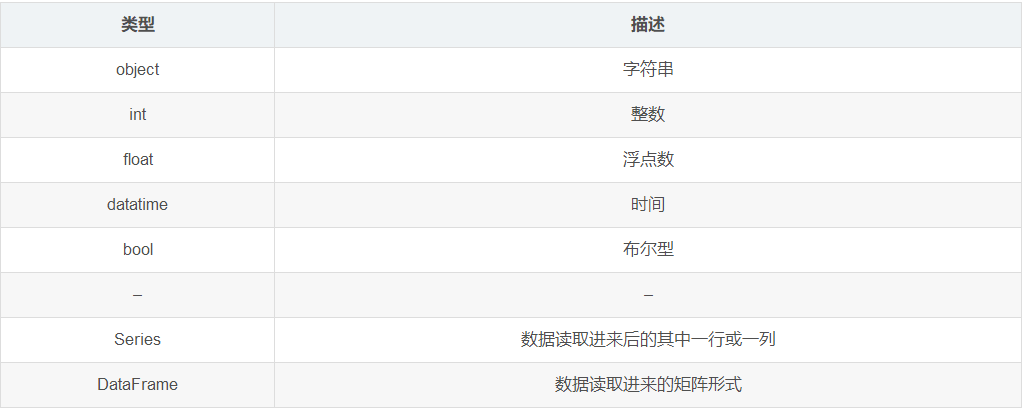
2、数据类型
3、数据显示
food_info.head() # 显示读取数据的前5行
food_info.head(3) # 显示读取数据的前3行
food_info.tail(3) # 显示读取数据的后3行
food_info.columns # 列名
food_indo.shape # 数据规格
food_info.loc[0] # 第0行数据
food_info.loc[3:6] # 第3-6行数据
food_info.log[83,"NDB_No"] # 读取第83行的NDB_No数据
food_info["NDB_No"] # 通过列名读取列
columns = ["Zinc_(mg)", "Copper_(mg)"]
food_info[columns] # 读取多个列 # 读取单位为g的列
col_names = food_info.columns.tolist() # 列名
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food_info[gram_columns]
4、数据操作
# 对该列每一个值都除以1000,+-*同理
food_info["Iron_(mg)"] / 1000
# 维度相同的列对应元素相乘
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
# 添加新的一列
iron_grams = food_info["Iron_(mg)"] / 1000
food_info["Iron_(g)"] = iron_grams
# 最大值
food_info["Energ_Kcal"].max()
# 排序 inplace-是否新生成一个DataFrame ascending-默认为True
food_info.sort_values("Sodium_(mg)", inplace=True, ascending=False)
# 将排序后的数据的索引值重置,生成新的索引
new_titanic_survival = titanic_survival.sort_values("Age",ascending=False)
new_titanic_survival.reset_index(drop=True)
5、缺失值处理
# 缺失值
pd.isnull(age)
titanic_survival["Age"].mean() # 去掉缺失值后的平均值 #去掉含有缺失值的数据
titanic_survival.dropna(axis=1) # 丢掉含有缺失值的列
titanic_survival.dropna(axis=0,subset=["Age", "Sex"]) # 丢掉"Age"与"Sex"中含有缺失值的行
6、简单的统计函数
# 统计在不同船舱中获救人数的平均值 aggfunc-默认为求均值
passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean)
7、自定义函数
# 返回行值
def hundredth_row(column):
# Extract the hundredth item
hundredth_item = column.loc[99]
return hundredth_item
hundredth_row = titanic_survival.apply(hundredth_row) # 置换列值
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second Class"
elif pclass == 3:
return "Third Class"
classes = titanic_survival.apply(which_class, axis=1)
8、Series结构
from pandas import Series
series_custom = Series(rt_scores , index=film_names)
series_custom[['Minions (2015)', 'Leviathan (2014)']]
python数据分析处理库-Pandas的更多相关文章
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- python科学计算库-pandas
------------恢复内容开始------------ 1.基本概念 在数据分析工作中,Pandas 的使用频率是很高的, 一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 ...
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- 浅谈python的第三方库——pandas(一)
pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas. 1 pandas数据结构 1.1 Series 注:由于pand ...
- Python数据分析扩展库
Anaconda和Python(x,y)都自带了下面的这些库. 1. NumPy 强大的ndarray和ufunc函数. import numpy as np xArray = np.ones((3, ...
- Python 数据分析包:pandas 基础
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- 快速学习 Python 数据分析包 之 pandas
最近在看时间序列分析的一些东西,中间普遍用到一个叫pandas的包,因此单独拿出时间来进行学习. 参见 pandas 官方文档 http://pandas.pydata.org/pandas-docs ...
随机推荐
- 微信小程序初始化 operateWXData:fail invalid scope
初学者开发微信小程序,可以使用云开发来进行微信小程序的开发. 第一次使用开发工具遇到的问题 解决方案:1.找到云开发 2.点击开通,选择合适自己的开发环境: 3.完成后,返回开发工具界面点击项目第一个 ...
- 微信JSSDK与录音相关的坑
微信JSSDK与录音相关的坑 最近一直在做微信JSSDK与录音相关的功能开发, 遇到了各种奇尺大坑, 时不时冷不丁地被坑一道, 让我时常想嘶吼: "微信JSSDK就是个大腊鸡!!!!!!!! ...
- 中间人攻击-MITM攻击
中间人攻击(Man-in-the-MiddleAttack,简称“MITM攻击”)是一种“间接”的入侵攻击,这种攻击模式是通过各种技术手段将受入侵者控制的一台计算机虚拟放置在网络连接中的两台通信计算机 ...
- JavaScript-2.内置对象---简单脚本之弹出对话框显示当前时间 ---ShinePans
<html> <head> <meta http-equiv="content-type" content="text/html; char ...
- BZOJ3611:[HEOI2014]大工程(树形DP,虚树)
Description 国家有一个大工程,要给一个非常大的交通网络里建一些新的通道. 我们这个国家位置非常特殊,可以看成是一个单位边权的树,城市位于顶点上. 在 2 个国家 a,b 之间建一条新通 ...
- Sequelize-nodejs-1-getting started
Sequelize is a promise-based ORM for Node.js v4 and up. It supports the dialects PostgreSQL, MySQL, ...
- 简单说说Vue
Vue.js是这次我们公司迭代项目使用的前端框架之一.我们前端使用的是一个叫Metronic的.Metronic的可以说是bootstrap系列的集合. 当然也用到一个叫layui的,layui的话就 ...
- pl/sql连接远程oracle
1.找到oracle安装程序下的网络配置助手 2.选中本地net服务,进行添加 3.输入远程oracle服务名 4.选中tcp协议 5.输入远程oracle的ip地址 6.在网络服务名处,随便输入一个 ...
- java多态成员的特点
父类: package com.company; public class A { ; public void ok(){ System.out.println("i am father!& ...
- ajax表单提交post(错误400) 序列化表单(post表单转换json(序列化))
序列化表单 使用serializeArray()序列化 转换成json格式 function arrayTOjson(node) { var b = "{"; for (var i ...